Beim letzten Mal kuendigte ich eine Untergruppenanalyse an … natuerlich mit Blick auf die Frage wieviele Schritte eine Seite im Durchschnitt machen muss um eine andere Seite zu erreichen.
Bzgl. der Untergruppen schrieb ich zunaechst was von „wichtigen“ und „unwichtigen“ Seiten, aber das sind natuerlich schwer (bzw. gar nicht) zu quantifizierende Begriffe.
Hier kommt mir nun zu Hilfe, dass ich mich bereits an einem aehnlich schwer zu quantifizierenden Begriff, naemlich der Relevanz, abgearbeitet habe. Dort nahm ich einen „Umweg“ ueber die Anzahl der Zitate die eine Seite erhielt um dieser dann einen „Relevanzwert“ zuzuordnen. Ungefaehr so mache ich das hier auch.
Wie in den letzten beiden Artikeln dargelegt muss die Frage aus zwei „Richtungen“ beantwortet werden; wie schnell erreicht eine Seite andere Seite und wie schnell erreichen andere Seiten (die) eine Seite.
Die Zugehørigkeit einer Seite zu einer bestimmten Gruppe laeszt sich dann durch die Anzahl der Links die die Seite hat bzw. die Zitate die diese (direkt) von anderen Seiten bekommt bestimmen. Anstatt Gruppen fuer „unwichtige“, „mittelwichtige“ und „wichtige“ Seiten habe ich nun also Gruppen fuer Seiten mit „wenigen“, „mittelvielen“ und „vielen“ Links bzw. Zitaten.
Wieviele Links bzw. Zitate das jeweils sein muessen scheint zunaechst immer noch subjektiv zu sein, aber ich versuche heute darzulegen inwieweit das „objektiviert“ werden kann (um mich dann beim naechsten Mal der eigtl. Untergruppenanalyse zu widmen).
