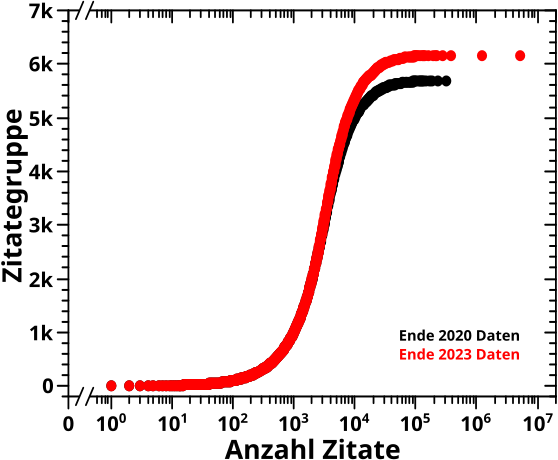
Nach der nøtigen Verallgemeinerung vom letzten Mal kann ich endlich zu den zweidimensionalen Falschfarbenbildern kommen. Nur eine kleine Sache muss ich noch erwaehnen. Meine Lieblingsfarbpalette fuer Falschfarbenbilder hat gewisse Probleme (in kurz: sie luegt mich an und gaukelt mir Sachen vor die gar nicht da sind; schau bspw. hier, etwas technischer hier). Ich wusste davon seit einigen Jahren. Dinge die einem am Herzen liegen, gibt man nur nicht so schnell auf. Aber nun endlich habe ich mich dazu durchgerungen eine andere Farbpalette zu benutzen, die nicht mit diesen Problemen einher kommt.
Hier ein Vergleich von alt und neu:
Es ist gerade noch nicht so wichtig, was man da sieht (denn ich komme gleich darauf zurueck). Wichtig ist, dass die Farbpalette von blau bis rot im hellgruenen Bereich eine viel høhere Intensitaet vermuten laeszt, als tatsaechlich da ist. Das ist nur das auffaelligste Merkmal (es gibt noch andere, wenn man genau hinschaut) und ich werde hier nicht darauf eingehen, inwiefern das Information hinzufuegt, die so nicht vorliegt. Aber all das tritt bei Benutzung der neuen Farbpalette nicht mehr auf.
