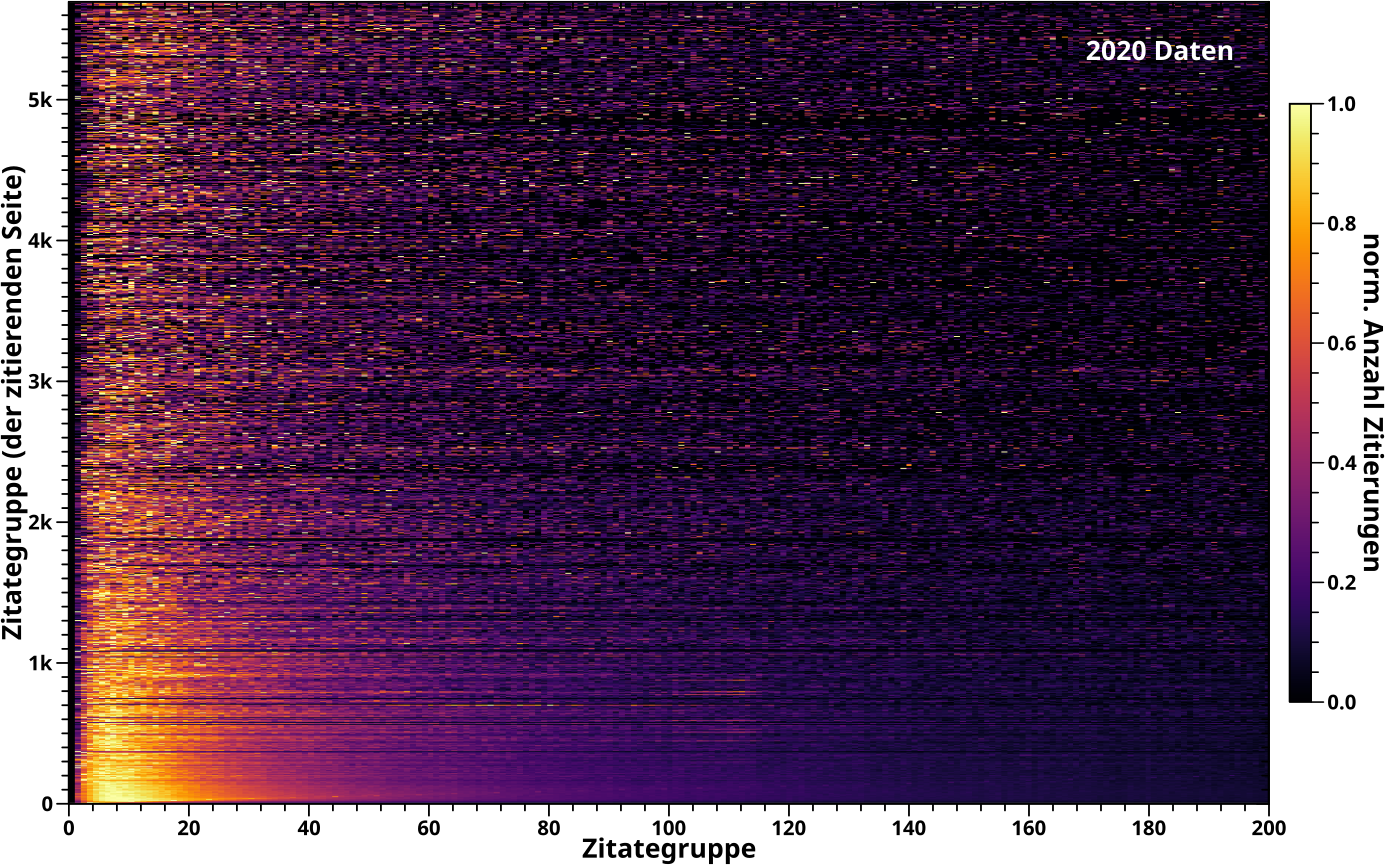
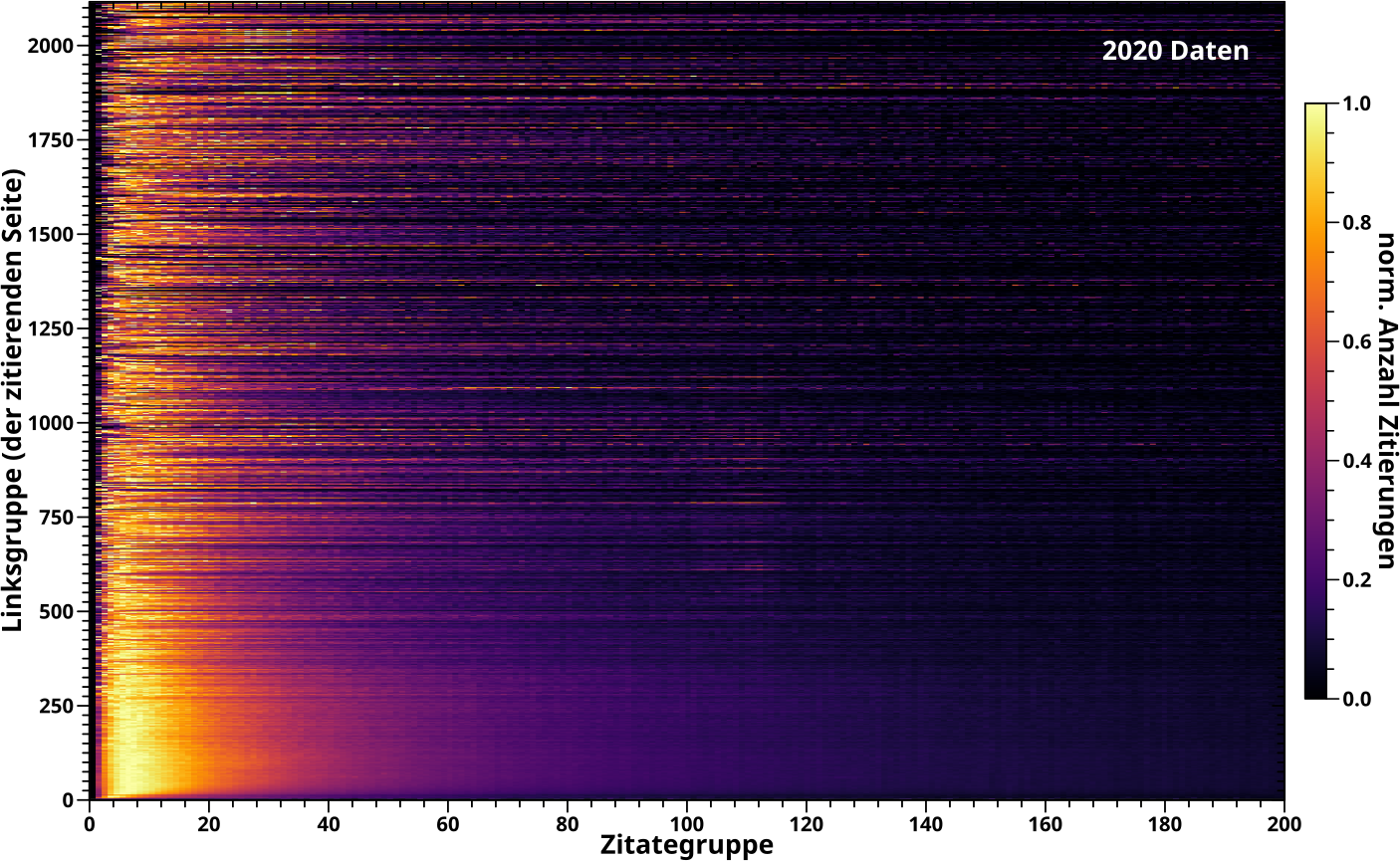
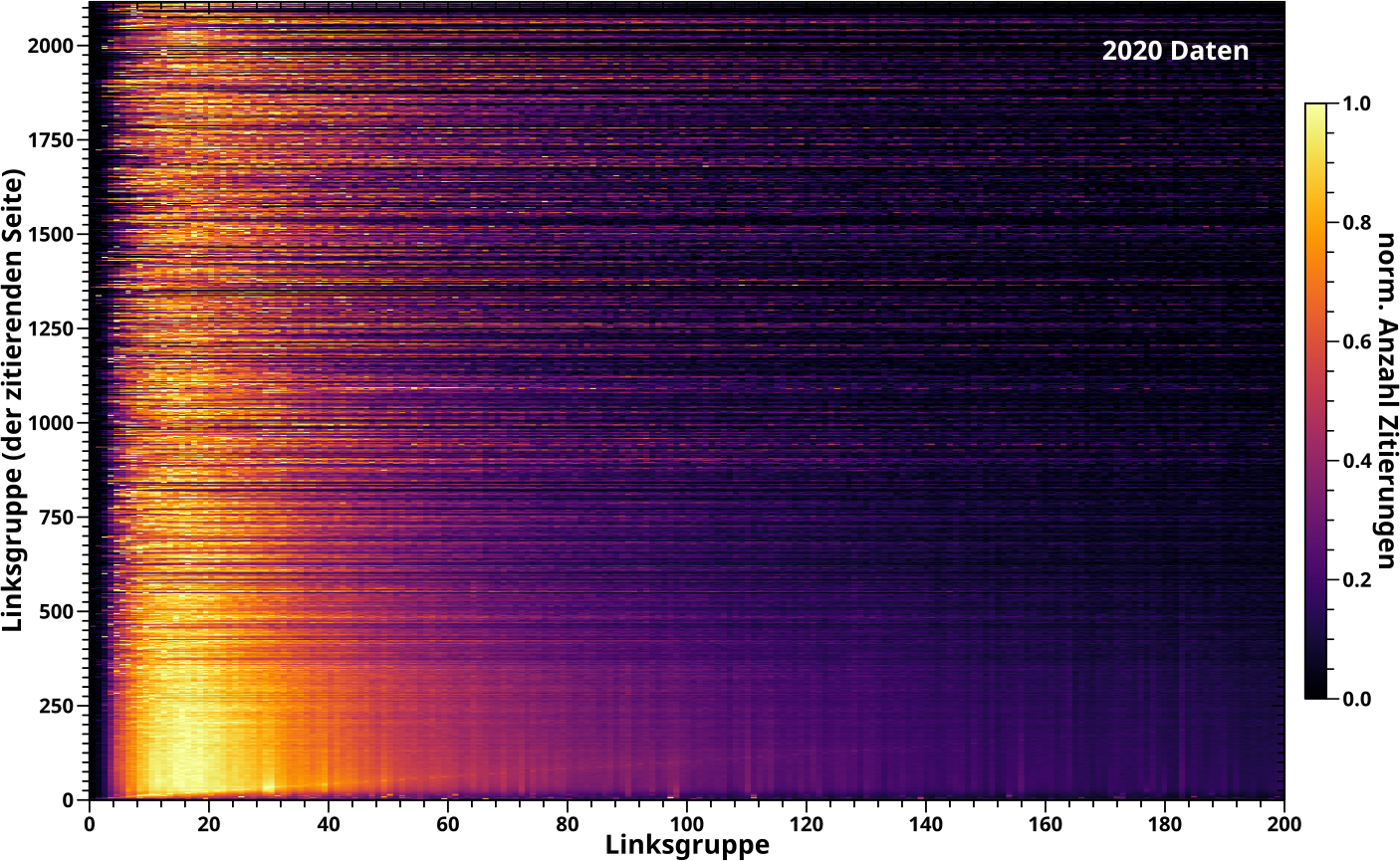
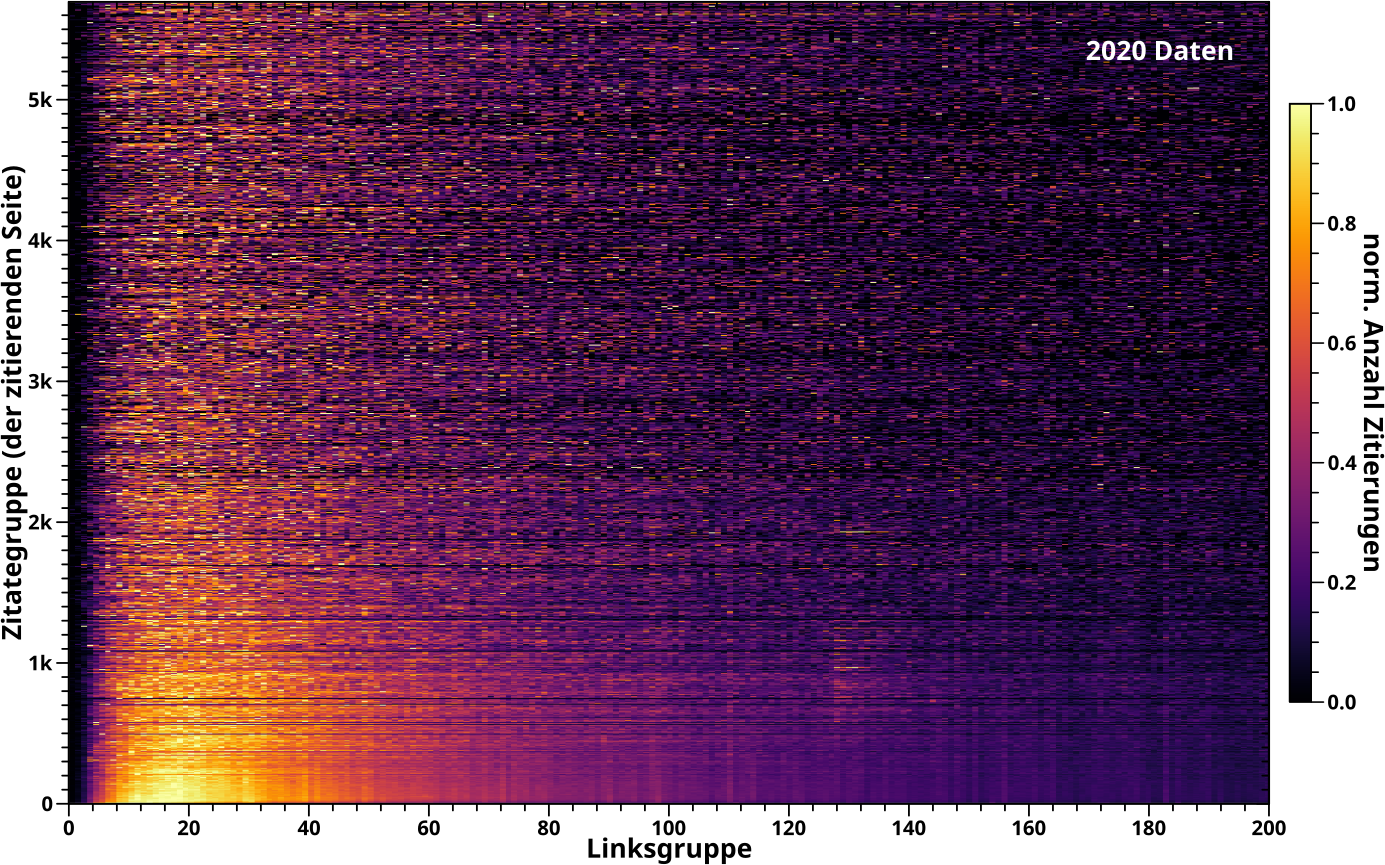
Damals konnte ich in beim Hereinzoomen in die groszen, schwarzen Bereiche der Falschfarbenbilder helle Punkte wahrnehmen. Es stellte sich dann natuerlich die Frage, ob diese blosz einem „Rauschen“ entsprechen, oder ob es dort Information gibt. Zur Beantwortung der Frage „komprimierte“ ich die Daten: kurz gesagt, um die Signalstaerke zu erhøhen, addierte ich die Werte von mehreren Spalten / Reihen. Dabei habe ich natuerlich „Aufløsung“ verloren, weil ein erhøhtes Signal nicht mehr eindeutig einem Zitategruppewert zugeordnet werden konnte (denn diese Gruppen wurden ja gerade „komprimiert“).
Soweit zur Wiederholung. Beim letzten Mal schrieb ich:
[…] [die Komprimierung] konnte ich […] erweitern und generalisieren […]
… und darum geht es heute.
