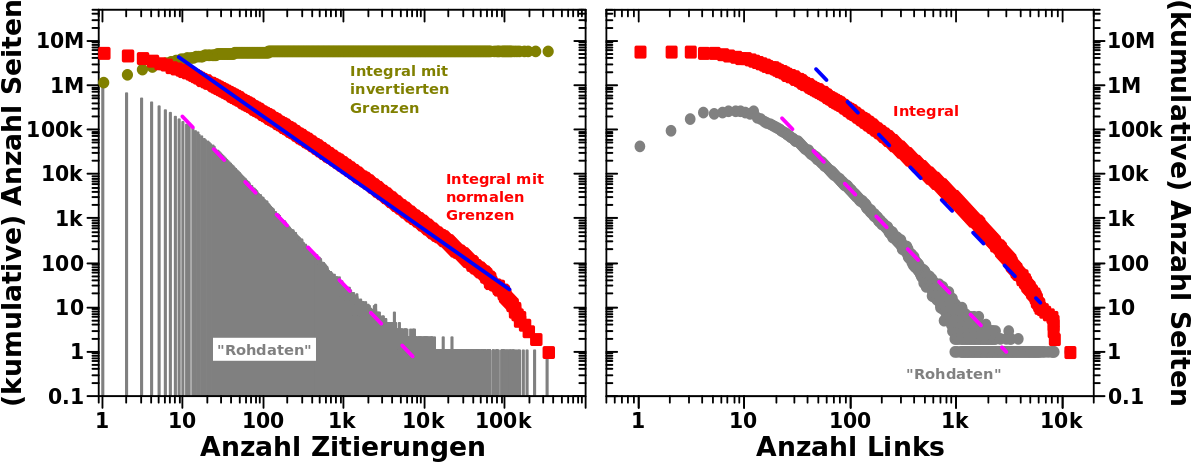
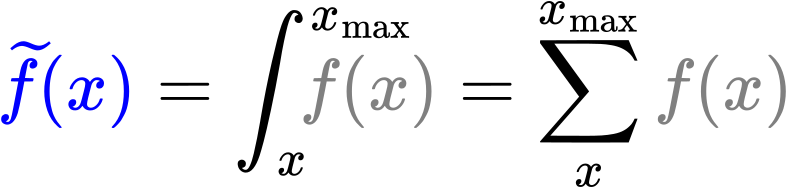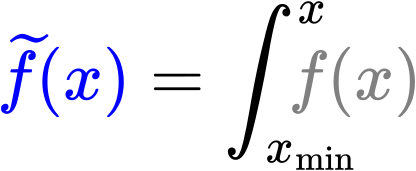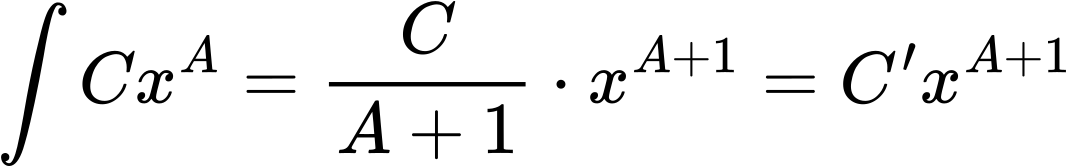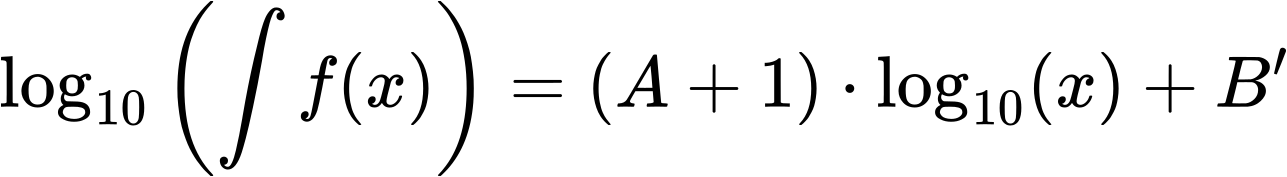Hier schaute ich zum mir ersten Mal die Abhaengigkeit der Links einer Seite von der Anzahl der Zitate die diese erhaelt an. Es war ein „Blob“. Dann berechnete ich die durchschnittliche Anzahl an Links ueber alle Seiten die eine gegebene Anzahl an Zitaten erhalten hatten und der Blob verschwand und ich erhielt das erste wahrhaft ueberraschende Ergebniss in dieser Maxiserie: der Zusammenhang folgt auch einem maechtigen Gesetz. Besagtes Ergebnis ist in diesem Diagramm nochmals in grau wiedergegeben …
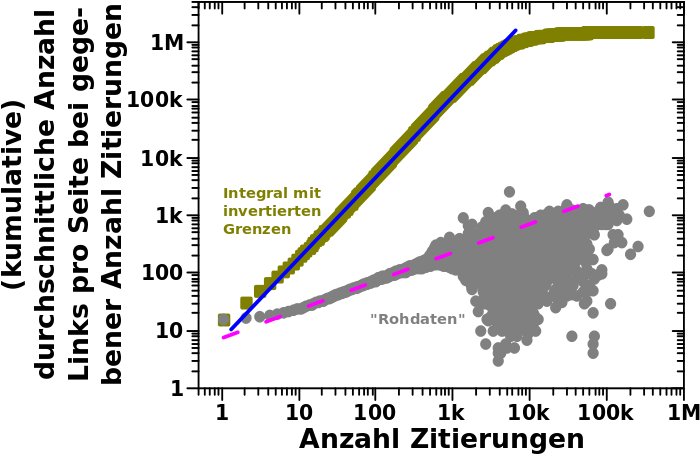
… und die (von Hand reingelegte) Regressionsgerade (lila, nicht durchgehende Linie) fuehrt zu einem Exponenten von +0.5.
Weil es „aufwaerts“ geht, muessen die Grenzen fuer das Integral invertiert werden um etwas Vernuenftiges zu erhalten (wie beim vorletzten Mal gezeigt) und besagtes Integral sind die Rechtecke in oliv. Die dazugehørige (auch von Hand reingelegte) Regressionsgerade in blau hat einen Anstieg von ca. +1.4 (eine Aenderung von ca. 5.5 