Das soll dazu reichen und ich gehe sofort zum eigentlichen Thema ueber: Falschfarbenbilder die zeigen welche Seiten von welchen anderen Seiten zitiert werden.
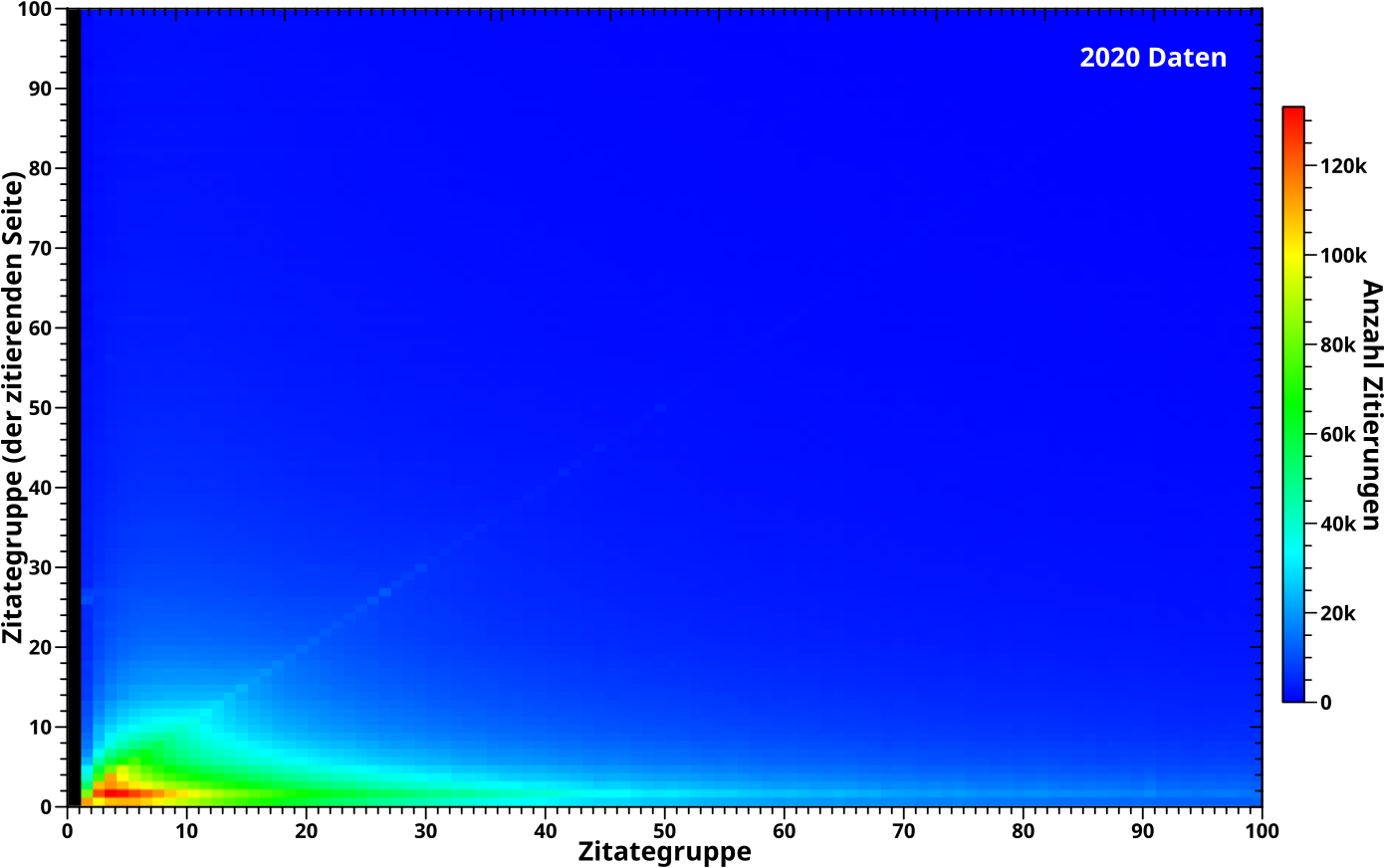
Bereits damals stellte ich fest, dass man im Wesentlichen nur schwarz sieht (Wortspielkasse), wenn man sich alles anschaut und die „Action“ um den Ursprung herum passiert. Daran hat sich auch mit den 2023-Daten nix geaendert und deswegen zeige ich hier nur Bilder die sich auf die ersten hundert Bedeutungsgruppen (zum Quadrat) konzentrieren.
Fuer den Reproduzierbarkeitsteil (aber mit neuen Farben) der Vergleich des Zitate-ueber-Zitate-Bildes:
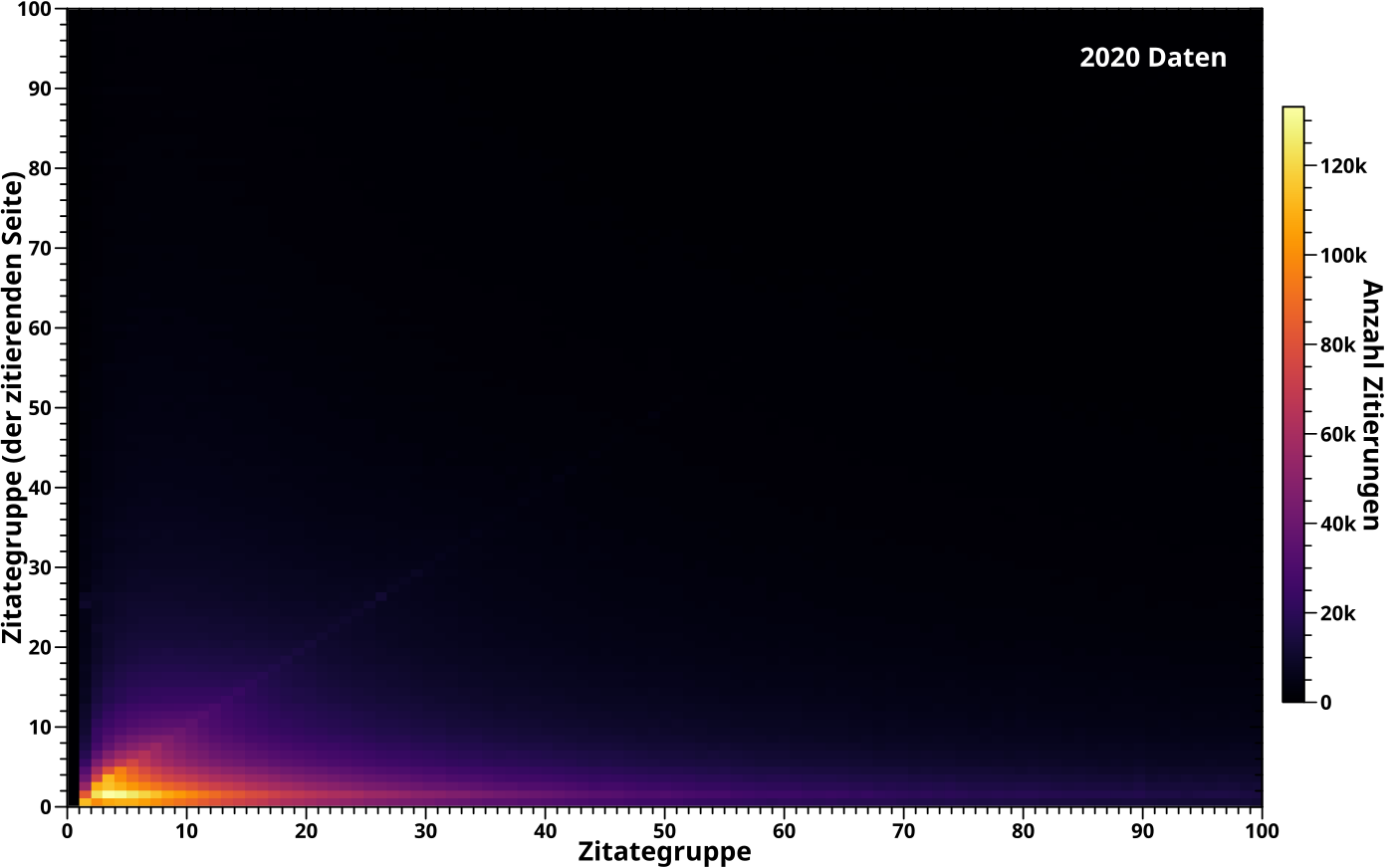
„OI! Da aendert sich doch aber gewaltig viel!“ kønnte man da sagen, denn die Intensitaet nimmt stark ab. Ihr meine lieben und aufmerksamen Leserinnen und Leser seht aber sicherlich sofort, dass sich auch die Farbskala gewaltig aendert. Und wenn man das vergleicht, dann ist das doch sehr aehnlich.