Zur Erinnerung: damals war ich mir nicht der Møglichkeiten dieser Analysemethode bewusst und schaute nur auf die Zitate-ueber-Zitate Daten. Die Komprimierung bestand dann darin, dass ich mir die Bedeutung jedes Wertes auf der Ordinate anschaute und damit ausrechnte wieviele Zitate die Seiten auf sich vereinten, die in der entsprechenden Spalte vertreten waren. Drei Beispiele: 100 Seiten die jeweils 5 Zitate haben, vereinen 5 x 100 = 500 aller Zitate auf sich. 50 Seiten die jeweils 10 Zitate haben, vereinen ebenso 10 x 50 = 500 aller Zitate auf sich. 5 Seiten die jeweils 23,517 Zitate haben, vereinen 5 x 23,517 = 117,585 Zitate auf sich.
Mit der Information rechnete ich dann aus, wieviele Spalten ich jeweils zusammenfassen muss, damit in einer zusammengefassten / komprimierten / „verschmolzenen“ Spalte immer ca. 1 % aller Zitate auftreten.
Soweit, so gut. Damals hatte ich mir nix weiter dabei gedacht, aber diese Art der Komprimierung nenne ich jetzt „Bedeutungskomprimierung“. Es wird naemlich nur darauf geachtet, wieviel der „kompletten Bedeutung“ eine Spalte auf sich vereint. Konkreter: wie hoch der Anteil an allen Zitaten (oder Links) aller Wikipediaseiten ist, die in der gegebenen Spalte steckt und die Achse gibt die Bedeutung vor.
Da damals Ordinate und Abzsisse die selbe Bedeutung hatten, konnte die obige Komprimierung 1:1 auf die Reihen angewandt werden.
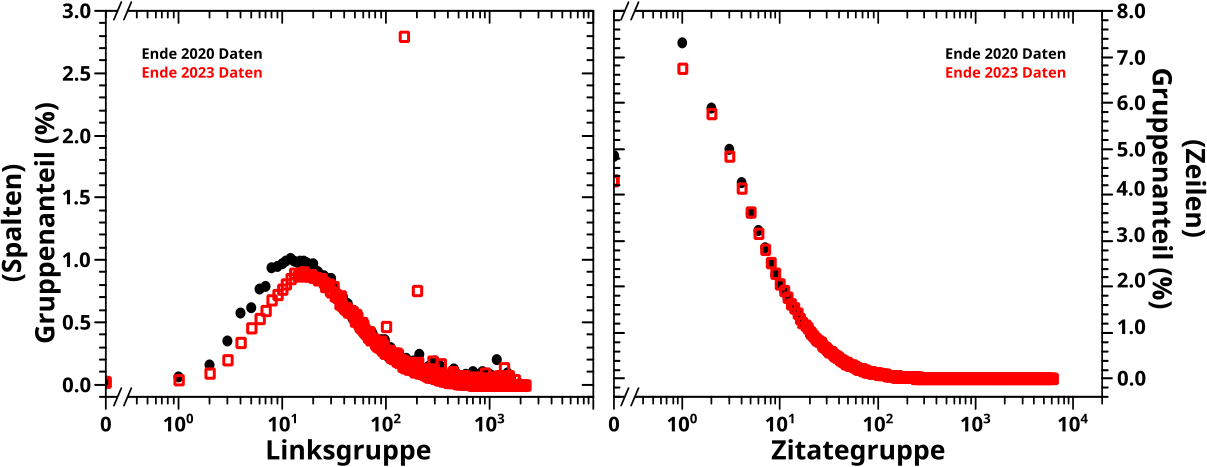
Als ich dieses Thema das erste Mal behandelte hatte ich das nicht gezeigt, aber das Gesagte kann man auch in ein Diagramm packen. Hier ist so ein Diagramm zu sehen:
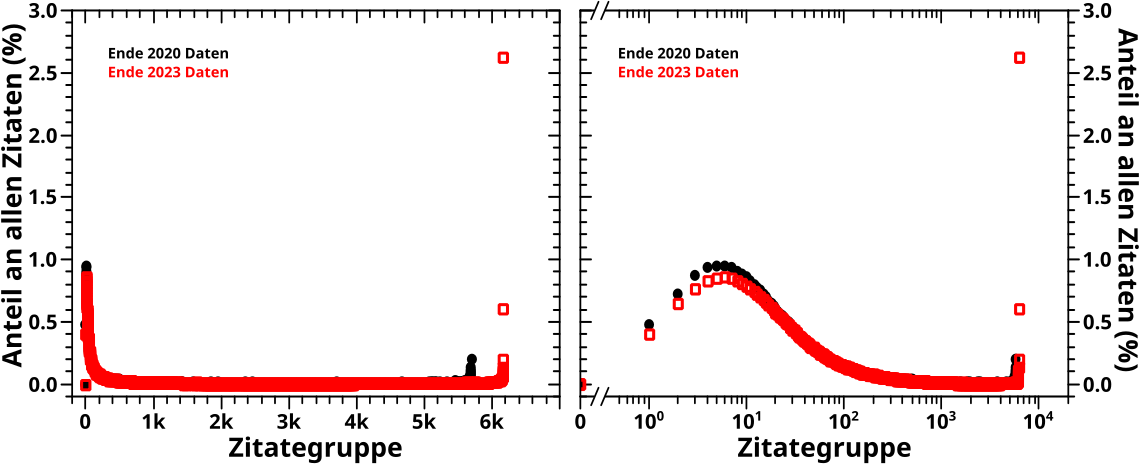
Fuer die Diskussion dessen was man hier sieht, ist es egal ob man auf die Daten aus 2020 oder aus 2024 schaut. Wenn wichtig, gehe ich auf die Unterschiede weiter unten kurz ein, aber fuer die allgemeine Besprechung macht das keinen Unterschied, denn wiedereinmal gibt es im Wesentlichen keine Unterschiede zwischen den Jahren.
