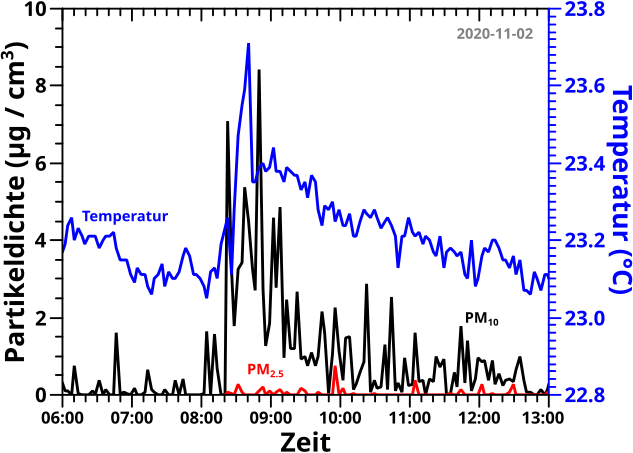
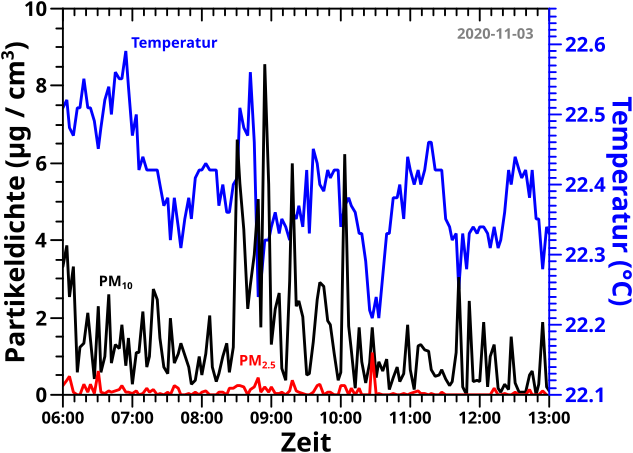
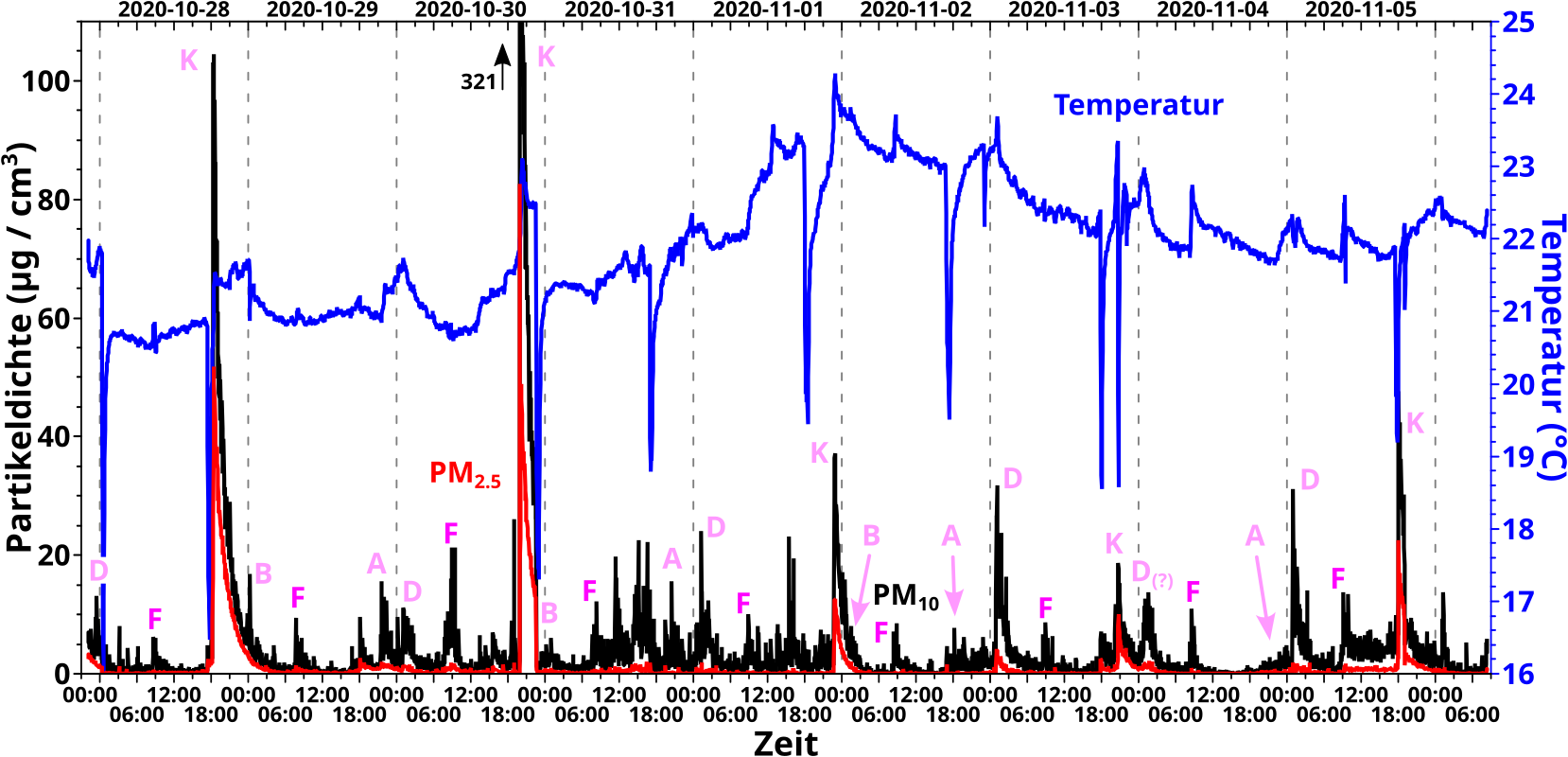
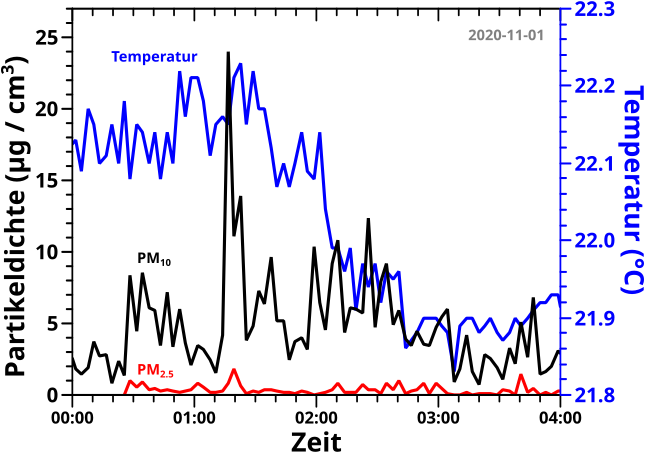
Bei hohen Sachen møchte man ja gerne wissen, wie hoch die sind. Bei besonderen Dingen gibt man das in Meter an … der Fernsehturm, der Berg, die Statue. Bei den allermeisten Gebaueden ist es hingegen von grøszerem Interesse zu wissen wie viele Stockwerke das hat. Ja klar, Gebaeude mit gleicher Anzahl an Stockwerken sind oft unterschiedlich hoch, aber mir geht es um eine „Essenz der Sache“ die ich mit dem folgenden Beispiel versuche zu illustrieren.
Auf dem Dorf (bzw. auch in der kleinen Stadt) erschien mir damals, als junger Mensch, der drei- oder mglw. sogar fuenf(!)støckige Plattenbau als ziemlich hoch. Dann kam ich als (sehr) junger Erwachsener in ’ne richtige Stadt und dort waren dann die 10-støckigen Bauten ziemlich hoch. (Von heute aus gesehen) Nicht sehr viel spaeter ging’s ab und zu mal in die Hauptstadt und dort hielt ich mich dann in einem 17-Støcker auf; dieser schien mir als ziemlich hoch. Nun als mittelalterlicher Mann kam ich nach Japan und die wirklich hohen Gebaude dort machten im Wesentlichen den gleichen Eindruck auf mich: ziemlich hoch … die hatten aber viel mehr als 17 Stockwerke … nur „fuehlte“ es sich nicht als soooo viel mehr an.
Worauf ich hinaus will ist, dass all diese Gebaeude in Metern zwar immer høher werden, aber deren „gefuehlte Grøsze“ nimmt irgendwie nicht im selben Masze zu.
