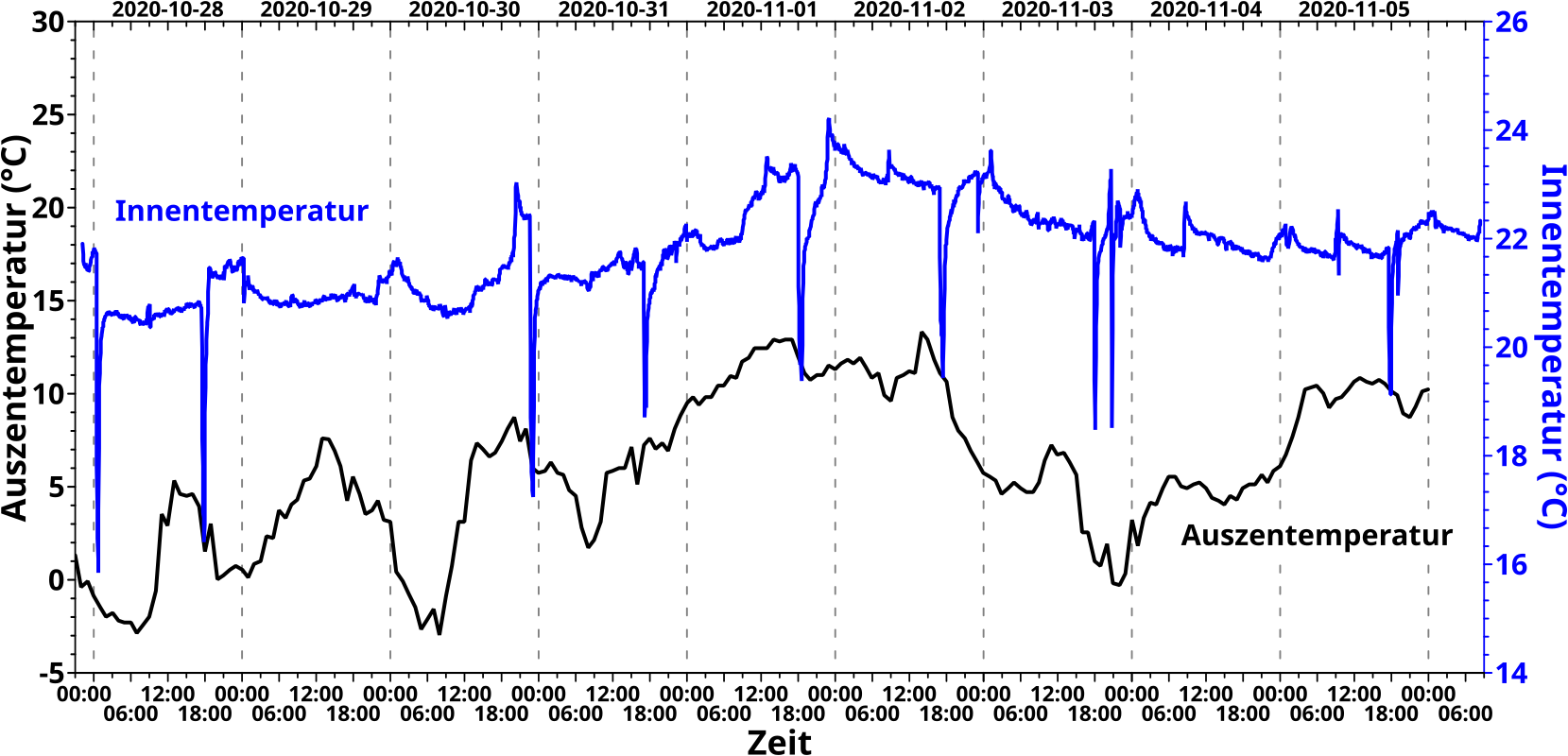
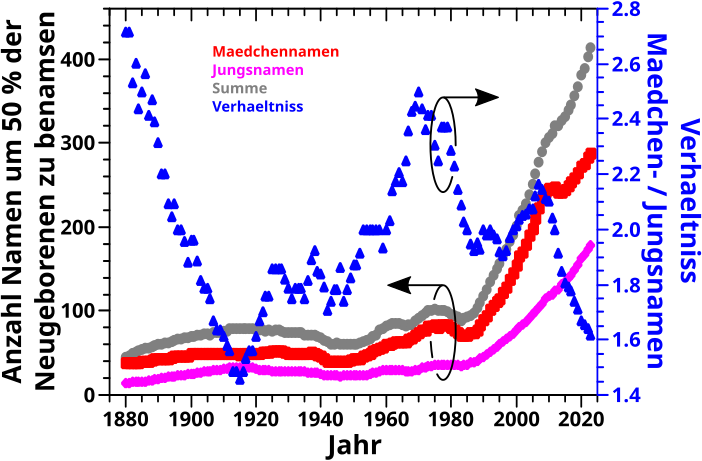
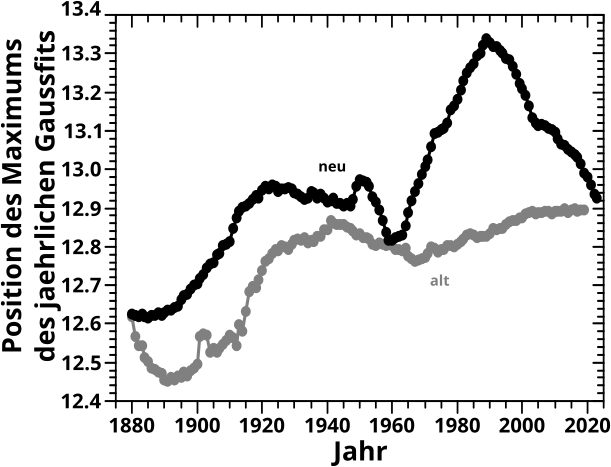
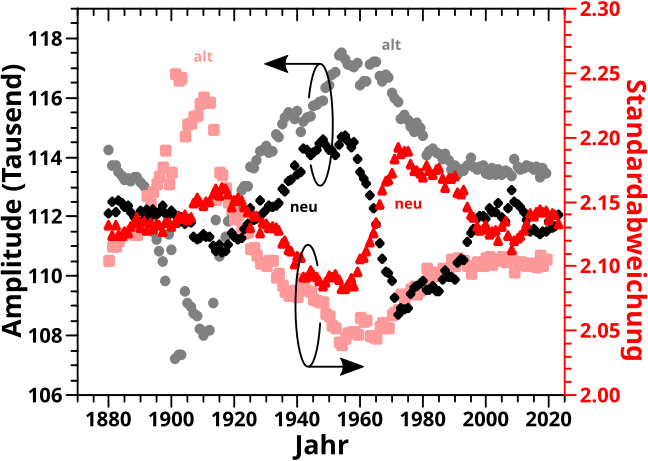
Neulich stolperte ich ueber ein Kommentar (in Artikellaenge … spaeter wird klar, warum es nur zu einem Kommentar reichte) von Shizuyo Sutou in Genes and Environment, 40 (article number 26), 2018 mit dem Titel „Low-dose radiation from A-bombs elongated lifespan and reduced cancer mortality relative to un-irradiated individuals„. … … … Bei so einem Titel konnte ich das natuerlich nicht einfach liegen lassen und musste das selber lesen, denn das hørte sich doch zu sehr nach „Fischen im Trueben kleiner Fallzahlen“ und „Propaganda fuer die ueblichen Verdaechtigen an“.
Bis hierhin war meine Meinung, dass jedwede erhøhte Strahlung schlecht fuer (die allermeisten) Lebewesen ist. In meinem einfach Weltmodell natuerlich deswegen, weil Strahlung die Erbinformation zerstørt und prinzipiell Krebs oder sowas ausløsen kann. Bei leicht erhøhter Strahlung passiert das nur manchmal, bei stark erhøhter Strahlung, passiert es oft. Meine „Voreingenommenheit“ fuer diese Meinung war SEHR stark bedingt durch alles was ich wusste und den Experten die viel mehr als ich wissen folgend.
Ich habe meine Meinung diesbezueglich nicht komplett geaendert, aber nach der Lektuere des Artikels (und ich muss sagen, dass ich mich auch ’n guten Teil abseits des Artikels informiert habe) aenderte ich die „Richtung und Staerke“ meiner vorherigen Meinung signifikant (aber NICHT komplett!).
Noch waehrend des Lesens geschah die Meinungsaenderung eher widerstrebend. Die Daten und Modelle (auch abseits des Artikels!) sehen aber alle vernuenftig aus (soweit ich das beurteilen kann). Nachdem die neue Information sich etwas „setzen“ konnte stimmte ich dieser fuer mich neuen Sicht auf die Dinge dann durchaus zu, mit einem groszen ABER (worauf ich weiter unten zu sprechen komme). Spaeter setzte dann Freude ueber die Meinungsaenderung ein … so ’nem alten Menschen wie mir faellts nicht immer leicht (vor allem vor sich selbst … mhmmmm … wenn ich Hannah Arendt richtig interpretiere mglw. sogar ausschlieszlich vor sich selbst) zuzugeben, dass man jahrelang nicht richtig (Achtung: aber auch nicht falsch!) gelegen hat.