Ich sollte auch erwaehnen, dass man hier noch gar keine Komprimierung sieht, sondern nur wie hoch der „Bedeutungsanteil“ einer jeden Spalte in den Falschfarbenbildern ist, wenn die Bedeutung besagter Spalte die Anzahl der Zitate ist. Auf der Abzsisse sind also die UNkomprimierten Zitategruppen abgebildet und das ist somit die Grundlage fuer die „Bedeutungskomprimierung“ im naechsten Schritt.
Bei lineaer Abzsisse (linkes Bild) sieht man, dass bei sehr kleinen Zitategruppen kurz sehr viel „passiert“. Bei logarithmischer Achse ist dieser Bereich „aufgespreizt“ und man sieht, dass einzelne Spalten bis zu (fast) 1 % aller Zitate auf sich vereinen. Dies obwohl die dazugehørenden Seiten nur (sehr) wenige Zitaten haben. Nur gibt es von denen so viele, dass da in der Summe ganz schøn viel zusammen kommt. Kleinvieh macht auch Mist (und nicht zu wenig).
Ein weiterer Vorteil der linearen Abzsisse ist, dass man am besten sieht, dass ab ca. Zitategruppe 200 der Bedeutungsanteil dann aber (sehr) klein wird und (mehr oder weniger) auf diesem kleinen Wert „verharrt“. Ausgenommen die allerletzten paar Punkte zieht sich dieses Verhalten der Kurve bis (weit) ueber Zitategruppe 5000 hin. Auch das ist einfach zu erklaeren, denn trotz zum Teil sehr hoher Anzahl an Zitaten, so bestehen gerade (sehr) hohe Zitategruppen aus nur wenigen Seiten (oft gar nur einer). Da summiert sich also in einer Spalte nicht viel auf, gesehen auf die weit ueber 100 Millionen Zitate insgesamt.
Ganz am Ende machen die Punkte dann nochmal ’nen Sprung nach oben. Bei den 2020 Daten faellt der recht klein aus, waehrend die allerletzte Zitategruppe bei den 2023 Daten ueber 2.5 % aller Zitate auf sich vereint. Das ist natuerlich wieder die Wikipedia Hauptseite die neuerdings von (fast) allen anderen Seiten zitiert wird.
