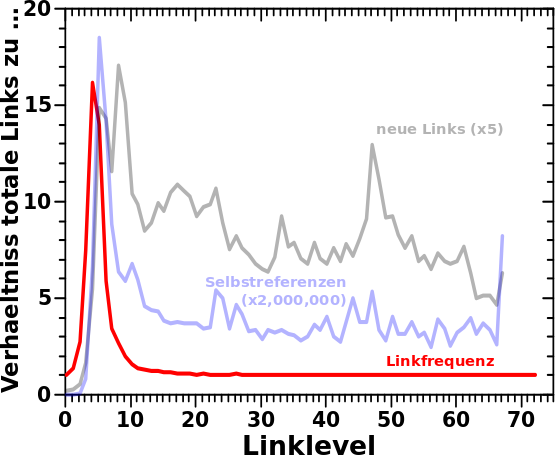
Beim letzten Mal zeigte ich dasVerhaeltnis der totalen Links zur Linkfrequenz (per Linklevel) und …
[e]inzig von Interesse ist, dass das Maxium […] [dieses Verhaeltnisses] bei LL4 liegt, waehrend die [Verhaeltnisse der totalen Links zu den neuen Links bzw. den Selbstreferenzen] den grøszten Wert erst bei LL5 erreichen […]
Zur Erklaerung erinnere ich an die Entwicklung der totalen Links in Abhaengigkeit vom Linklevel. Das Maximum der Verteilung liegt bei LL4. Der Unterschied zum Wert bei LL5 ist aber eher klein (was wichtig ist).
In diesem Diagramm …
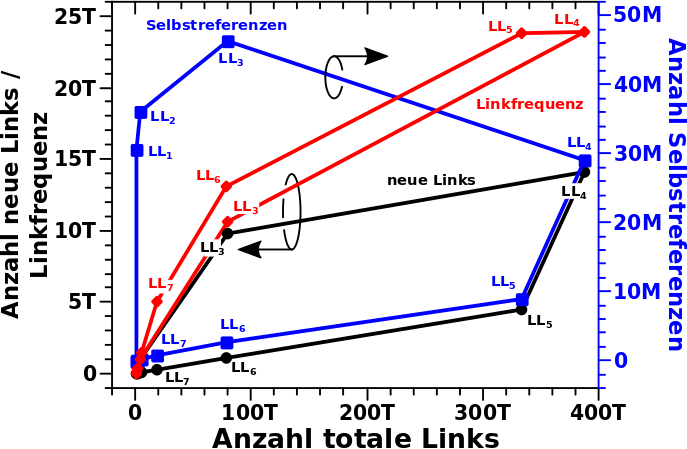
… sieht man nun, wie sich die drei anderen Grøszen von Interesse in Abhaengigkeit von den totalen Links entwickeln. Ich gebe zu, es ist etwas unuebersichtlich, ich gehe da aber Schritt fuer Schritt durch.
Das Folgende ist zu beachten (davon abgesehen, dass die Linien wieder nur der Visualisierung dienen, zwischen den Punkten gibt es keine Werte):
– Da die Anzahl der Selbstreferenzen (blau) so klein ist, brauchen die ihre eigene Ordinate (rechts) und die Zahlen der beiden Ordinaten unterscheiden sich um (ueber) 6 Grøszenordnungen!
– Die Zahlen zur Anzahl der totalen Links auf der Abzsisse sind nochmal (mehr als) einen Faktor 10 grøszer als die der Linkfrequenz (rot).
– Die Kurve der neuen Links (schwarz) und der Selbstreferenzen „geht“ im Uhrzeigersinn, die der Linkfrequenz hingegen im mathematisch positiven Drehsinn.
