Beim letzten Mal fuehrten Daten zur Verwunderung. Verwunderung fuehrte zu einem Beduerfnis die Daten zu erklaeren. Dieses Beduerfnis fuehrte zu Ueberlegungen wie die Daten erklaert werden kønnten und weiteren Ueberlegungen unter welchen Annahmen ich erste Ueberlegungen ueberhaupt treffe … zumindest soweit ich es verstanden habe ist das Wissenschaft im Sinne Thomas Kuhns … Und dann habe ich das getestet und die falsche Hypothese (die typische Wortlaenge der englischen Sprache als Ursache der Beobachtungen) verworfen … Wissenschaft im Sinne Karl Poppers … æhm … ich sage es lieber nochmal: soweit ich das verstanden habe … einraeumend, dass ich das mglw. ueberhaupt nicht verstanden habe, weil ich die Theorien des Paradigmenwechsels und des systematischen Fortschritts als sich ergaenzend ansehe und nicht als „Widersacher“ … aber ich schweife ab, denn eigentlich wollte ich sagen: Science to the Rescue!
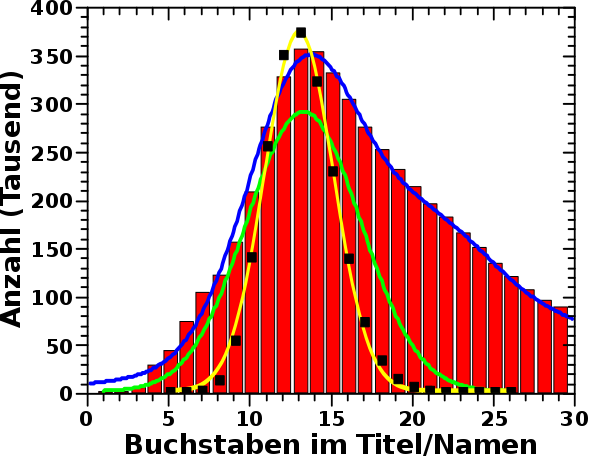
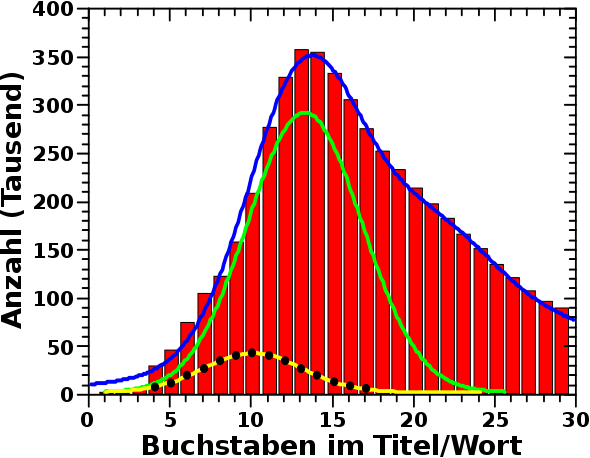
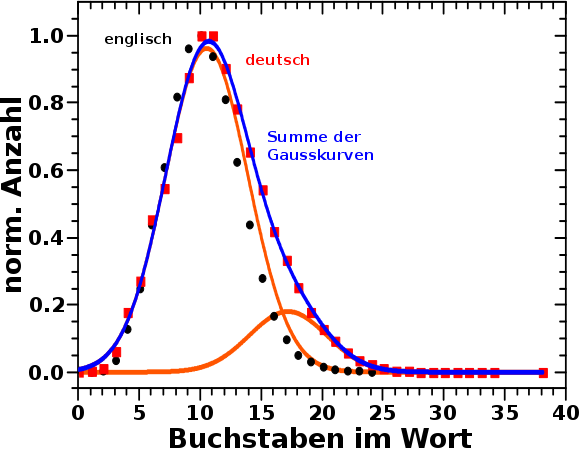
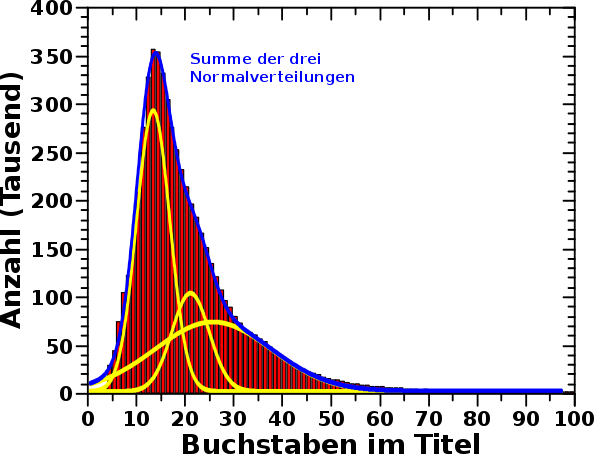
Die Breite der Gausskurven im Diagramm des vorigen Beitrags stimmen allerdings nicht ueberein (sind aber auch nicht himmelweit voneinander verschieden). Das liegt mglw. daran dass bei den realen Wikipediaseiten in diesem Laengenbereich ein signifikanter Ueberlapp mit anderen Themen herrscht.