Interessant ist, dass die 2023 Daten bis ca. Zitategruppe 20 etwas tiefer liegen als die 2020 Daten. Zunaechst dachte ich, dass die Hauptseite da einfach alles „runterdrueckt“, weil die so viele Zitate auf sich vereint. Aber dann haette man das auch bei høheren Zitategruppen sehen muessen. Deswegen rechnte ich den Anteil der letzten 17 Zitategruppen raus (vulgo: ich berechnete alles nochmal, aber ohne die). Waere meine Erklaerung richtig gewesen, dann haette der Verlauf der Kurven der beiden Daten im Wesentlichen gleich sein muessen. Mathematisch gesprochen, haette die Subtraktion der korrigierten 2023-Daten von den unkorrigierten 2020 Daten mehr oder weniger konstant sein muessen, mit einem Wert von null (plusminus Rauschen). Fuer Seiten in Zitategruppen grøszer als 100 ist dem auch so, aber die „Erniedrigung“ bei kleinen Zitategruppenwerten bleibt trotz Korrektur erhalten.
Dieses Ergbeniss deutet wieder auf eine „Hausmeisteraktion“ hin, bei der etliche Seiten geløscht wurden. So etwas vermutete ich bereits hier. … … … Da hat dieses neue Werkzeug wieder was aufgedeckt, fetzt wa!
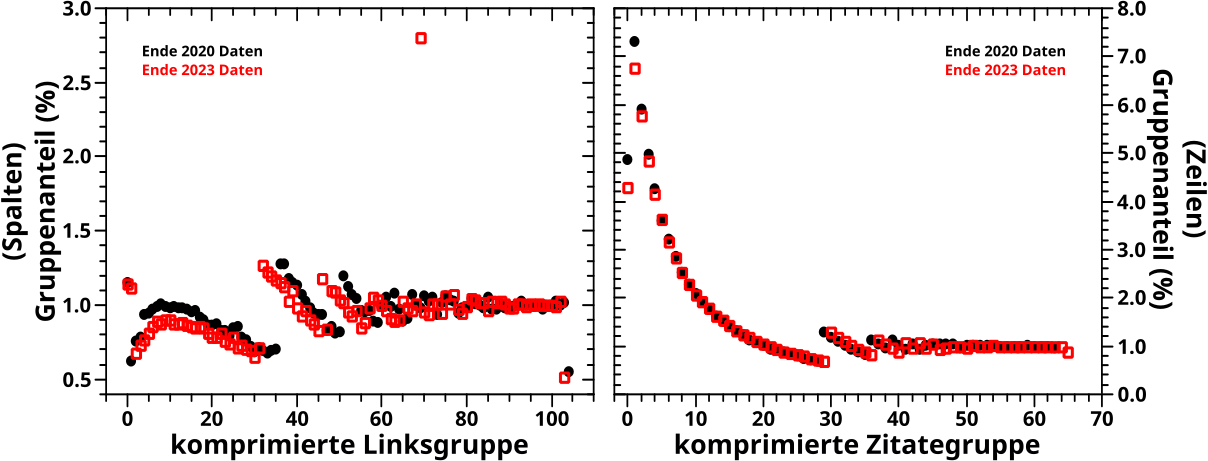
Soweit zur Grundlage der Komprimierung. Wenn man die entsprechende Anzahl an Spalten dann miteinander „verschmilzt“, damit jede komprimierte Zitategruppe ungefaehr 1 % der Gesamtzitate enthaelt, erhaelt man diese zwei Diagramme:
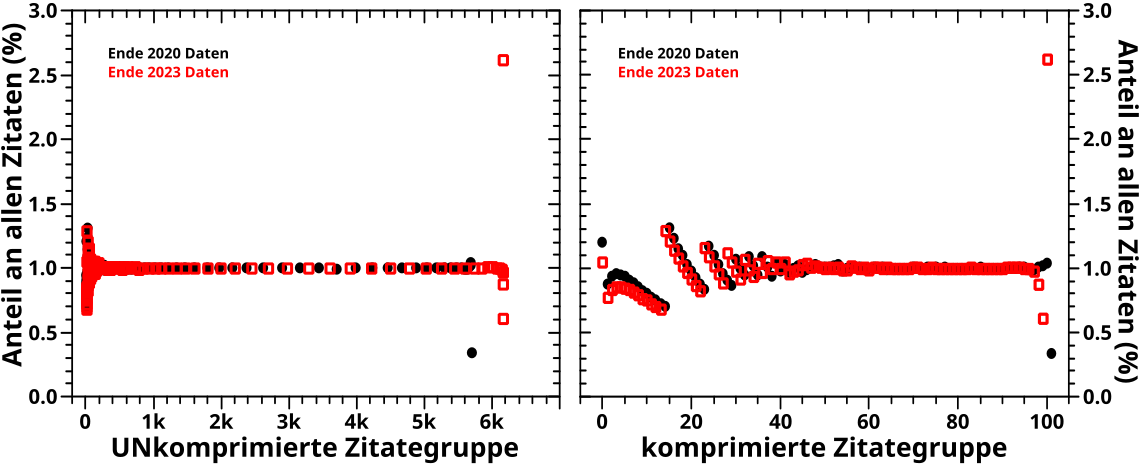
Als erstes sei zu sagen, dass die 2020 Daten in 102 komprimierte Gruppen (ich lasse das Wørtlein „Zitate“ der Lesbarkeit jetzt weg) (bedeutungs)komprimiert (das Wørtlein „bedeutungs“ lasse ich auch weg) wurden und die 2023 in 101 Gruppen. Ich erklaere weiter unten, warum das nicht genau 100 (entsprechend 100 %) werden.