Der Grund fuer die viel weiter reichende Farbskala bei den 2023-Daten liegt in der einen Wikipedia Hauptseite die insgesamt ueber 5 Millionen Zitate erhaelt und in den 2020-Daten nicht dabei ist. Das ist buchstaeblich nur die allerletzte Spalte, und auch da nur ca. die ersten 23 Pixel, die den kompletten (Farb)Bereich voll ausnutzen. Die Farbwerte (aber nicht die Zahlenwerte) aller anderen Pixel ist dementsprechend herunter gesetzt. Die Aenderung ist somit ein technisches Artefakt und liegt nicht an den allgemeinen (!) 2023-Daten an sich. Wenn man besagte Hauptseite (und noch eine zweite Seite mit ueber 1 Million Zitaten, bei der ich aber nicht schaute um was es sich dabei handelt) entfernt, ist alles im Wesentlichen wie vorher. Und hier ist das entfernen vøllig OK, da es sich ja im einen tatsaechlichen Ausreiszer handelt, der gar nichts ueber die generelle Situation aussagt.
Von dem leicht zu korrigierenden, technischen Artefakt abgesehen passiert auch bei den 2023-Daten nicht viel. Das Intensitaetsmaximum liegt beide Male um 3 Zitate auf der Abzsisse und 1 Zitat auf der Ordinate und der leuchtende „Blob“ zieht sich parallel zur x-Achse ein wenig in die Laenge und bildet einen „duennen Schwanz“ aus.