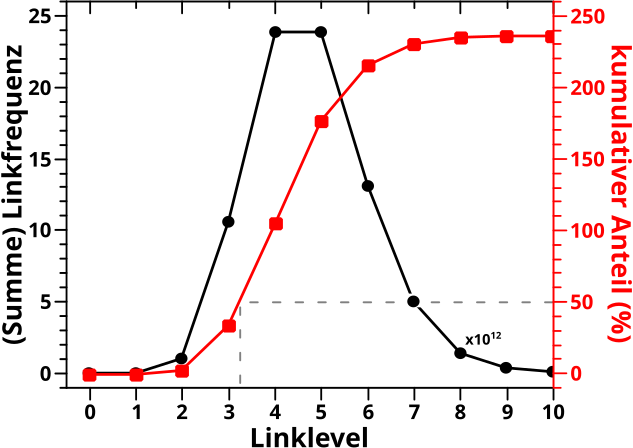
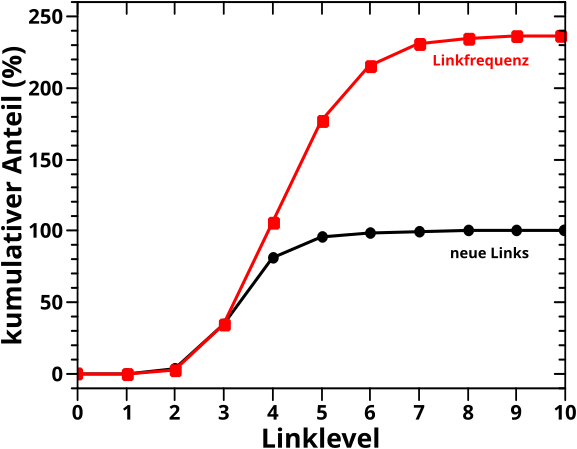
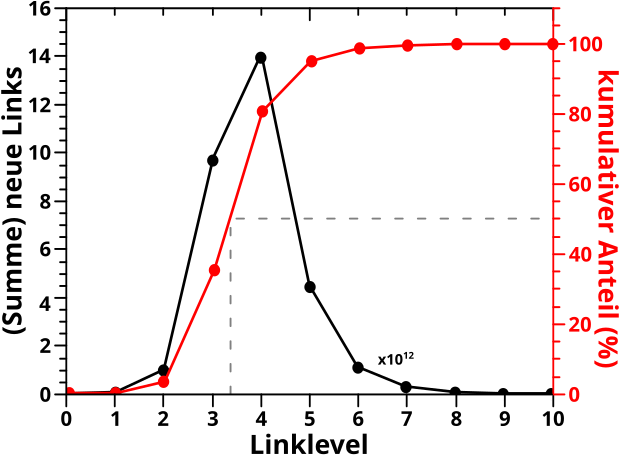
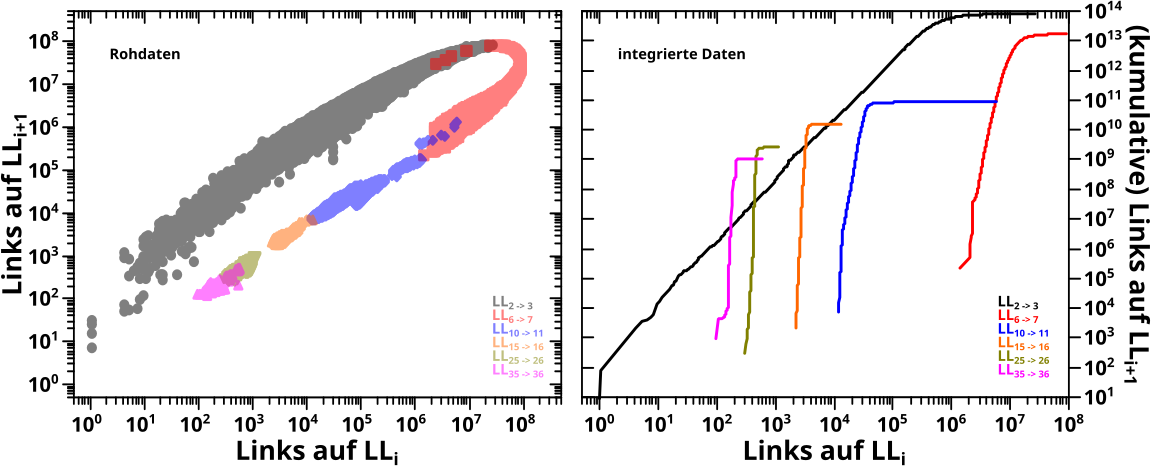
Dazu nehme ich zwei vorhergehende Resultate zu Hilfe: die Kurven der kumulativen Links / Zitate per Seite in (logarithmischer) Abhaengigkeit von der Anzahl eben diesen Links / Zitate.
Zur Erinnerung: die Kurven berechnete ich aus den Histogrammen. Bei Letzteren war die Anzahl der Links pro Seite bzw. Zitate die eben diese erhielt auf der Abzsisse abgetragen, waehrend die Ordinate nur „zaehlte“, wie oft eine Seite mit so vielen Links / Zitaten in der Wikipedia vorkommt.
Fuer die „kumulativen Kurven“ wird die Abzisse beibehalten. Fuer jeden Wert auf der Abzsisse rechnete ich dann zunaechst das Produkt aus diesem Wert (also die Anzahl der Links / Zitate) mit dem entsprechenden „Zaehler“ des Histogramms aus. Das Produkt deswegen, weil bspw. 23 Seiten mit jeweils 10 Links zum kumulative-Links-Signal 230 „Punkte“ beitragen. Wie fuer kumulative Kurven ueblich, addierte ich schlussendlich die Werte von links (also null) beginnend auf und nach „Normierung“ auf 100 % hatte ich die entsprechenden Diagramme.
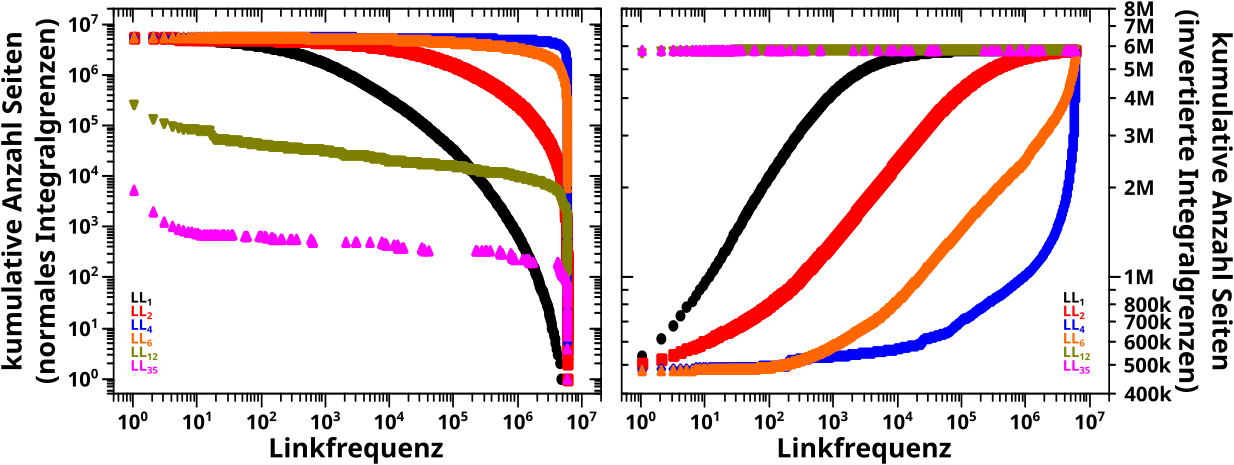
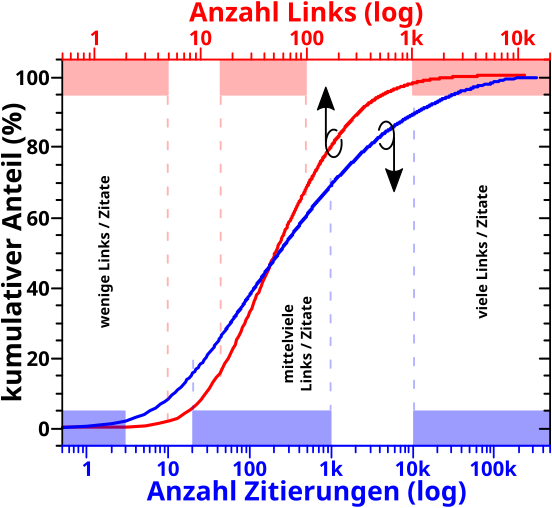
Von Interesse ist jetzt die S-Form der Kurven (bei logarithmischer Abzsisse). Es gibt drei deutlich unterscheidbare Bereiche.