Grøszenordnungen auf der Ordinate und ca. 4 Grøszenordnungen auf der Abszisse) … was ja wohl mal (beinahe) das mathematisch perfekt zu erwartende Resultat war. Das Integral bestaetigt also meine urpsruenglichen Ergebnisse … cool wa.
Bei den Rohdaten fangen die Daten zu „zappeln“ an ab ca. 500 Zitaten und haben eine ganz betraechtlich Varianz ab ca. 2000 Zitaten. Das liegt daran, weil es nicht so viele Seiten gibt, die derart viele Zitate erhalten und ich diskutierte das im damaligen Artikel.
Das Integral geht aber bis 200 Zitiaten schøn gerade weiter was natuerlich toll ist … um dann ueber nur eine halbe Grøszenordnung (also ziemlich abrupt in diesem Zusammenhang) in eine Parallele zur Abszisse ueber zu gehen. Dies fuehrte mich zunaechst dazu zu sagen, dass die Verlaengerung der urpsruenglichen Regression ueber 2000 Zitate hinaus nicht zulaessig ist.
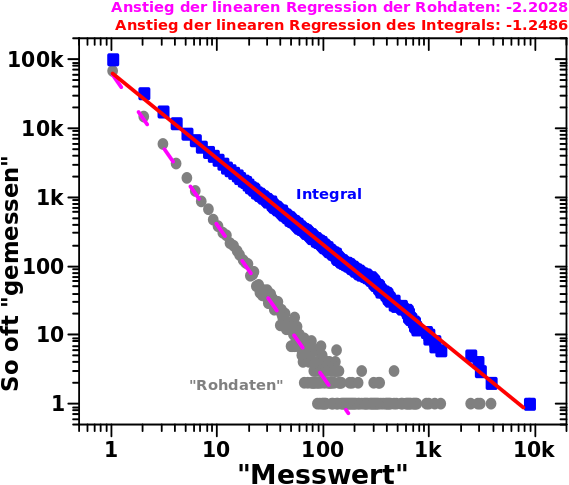
Aber dann schaute ich mir die Rohdaten nochmal nur fuer diesen Bereich an und kam zu dem Schluss, dass das DOCH auch bei ueber 2000 Zitaten gilt. Dort waechst die Anzahl der Links im wesentlichen nach dem gleichen Potenzgesetz wie vorher. Warum zeigt sich das aber nicht in den integrierten Daten?