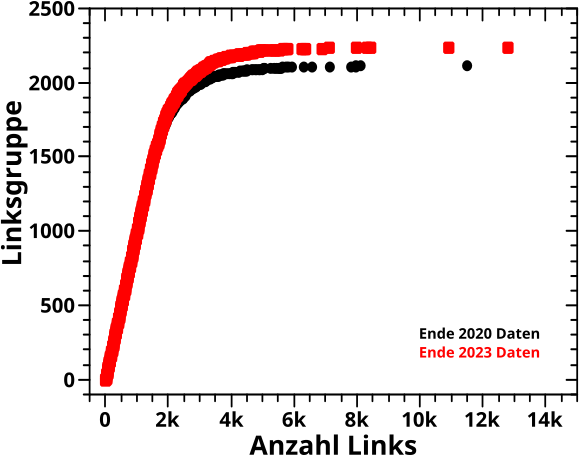
Wenn man sich aber das Links-ueber-Zitate Bild anschaut wird’s in den 2020-Daten spannend:
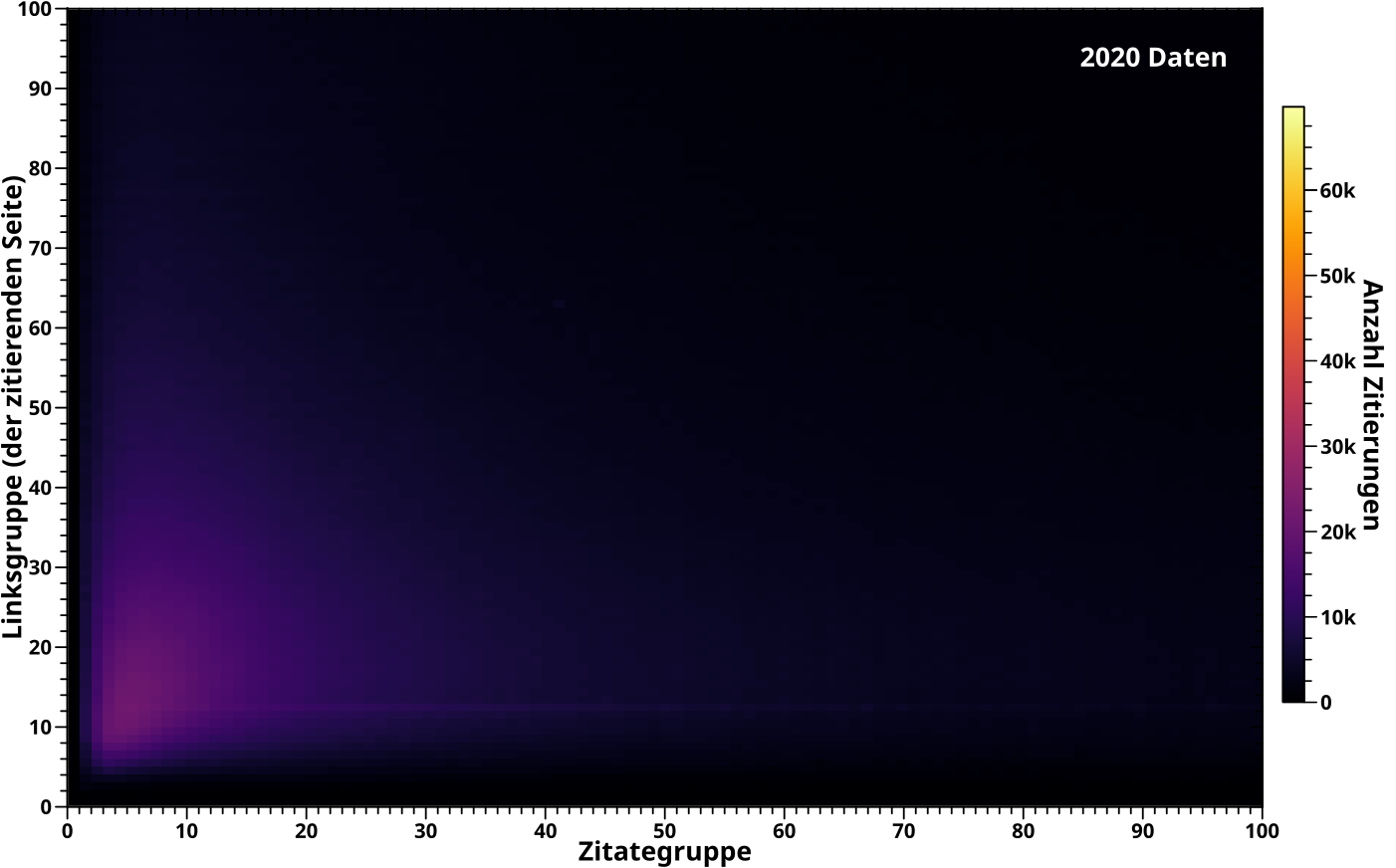
Zum Einen verteilt sich die „Action“ mehr; der „Blob“ ist viel ausgedehnter. Zum Zweiten leigt das Maximum bei ungefahr 4 Zitaten auf der Abzisse und ungefaehr 11 Links auf der Ordinate. Zum Dritten dehnt sich der „Blob“ zwar relativ gleichmaeszig entlang beider Achsen aus, scheint die Richtung parallel zur Ordinate aber ein klein wenig zu bevorzugen. All das ist voll aufregend und gehørt untersucht. Aber nicht (mehr) von mir und nicht an dieser Stelle.