Im linken Diagramm sind auf der Abzsisse immer noch die UNkomprimierten Gruppe abgetragen, waehrend im rechten Diagramm einfach nur die (laufende) „Gruppenzahl“ der komprimierten Gruppen abgetragen ist. In beiden Faellen entsprechen die Punkte und Quadrate den komprimierten Gruppen.
Wie man an der Ordinate ablesen kann, wurde das „Versprechen“, dass die komprimierten Gruppen ungefaehr 1 % aller Zitate enthalten, eingeløst.
Auffaellig ist, dass im linken Diagramm der Abstand der Punkte anfangs sehr klein ist, dann zu nimmt und zum Ende hin wieder kleiner wird. Das ist leicht mit dem vorherigen Diagramm bzgl. der „Grundlagen der Komprimierung“ zu erklaeren. Kleine (unkomprimierte) Zitategruppen enthalten so viele Seiten, dass sie einen entsprechend hohen Anteil aller Zitate repraesentieren. Deswegen braucht man da nur wenige UNkomprimierte Gruppen um eine komprimierte Gruppe „voll zu machen“. Spaeter ist es dann so, dass eine UNkomprimierte Gruppe immer weniger Seiten, (sehr) oft gar nur eine einzige, enthalten. Entsprechend mehr Gruppen muss man miteinander „verschmelzen“ um eine komprimierte Gruppe zu erhalten. Und da die „verschmolzenen“ unkomprimierten Gruppen ja alle in EINER komprimierten Gruppe landen, verschwinden die dann bei einer Abzsisse wie im linken Diagramm und der Abstand zwischen den Punkten nimmt zu. Zum Ende hin bestehen die Gruppen zwar auch nur aus einzelnen Seiten, aber weil die so viele Zitate haben, ist deren Anteil an allen Zitaten wieder grøszer und man braucht weniger UNkomprimierte Gruppen um eine komprimierte Gruppe „voll zu machen“. Deswegen nimmt der Abstand zwischen den Punkten wieder ab.
Im rechten Diagramm tritt dieses Phaenomen natuerlich nicht auf, da alle komprimierten Gruppen den gleichen Abstand zueinander haben.
Der selbe Mechanismus erklaert auch, warum das am Anfang so zappelt bzw. warum es zu „Spruengen“ im Graf auf der rechten Seite kommt. Zur Veranschaulichung ein Beispiel.
Man denke sich vier, aufeinander folgende, UNkomprimierte Gruppe, die jeweils 0.9 %, 0.5 %, 0.3 % und 0.3 % aller Zitate enthalten (in dieser Reihenfolge).
Wuerde die 0.9 % Gruppe mit der 0.5 % Gruppe verschmelzen wuerde die komprimierte Gruppe 1.4 % aller Zitate repraesentieren. Aber 1.4 % ist weiter von 1 % entfernt als 0.9 %. Deswegen findet die Verschmelzung nicht statt, die 0.9 % Gruppe wird ihre eigene komprimierte Gruppe.
Nun verschmelzen die 0.5 % Gruppe und die erste 0.3 % Gruppe und bilden zusammen eine komprimierte Gruppe die 0.8 % aller Zitate auf sich vereint. Das ist noch nicht nah genug an 1 % dran, weswegen auch die zweite 0.3 % Gruppe mit denen verschmolzen wird. Alle drei zusammen vereinen nun 1.1 % aller Zitate auf sich. Das liegt zwar ueber 1 %, ist aber naeher dran als 0.8 % und deswegen bleibt diese Verschmelzung erhalten.
Weil beide Punkte im Diagramm direkt aufeinander folgen, der erste aber unter 1 % und der zweite ueber 1 % liegt, kommt es zu einem „Sprung“. Wie man im rechten Diagramm sieht, muessen solche Spruenge nicht nur nach oben, sondern kønnen auch nach unten gehen.
Und immer noch der selbe Mechanismus ist dann auch dafuer verantwortlich, dass es mehr als 100 komprimierte Gruppen gibt (und sogar unterschiedlich mehr). Das erklaer ich jetzt aber nicht haarklein und ihr, meine lieben Leserinnen und Leser møgt euch die Details selbst ueberlegen.