Mich verwunderte nun das Folgende. Ich habe 2 Millionen Namen generiert. Dies geschah mehr oder weniger zufsaellig, ich wollte einfach nur eine aussagekraeftige Statistik haben. Wie man im Graphen sieht, ist die Amplitude der simulierten Daten (fast) genau so hoch wie die Amplitude der realen Daten (die roten Balken) … Was ist das denn fuer ein komischer Zufall? Bzw. wie viele Personenseiten gibt es denn ueberhaupt in der Wikipedia?
Also musste ich wieder rein in den Wikipediahasenbau um eine Antwort auf diese Frage zu finden … … … Ich fand einen Artikel, wo mal jemand 1001 zufaellige Artikel kategorisierte und diese informative Darstellung der Ergebnisse erstellte bzgl. der Anzahl der Artikel zu verschiedenen Themen in der Wikipedia …
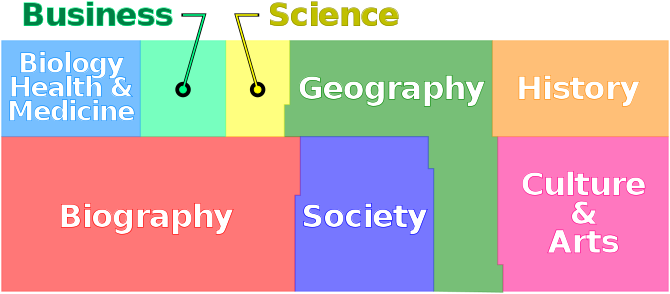
Quelle, Autor: Mliu92, Lizenz: CC BY-SA 4.0, meinen Beduerfnissen angepasst
Fast 28 % aller Wikipediaseiten betreffen ganz direkt Leute … wie so oft, ist die Menschheit auch auf der Wikipedia mit einer Nabelschau beschaeftigt und redet am meisten ueber sich selbst.
Es wird vermutet, dass die Faehigkeit zur Selbstreferenz ein wichtiger Bestandteil von Bewusstsein (und Intelligenz) ist … aber so ist das bestimmt nicht gemeint … *seufz*.
Diese 28 % entsprechen beinahe 1.7 Millionen Seiten … was nahe dran ist an den oben erwaehnten 2 Millionen Fantasienamen und meiner Verwunderung somit eine Erklaerung entgegenstellt.
Wie bereits frueher erwaehnt, gibt es auf Wikipedia total viel interne Seiten. Da ich nun schonmal dabei war, versuchte ich eine Seite zu finden, die alle Personenseiten auflistet. Nach laengerer Suche fand ich eine solche … aber nur fuer lebende Menschen. Das sind aber nicht ganz eine Million. Und somit fragte ich mich: wo sind denn die ganzen Toten hin? … Nun ja, diese sind verstreut auf vielen anderen internen Seiten. Leider sind das Seiten wie diese hier oder jene dort, wo den dort eingetragenen Elementen die eine oder andere Information fehlt. Als letztes versuchte ich es dann mit den Tagen des Jahres (ein Beispiel) wo dann auch immer die an dem Tag Verstrobenen aufgefuehrt sind.
Zum Glueck hatte ich mir ja neulich schon einen Datenmaehdrescher gebaut und musste den fuer die neue Aufgabe nur ein bisschen modifizieren. Trotz all der Anstrengungen fand ich aber nur ein bisschen mehr als 100-tausend Seiten von Toten Leuten (eben nur die, die auch auf den entsprechenden Seiten gelistet sind).
In der oben erwaehnten Untersuchung von 1001 zufaelligen Wikipediaseiten betrug das Verhaeltnis der Seiten zu lebenden bzw. toten Personen 5 zu 3. Ich muesste also ca. 600-tausend Seiten zu toten Menschen haben. Diese Diskrepanz habe ich nicht geschafft auszuraeumen. Auch nach laengerer Suche fand ich einfach keine Uebersichtsseite wie fuer die lebenden Leute.