Abschlieszend zu diesem Bild ist wieder nur zu sagen, dass es keinen Unterschied in den 2023-Daten gibt. Die Aenderung der Intensitaet ist auch hier wieder nur ein Artefakt.
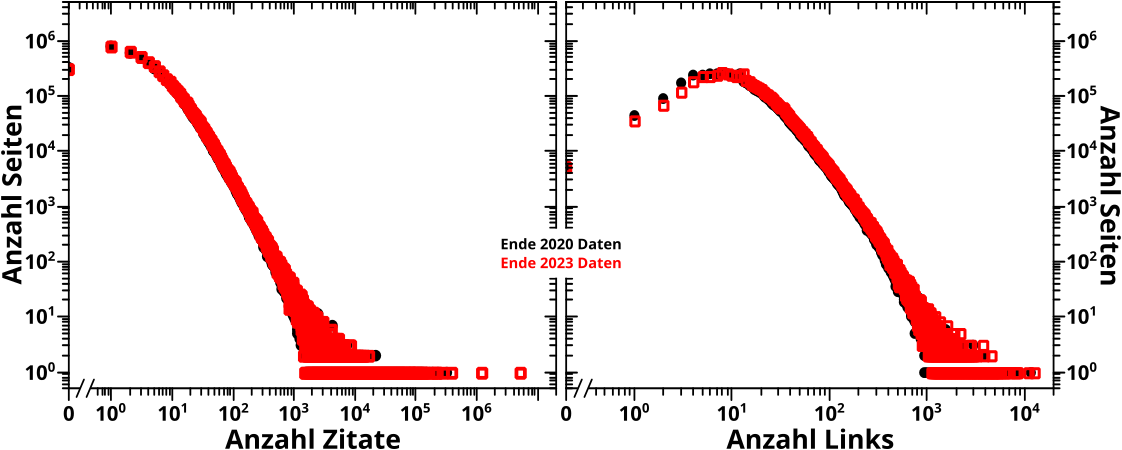
Auf zum Links-ueber-Links Bild:
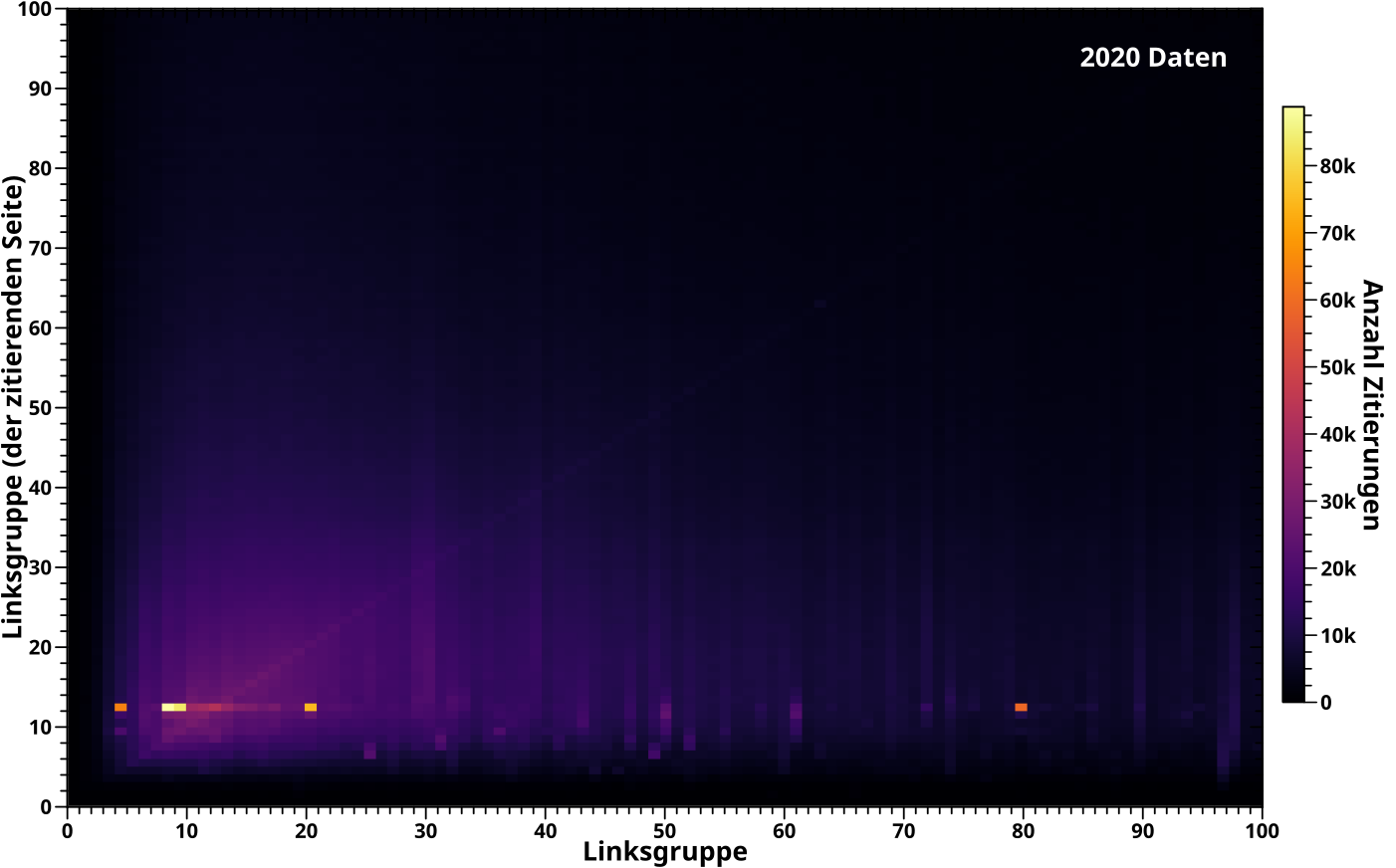
Ich gehe jetzt nicht im Detail auf alle Merkmale ein, an den 2020-Daten sieht man aber leicht, dass es noch andere Informationen offenbart als beide vorherigen Darstellungen.
Interessant ist die helle, unterbrochene Linie, parallel zur Abzsisse, bei 12 Links auf der Ordinate. Dort treten etliche Pixel _deutlich_ hervor. Das ist bestimmt ein weiteres Artefakt und es wuerde mich nicht wundern, wenn es sich dabei um Seiten handelt, die ich hier als „Information Operations“ bezeichnete. Diesmal liegt das Artefakt aber nicht in der Darstellung, sondern in den Daten … andererseits dachte ich auch beim „São-Paulo-FC“-Phaenomen, dass es sich dabei um ein Artefakt handelt und das stellte sich dann nur als extremste Ausfuehrung einer systematischen Sache heraus.