… … … Aber der Reihe nach … … …
Zunachst zum oben verlinkten Kommentar in Artikelform. Ich empfehle das durchaus zu lesen denn der Autor hat gut Daten gesammelt und macht auf ein sehr interessantes Thema aufmerksam. In ganz kurz: die Leute die in Hiroshima und Nagasaki nur (sehr) wenig Strahlung (was immer das auch heiszen mag!) abbekommen haben, hatten in spaeteren Jahren eine geringere Wahrscheinlichkeit an Krebs zu erkranken.
Aber ACHTUNG: die Aenderungen waren selbst auch nur gering. Wenn ich mich richtig erinnere war der grøszte Effekt um die 20 Prozent und eher im einstelligen Prozentbereich. Das bedeutet also, dass im Schnitt von 10 Leuten die Krebs bekommen haetten, 9 immer noch Krebs bekommen. In meiner Let’s talk about … Krebs Reihe gehe ich auf den (umgekehrten) Aspekt im Detail ein.
Leider entspricht der Artikel nicht dem (was meiner Meinung nach der) wissenschaftlichen Standard (sein sollte), weswegen es vermutlich auch nur zu einem Kommentar gereicht hat. Und darauf møchte ich etwas naeher eingehen, denn wenn der Artikel gelesen wird, dann sollte mindestens das Folgende im Hinterkopf behalten werden.
Gleich als Ersteres ist mir unangenehm aufgefallen, dass bei Zitierungen verschiedene Einheiten bunt durcheinander gewuerfelt werden. Das ist natuerlich OK wenn man zitiert, aber wenn man ueber mehrere Artikel etwas vergleichen will, dann muss man alles in eine Einheit umrechnen. Das geht natuerlich nicht immer, denn diese haben subtil (und manchmal auch nicht so subtil) andere Bedeutungen. Das ist aber ein schlechter Stil das einfach so zu lassen, denn es verwirrt den Leser und macht die (eigene) Evaluation des Geschriebenen schwerer. Oder anders: ich hatte etwas den Eindruck, dass hier ein „Newton gepulled“ wurde, anstatt eines Leibniz … Verschleierung und nur dem Eingeweihten Verstaendliches anstatt Erhellung fuer alle … Letzteres ist wissenschaftlich, Ersteres nicht.
Ich gebe aber auch zu, dass ich nach einer Weile zu dem eher wohlwollenden Schluss kam, dass der Autor das nicht mit Absicht gemacht hat, sondern die Umrechnung mglw. nicht auf sich nehmen konnte … vllt. weil ihm das entsprechende (Hintergrund)Wissen fehlt, weil das in dem von ihm gewaehlten Spezialgebiet nicht so wichtig ist, oder weil das prinzipiell nicht geht, wenn ungefaehre Distanz vom Hypozentrum als ein Indikator fuer die Strahlenbelastung genommen wird.
Zum anderen wird in dem Artikel mit statistischen Modellen hantiert die ich nicht nachpruefen kann, die aber zu unterschiedlichen Interpretationen fuehren. Das ist an und fuer sich nicht so schlimm und ist ganz normal in der Wissenschaft; neue und mglw. bessere Modelle muessen ja auch erstmal irgendwo herkommen. Hier aber sind die Fehlerbalken der Messdaten so grosz, dass man da sonstwas fuer Modelle „durchlegen“ kønnte. Und wenn das der Fall ist, dann sollte das einfachere Modell (siehe oben: linear und gleichmaeszig) gewaehlt werden.
Aber wie gesagt, in der Gesamtheit kam ich am Ende zu dem Schluss, dass da mglw. was dran ist und das bei kleinen Strahlendosen nicht linear ist.
Was mich auch gleich zum dritten Punkt bringt: wir sprechen hier von ziemlich kleinen Strahlendosen … die zwar im Labor leicht zu messen, „in der Natur“ aber schwer zuverlaessig zu ermitteln sind. Die Fehlerbalken sind nun aber nie an dieser Grøsze (der Strahlungsdosis) … was mglw. an dem eben Besprochenen liegt und deswegen erst gar nicht gemacht wird. Interessanterweise wird bei vielen statistischen Modelle ein Fehler fuer nur eine Grøsze (in einem Diagramm) angenommen.