Nach etwas gruebeln kam ich auf die Antwort (die hier bereits erwaehnt wurde): es gibt dort nicht genuegend Daten! Im Beispiel beim vorletzten Mal wurden zunehmend mehr „Messungen“ je høher der „Messwert“ auf der Abzsisse war. (Vermutlich viel zu) Vereinfachend gesagt, befanden sich im Abschnitt 10 bis 100 auf der Abzsisse beim letzten Mal zehn Mal weniger „Messungen“ im Vergleich mit Abschnitt 100 bis 1000. Damit kann die Summe ueber letzteren Abschnitt zehn Mal grøszer werden und in einem log-log-Plot waechst das linear.
HIER aber nimmt die Anzahl der Daten mit zunehmender Anzahl Zitate ab und der „Integralansatz“ hørt auf zu funktionieren!
Die Mathematik ist hier also nicht „kaputt“ und auch die Daten sind es nicht. Vielmehr ist die Bildung der Summe der vøllig falsche Ansatz um Informationen aus den Daten mit mehr als 2000 Zitaten heraus zu bekommen. Das ist AUCH eine ganz wichtige Erkentniss.
Fuer ein Modell muesste in diesem Fall also zunaechst in Betracht gezogen werden, wie wahrscheinlich eine Seite mit einer gegebenen Anzahl Zitate ist. Fuer die Anzahl der durchschnittlichen Seiten gilt dann aber wieder das Potenzgesetz und die Verlaengerung der urpsruenglichen Regression ueber 2000 Zitate hinaus ist eben DOCH gueltig.
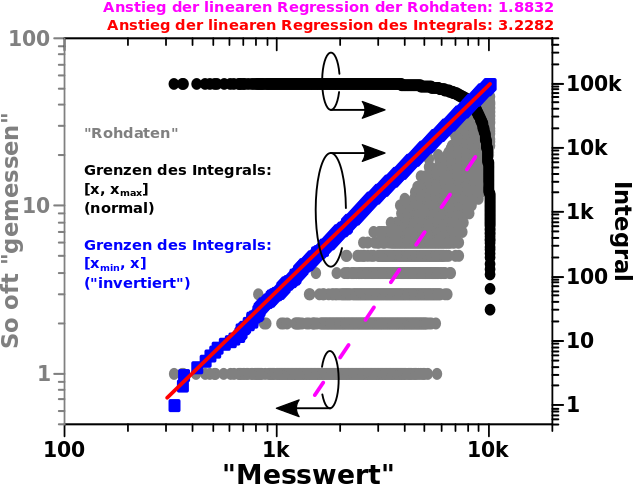
Etwas ganz anderes, aber sehr wichtiges: alles in Betracht ziehend sieht man hier, dass der „Integralansatz“ auch dann funktioniert, wenn die Ordinate NICHT nur eine „Abzaehlung von Ereignissen“ repraesentiert. Oder anders: bisher hatte ich nur Histogramme gezeigt, da zaehlt man auf der Ordinate wie oft eine „Messung“ mit einem bestimmten Ergebniss auftritt.
Die durchschnittliche Anzahl an Links ist aber nix was so „abgezaehlt“ werden kønnte.
Dennoch funktioniert der „Integralansatz“ und das fetzt (und ist wichtig). ABER das hier kan auf gar keinen Fall als kumulative Wahrscheinlichkeit interpretiert werden! Das ist natuerlich der Grund warum das Integral NICHT linear bis zum Ende ist, obwohl die Rohdaten das durchaus sind.
Das soll reichen fuer heute. Bisher laeuft’s ja nicht so doll mit …
[…] ich schaue mir das nicht nochmal im Detail an; das werden also Artikel mit Bildern und (meist) nicht ganz so viel Text […]
Liegt halt daran, dass …
[…] es was Neues oder Interessantes zu sehen gibt.
Fetzt ja auch, nicht wahr :) … Andererseits gehe ich ueber Dinge deren Diskussion ueber mehrere Artikel ging nur kurz nochmal rueber und beim letzten Mal habe ich sogar zwei Sachen in nur einen Beitrag gepackt … das ist ja schon was :)