Im Allgemeinen gilt, dass die Anzahl der totalen Links immer grøszer ist als die der anderen drei Grøszen und fuer Letztere gilt, dass deren Zahlen „nach oben“ gehen wenn ich mehr totale Links habe und nach unten wenn derer weniger werden. Fuer alle Grøszen gelten aber unterschiedliche Limitierungen und deren „Dynamik“ von einem Linklevel zum naechsten ist unterschiedlich … hier wird’s jetzt kleinteilig
Die Selbstreferenzen sind am einfachsten zu erklaeren. Die Chance eine Selbstreferenz zu erhalten ist umso grøszer je naeher man am „Ursprung“ (also bei kleinen Linkleveln) ist. Deswegen macht die blaue Kurve als Einzige auch gleich auf LL1 einen solchen „Satz nach oben“. Die blaue Kurve steigt im Wesentlichen nur deswegen nach LL1 noch weiter an, weil dann (zunaechst) immer urst krass mehr totale Links zur Verfuegung stehen und davon eben auch welche Selbstreferenzen sind. Aber nach LL3 ist damit Schluss, die Chance eine Selbstreferenz zu erhalten ist zu klein und trotz weiter wachsender totaler Links nimmt der Wert der Selbstreferenzen nach LL3 ab. Weil die totalen Links bis LL4 weiter wachsen, nimmt auch das Verhaeltniss weiter zu.
Dass Selbiges aber auch noch zu LL5 waechst, trotz abnehmender totaler Links, liegt daran, weil die Selbstreferenzen schneller weniger werden. Die Anzahl Letzterer reduziert sich in diesem Schritt auf nur ca. 1/3 (von ca. 29M auf ca. 9M) waehrend die Anzahl der totalen Links nur auf etwas mehr als 4/5 reduziert wird (von ca. 390T auf ca. 330T).
Nach dem Maximum geht die Kurve aber wieder runter, weil sich der eben erwaehnte Umstand umkehrt; die totalen Links nehmen schneller ab als die Anzahl der Selbstreferenzen. Ich gebe zu, das sieht man nur bedingt im Grafen.
Sobald das Linknetzwerk sicher im Bereich der Zitierketten ist pegelt sich alles ein und beide Grøszen vermindern sich gleich schnell (wenn auch mit unterschiedlichen absoluten Werten), woraus die (mehr oder weniger) gerade Linie bei høheren und hohen Linkleveln folgt.
Bei den neuen Links liegt im Wesentlichen die gleiche Situation vor. Bis LL4 nimmt deren Anzahl zu, vor allem weil es einfach immer mehr totale Links gibt und davon sind halt etliche auch neu. Wenn man die Zahlen bis LL4 aufsummiert und durch die Anzahl alle Seiten teilt sieht man, dass jede Ursprungsseite bis dorthin (im Durchschnitt) bereits ueber 4 Millionen neue Links gesehen hat. Von LL4 zu LL5 liegt die gleiche Situation wie bei den Selbstreferenzen vor (aber aus anderen Gruenden). Eine Ursprungsseite sieht zwar immer noch viele totale Links (deren Anzahl nimmt nur geringfuegig ab) aber bis LL4 sind bereits 2/3 aller møglichen Links gesehen worden, es sind also nicht mehr viele ueber die als „neu“ gelten kønnen. Deswegen geht das Verhaeltniss der beiden Grøszen weiter nach oben; wie bei den Selbstreferenzen, so nehmen auch die neuen Links auf LL5 schneller ab als die totalen Links.
Dann werden diese beiden Grøszen bis ca. LL10 „im Gleichschritt“ weniger woraus das „Plateau“ folgt (und was man im Grafen wieder nur bedingt sehen kann). Der „Absacker“ im Verhaeltniss bei ungefaehr LL10 liegt darin, weil dort das Ensemble aller Wikipediaseiten (relativ schnell) zu groszen Teilen in die Zitierketten uebergegangen ist. Und da gibt es dann nur noch ein paar weniger neue Links und deren Anzahl im Verhaeltniss zu den totalen Links ist immer gleich, weil im Durchschnitt alle Seiten gleich viele totale Links (ca. 10 bis 30) haben und in einer Zitierkette im Durchschnitt immer nur ein neuer Link zu sehen ist.