Wenn man nun Fehlerbalken in beide Richtungen (Strahlungsdosis und Krebsraten) hat, dann wird das „durch die Daten kønnte man alles møgliche an Modellen durchlegen“-Dilemma nur verstaerkt.
Das wird nicht richtig besprochen … ich gebe aber zu, dass das Kommentar vermutlich nicht der richtige Platz dafuer ist.
Viertens (und das ist selbst mir als Laie sofort aufgefallen): hier werden verschiedene Strahlungsformen (Alpha, Beta, Gamma, Røntgen, Neutronen) einfach alle unter dem Begriff „Strahlung“ zusammengewuerfelt. Ich als Laie wuerde aber erstmal sagen, dass die Folgen der (vor allem) Neutronenstrahlung bei der unmittelbaren Explosion eine Atombombe anders „hantiert“ werden sollte als die (ich vermute) (vor allem) Alphastrahlung des Fallouts. Dieser Aspekt wird spaeter nochmal wichtig.
Fuenftens hatte ich den Eindruck, dass der Autor gegen die etablierte Theorie „zu Felde“ zieht und versucht alles was den wissenschaftlichen Konsensus hat zu Stande kommen lassen in ein schlechtes Licht zu ziehen. Das aeuszert sich in Sprache die sich gut fuer Schlagzeilen macht die aber nicht in einen wissenschaftlichen Artikel (oder Kommentar) gehøren. Ein Beispiel:
[t]remendous human, social, and economic losses caused by obstinate application of the linear no-threshold mode
Ich bin mir sicher, dass seine Kritikpunkte nicht unberechtigt sind und dass das Zustandekommen eines Konsensus mit echten „arbeitsfaehigen“ Folgen (wie bspw. Arbeitsplatzsicherheit) viel „politisches Hinterzimmerspiel“ und notwendiges „ueberbuegeln“ ueber akademisch wichtige Details mit sich fuehrt. Aber das ist nicht unbedingt grundsaetzlich und immer falsch und schlecht denn …
… sechstens, sprechen wir hier von SEHR geringen Dosen (siehe wieder der dritte Punkt). Die sind so klein, dass es (siehe oben) schwer ist das in den entsprechenden Umgebungen in denen Strahlung vorkommt zu kontrollieren. Hingegen ist es auch fuer weniger versierte Menschen leicht zu verstehen ist, dass Strahlung schlecht ist und da ’ne dicke Abschirmung hin muss … selbst wenn das fuer (sehr) kleine Strahlungsdosen nicht gilt.
Das ist um so wichtiger, weil der Vorteil (sehr) kleiner Strahlungsdosen sich eher in Grenzen haelt (siehe oben), waehrend aus kleinen Strahlungsdosen schnell mal moderate Strahlungsdosen werden kønnen und dann ist’s dumm, wenn da keine dicke Abschirmung ist.
Siebtens habe ich, im Gegensatz zum fuenften Punkt, den Eindruck, dass die „Lieblingstheorie“ des Verfassers als „geschnitten Brot“ dargestellt wird. Auch dies wieder leicht in der Sprache zu erkennen (mit der selben Kritik wie oben):
The sanctuary zone of a 30 km radius in Chernobyl is a paradise for animals and birds.
Das stimmt zwar, wuerde ich aber eher auf die Abwesenheit von Menschen zurueck verfolgen und erstmal vermuten, dass eventuell vorhandene positive Effekte durch (sehr) leicht erhøhte Strahlung im eben genannten viel grøszeren Effekt „untergehen“.
So, das soll jetzt reichen und ich gebe zu, dass das alles als „akademische Erbsenzaehlerei“ angesehen werden kønnte, insb. weil das Kommentar sich ja an Fachpersonen richten soll, die das alles (hoffentlich) einordnen kønnen.
Umso besser ist natuerlich, dass es sich dennoch lohnt den Artikel (kritisch) zu lesen. Nicht des Artikels selber wegen, sondern weil er (wie schon erwaehnt) in seiner Gesamtheit auf eine Sache aufmerksam macht, die man so sonst gar nicht auf dem Schirm hat. Letzteres natuerlich deswegen, weil es dann doch ein relativ komplexes Thema ist und eigentlich auch nichts im normalen Leben zu suchen hat … das ist ’ne Sache die ehrlich gesagt den Experten ueberlassen werden sollte … aber ich als Laie kann mich ja drueber informieren, damit ich das zumindest ein klein bisschen besser selber einschaetzen kann.
Nun ist der Beitrag schon wieder so lang … ich verschiebe den Rest auf’s naechste Mal.