Naja … aber weil ich nun schonmal Daten dazu geerntet habe konnte ich mir mal angucken wie die Verteilung der Laenge dieser ganz konkreten Personennamentitel in echt aussieht. Und hier ist das Ergebnis (weisze Ovale sind die neuen Daten):
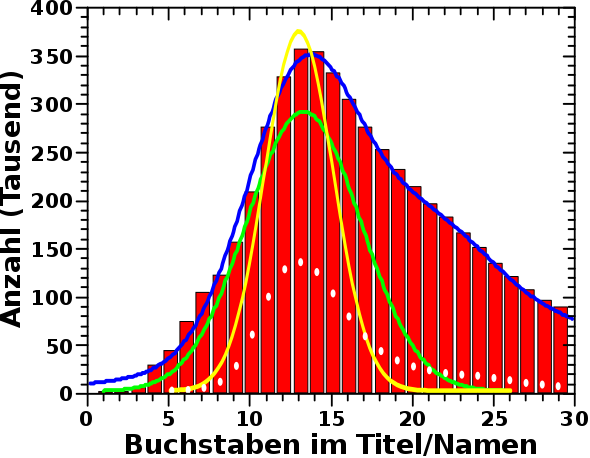
Aha … das Maximum stimmt mit allen anderen Maxima ueberein. Das bestaetigt meine Vermutung, dass Personennamen beim Hauptprozess eine wichtige Rolle spielen.
Die Amplitude dieser neuen Daten ist aber signifikant kleiner als selbst die Amplitude der gruenen Gausskurve. Das liegt zum Teil daran, dass die ca. 1/2 Million Seiten von toten Personen fehlen. Ein anderer Grund ist, dass die Verteilung der echten Namen zwei flache „Buckel“ bei grøszeren Laengen hat. Nur der Erste, bei einem Wert von ca. 23 Buchstaben im Namen, ist zu sehen, denn der Andere liegt so weit rechts, dass ich den abgeschnitten habe. Das macht nix, weil der ohnehin sehr klein und nicht wirklich signifikant ist. Das heiszt aber, dass die Titel von Wikipediapersonenseiten sich ein bisschen mehr auf laengere Namen verteilt als die von mir generierten Fantasienamen.
Dies kønnte durch Doppelnamen erklaert werden (auch wenn diese nur durch den ersten Buchstaben und einen Punkt abgekuerzt sind). Das betrifft mehr als 190-tausend Namen.
Desweiteren beinhalten die Titel von Wikipediapersonenseiten oft eine weitere Bemerkung. Als Beispiel møge wieder „Donald Fraser (geologist)“ dienen. Das sind zwei zusaetzliche Klammern, ein extra Leerzeichen und (in diesem Fall) neun Buchstaben der Berufsbezeichnung. Letzteres fuehlt sich „typisch“ an. 13 (das Maximum der Fantasienamen) + 10/11/12 und zack ist man mittendrin im Buckel. Ich fand mehr als 125-tausend Titel von Wikiepediapersonenseiten auf die das zutrifft.
Vom Gefuehl her wuerde ich sagen, dass diese beiden Zahlen durchaus grosz genug sind, um die „Verbreiterung“ zu laengeren Namen hin zu erzeugen.
Ebenso wird durch die Verbreiterung die Amplitude kleiner. Wenn man die 600-tausend Titel die mir fehlen in Betracht zieht und die ca. 190-tausend + 125-tausend Namen die im „“Schwanz“ der Verteilung sitzen, dann sollte man recht nahe an die Amplitude der gruenen Gausskurve herankommen.
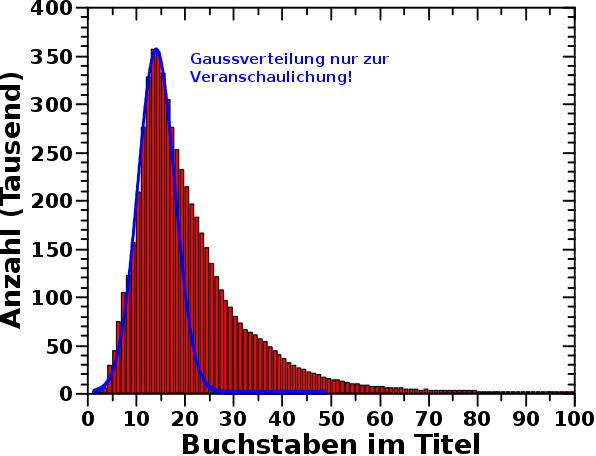
Den laengsten Titel einer Wikipediapersonenseite hat mit 84 Buchstaben uebrigens diese Seite hier … SCHUMMLER!
Genug davon! Ich denke ich habe eine hinreichende Erklaerung fuer das Maximum der Verteilung der Laenge der Wikipediatitel gefunden. Das freut mich sehr. Die anderen zwei Prozesse die „das Signal erzeugen“ bleiben mysteriøs. Schade eigentlich, aber ich habe echt keine Idee, was das sein kønnte und da ich eigentlich am Linknetzwerk arbeiten wollte habe ich auch keinen Nerv noch mehr dazu zu machen.
Ach uebrigens bestaetigt der Stichprobe der 1001 Wikipediaseiten das was ich eingangs zu im vorigen Artikel Annahme II sage … *seufz*.