Auf zur Linkfrequenz und dafuer muss man sich (wieder mal) erinnern, wie diese zustande kommt … das kann man hier nachlesen und ich baue darauf auf … in kurz ist die Linkfrequenz die „gedeckelte“ Anzahl der totalen Links … aber der Reihe nach.
Auf LL4 gibt es in der Summe fast 400 Billiarden totale Links. Bei ca. 6 Millionen Ursprungsseiten bedeutet dies, dass jede Ursprungsseite auf LL4 die Links zu ca. 65 Millionen Wikipediaseiten sieht. Von Ausnahmen (die bei diesen Zahlen aber nicht so schwerwiegend sind, dass sie die hier getaetigten Aussagen ungueltig machen wuerden) abgesehen, bedeutet das im Wesentlichen, dass jede Ursprungsseite auf LL4 jede (!) andere Seite 10 Mal sieht. Fuer die Linkfrequenz wird die dann nur ein mal gezaehlt (deswegen gedeckelt). Der wirkliche Wert der (Summe der) Linkfrequenz (aller Seiten, per Linklevel) auf LL4 liegt bei ca. 24 Billiarden was nahe genug dran ist an der eben durchgefuehrten Ueberschlagsrechnung (nicht mal ein Faktor 2 Unterschied … gut wa!).
Oder anders: wenn hinreichend viele totale Links vorhanden sind, ist der Linkfrequenzzaehler fuer alle Seiten maximal, weil sie eben von jeder Ursprungsseite aus kommend „gesehen“ werden.
Das ist der wesentliche Unterschied zu den Selbstreferenzen und den neuen Links. Wie oben gesagt ist die Anzahl der Ersteren von den totalen Links abhaengig, besagte Anzahl wird aber dadurch (massiv) eingeschraenkt, weil die Wahrscheinlichkeit fuer eine Selbstreferenz mit zunehmendem Linklevel rapide (!) abnimmt. Der erste Teil dieser Aussage gilt auch fuer neue Links, deren Anzahl wird aber deswegen eingeschraenkt, weil jeder ein Mal gesehene Link beim zweiten Mal nicht mehr neu ist und deswegen nicht mehr gezaehlt wird.
Fuer die Linkfrequenz gilt keine dieser Einschraenkungen. Und deshalb bleibt deren Zaehler auf LL5 grosz, bei gleichzeitiger (hinreichend kleiner) Abhnahme der Anzahl der totalen Links, was zu einem kleineren Verhaeltnis dieser beiden Grøszen fuehrt, anstatt zu einem weiter ansteigenden.
Danach geht’s dann ganz fix in die „Zitierkettenphase“ mit dem Umstand, dass in den Zitierketten im Wesentlichen die totalen Links (fast) der Linkfrequenz entsprechen.
Zum Abschluss dazu sei gesagt, dass das alles bekannt ist. Hier kommen aber einige der vorhergehenden Erkentnisse zusammen und alle werden gebraucht um so eine kleine Diskrepanz eines um ein Linklevel verschobenen Maximums zu verstehen.
Schade, dass es so ein antiklimaktischer Ausstieg aus der Analyse der Daten zum Wikipedialinknetzwerk ist. Aber so ist das nun mal in der Wissenschaft. Das Allermeiste ist kleinteilig, muss genau betrachtet werden und ist fuer Auszenstehende oft eher langweilig … siehe auch hier und hier. Und so war es ja eigentlich schon auf der ganzen „Reise“ … viel „Routine“, gesprinkelt mit ein paar coolen Entdeckungen.
Das ist aber noch nicht ganz das Ende von Kevin Bacon. Ich møchte noch eine Sache ansprechen und eine Zusammenfassung schreiben … und vielleicht auch noch ein bisschen Meta diskutieren, aber da bin ich mir gerade noch nicht so sicher.