Ein Ausweg aus dem Dilemma bietet die oben erwaehnte (und im vorigen Paragraph verwendete) Zaehlweise in Stockwerken. Mir „sagt“ 17 Stockwerke mehr als 50 Meter. Wie hoch sind eigentlich 50 Meter (ziemlich hoch wuerde ich mal sagen) und was ist der Unterschied zu 30 Metern (was ja immer noch ziemlich hoch ist)?
Da stellte sich dann in Japan aber ein Problem: das sind so viele Stockwerke, dass man zwar auf die Idee die zu zaehlen kommt, sich aber schnell beim Zaehlen mit den Augen auf der Fassade „verirrt“, denn es gibt keine „Anheftungspunkte“ die anders aussehen als die anderen, immer gleichen Fenster. Dieses Problem tritt bei einem 17 Stockwerken (noch) nicht (so stark) auf.
Damit komme ich zum heutigen Bild, denn als wir in Sapporo aus dem Bahnhof traten und unser Hotel suchten, tauchte dort dieses (ziemlich hohe) Hochhaus auf …

… und zu meiner Freude waren die Stockwerke nummeriert. Toll wa!
Und mit der Stockwerknummer 49 macht das schon ’nen ganz anderen Eindruck, als der ziemlich hohe 17-Støcker in Berlin.
Wie viel høher das ist, wird einem auch insb. dann etwas bewusster, wenn man bedenkt, dass Letzterer gar nicht mit im Bild gewesen waere (weil ich bei 19 Stockwerken abschneide). Das ist dann eine andere „Perspektive“, die man durch die blosze Angabe der Høhenmeter nicht wirklich bekommen haette.
Auszerdem ist es ebenso eine gute Visualisierung gewisser, kleiner Eindruecke (Wortspielkasse!) meiner Japanreise.