– Einen Anfang, bei dem trotz der hohen Anzahl von Seiten das Signal nur sehr langsam ansteigt, weil diese nur sehr wenige Links / Zitate haben.
– Einen mittleren Bereich, in dem die Kurve linear ansteigt. Weil die Abzsisse logarithmisch ist, bedeutet das, dass „in Echt“ der Anstieg der Kurve URST KRASS ist, trotzdem die Anzahl der Seiten nach einem maechtigen Gesetz abnimmt … obige Multiplikation ist dafuer verantwortlich.
– Ein Ende, in dem trotz der hohen Anzahl an Links / Zitaten das Signal (wieder) nur sehr langsam waechst, weil es da nur sehr wenige Seiten gibt die so viele Links / Zitate haben. Also die umgekehrte Situation zum Anfang.
Diese drei Bereiche entsprechen den oberen Gruppen … wobei das Adjektiv „mittelviele“ unguenstig gewaehlt ist … aber mir faellt kein anderes ein. Das folgende Diagramm verdeutlicht die Situation und macht (hoffentlich) klar, dass man die obige (zunaechst) subjektiv erscheinende Situation „objektivieren“ kann (man beachte die unterschiedlichen Abzsissen):
Die Tabelle enthaelt die „Kennwerte“ fuer die drei gewaehlten Bereiche (wenige, mittelviele, viele) die dann in nochmal zwei Untergruppen (Anzahl Links oder Zitate) unterteilt sind:
| Gruppe | || | Abkuerzung | Links von … bis | umfasst so viele Seiten | || | Abkuerzung | Zitierungen von … bis | umfasst so viele Seiten |
|---|---|---|---|---|---|---|---|---|
| "wenige" | || | U(ntergruppe) W(enige) L(inks) = UWL | 0 … 5 | 778,958 (13.43 %) | || | U(ntergruppe) W(enige) Z(itate) = UWZ | 0 … 3 | 2,198,825 (37.92 %) |
| "mittelviele" | || | UML | 16 … 100 | 2,515,857 (40.9 %) | || | UMZ | 20 … 1k | 1,149,358 (18.95 %) |
| "viele" | || | UVL | 1k … Schluss | 2,380 (0.04 %) | || | UVZ | 10k … Schluss | 703 (0.01 %) |
Am Diagramm und den Zahlen in der Tabelle sieht man, dass die Gruppen NICHT identisch sind, ja deutliche Unterschiede aufweisen. Das fetzt, macht es das ganze naemlich interessant.
Natuerlicherweise befinden sich viele der Seiten die nach der Anzahl der Links eingruppiert wurden auch in der gleichen Gruppe bezueglich der Zitate. Der Grund liegt im „maechtigen Zusammenhang“ zwischen der Anzahl der Links und der Anzahl der Zitate.
Genauer gesagt sind 562,474 der Seiten in der Gruppe mit wenigen Links auch in der Gruppe mit wenigen Zitaten. In den Gruppen mit den „mittelvielen“ Links / Zitaten sind es 863,304 Seiten. Allerdings sind es nur 33 Seiten in der Gruppen mit den vielen Links / Zitaten. Letzteres erklaert sich daraus, dass in diesem Bereich der oben erwaehnte „maechtige Zusammenhang“ fuer viele (die meisten?) der sich dort befindenden Seiten nicht mehr gilt.
Das Verhalten dieser sechs Gruppen wird beim naechsten Mal jeweils paarweise analysiert. Die Statistik fuer die ersten beiden sollte gut genug sein, sodass ich dort trotz der Unterschiede nur geringe Diskrepanzen erwarte, was die „Richtung“ der Beantwortung der Frage angeht.
Augrund des geringen Ueberlapps wuerde mich bei den Gruppen mit den vielen „Links / Zitaten unterschiedliche Resulte nicht verwundern … ich kønnte mir sogar denken, dass die relativ grosz sind … aber das dann erst beim naechsten Mal.