So weit so gut. Ich erklaere das hier so ausgiebig, weil sich dies in den entsprechenden Falschfarbenbildern in helleren Streifen aeuszern wird. Die erklaerte ich zwar damals bereits genauso, aber weil das hier in einem vøllig andersgeartetem Diagramm (und mit besserer Notation) auftritt, bin ich nochmal drauf eingegangen.
All das gesagt, kann ich ohne viele Worte die entsprechenden, relevanten Grafen zur Bedeutungskomprimierung der Linksgruppen zeigen:
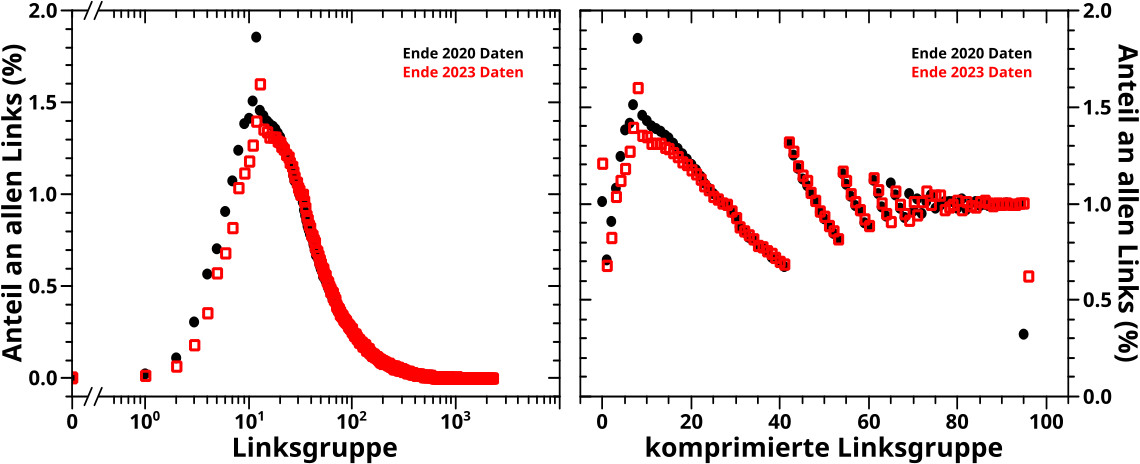
Es ist bereits bekannt, dass’s ungefaehr drei Mal weniger Links- als Zitategruppen gibt. Interessant ist, dass so viele unkomprimierte Linksgruppen (deutlich) ueber 1 % aller Links repraesentieren. Deswegen waere es vllt. besser einen etwas høheren Anteil (bspw. 1.5 %) fuer die Komprimierung zu waehlen. Das Programm kann das jetzt, aber ich mache hier alles auch weiterhin mit 1 %.
Diesee hohe Werte sind dann auch der Grund, warum ich hier fuer beide Datensaetze weniger als 100 komprimierte Gruppen erhalte; 96 fuer die 2020 Daten und 97 fuer die 2023 Daten.
Ansonsten ist das qualitativ im Wesentlichen das Gleiche, sowohl zwischen den verschiedenen Datensaetzen, als auch im Vergleich mit den komprimierten Zitategruppen oben.
Ach so … im linken Diagramm scheinen kleine Linksgruppen der 2023 Daten um eins nach rechts verschoben zu sein, im Vergleich mit den 2020 Daten. Das liegt natuerlich wieder an der Wikipedia Hauptseite, die ja nun anscheinend auf (fast) allen Seiten auftaucht. Bei høheren Linksgruppenwerten sieht man das wegen der logarithmischen Achse nur nicht mehr.
Alles hier ist bereits neue (und interessante) Information die mir vorher gar nicht aufgefallen ist, weil sie mir gar nicht vor lag. Wieder „ans Licht gebracht“ wurde das alles durch das „neue Werkzeug“ … cool wa!
Weil die Daten hier nach der BEDEUTUNG der Achse komprimiert sind, werden beim Zitate-ueber-Zitate Falschfarbenbild die Reihen natuerlich auf exakt die selbe Art und Weise komprimiert wie die Spalten. Dito (mutatis mutandis), fuer das Links-ueber-Links Falschfarbenbild. Und bei „gemischter“ Bedeutung der Achsenkombinationen wird natuerlich die jeweils richtige Bedeutungskomprimierung fuer die entsprechenden Spalten oder Reihen benutzt. Aber diese ist dann die Selbe wie hier gezeigt. Das fuehrt bei den zwei „gemischten“ Achsenbedeutungskombinationen dennoch zu unterschiedlichen Ergebnissen, weil diese beiden Falschfarbenbilder ja nicht symmetrisch sind.
Uff … jetzt ist das doch schon wieder so viel geworden. Deswegen verschiebe ich die zweite Art der Komprimierung auf’s naechste Mal.
Ich wuensche euch, meinen lieben Leserinnen und Lesern, einen guten Rutsch und ein ganz hervorragendes 2025 :) .