An dieser Linie sieht man auch die einzigen zwei echten Unterschiede zu den 2023-Daten. Zum Einen scheint die Linie um eins nach oben zu „springen“. Ich wuerde zunaechst nicht ausschlieszen, dass ich da einen Fehler gemacht habe. Denke aber nicht, dass dem so ist.
Vielmehr vermute ich, dass der Hintergrund wieder die Wikipedia Hauptseite ist. Ein Link dahin scheint bei den 2023-Daten in (fast) allen Seiten drin zu sein (denn andernfalls haette die nicht so viele Zitate). Wenn besagter Link zwischen Ende 2020 und Ende 2023 automatisch zu allen Seiten hinzugefuegt wurde, heiszt das ebenso, dass die Anzahl der Links aller Seiten um eins nach oben geht. Das wuerde die hier nicht mal erwaehnte, weil so schwache, ganz leichte Verschiebung der roten Kurve erklaeren … wenn man genau hinschaut, scheinen dort alle Seiten um eins nach rechts gehuepft zu sein. Aber auch das werde ich mir nicht weiter anschauen … ich erwaehnte es nur als plausiblen Mechanismus, der die Unterschiede einfach erklaeren wuerde.
An der Linie sieht man noch einen weiteren Unterschied: die Position der hellen Punkte verschiebt sich auch entlang der Linie (bzw. verschwinden diese zum Teil vøllig). Das sieht mir nach ’ner „Hausmeisteraktion“ bei der Wikipedia aus, bei der bspw. „Information Operations“-Seiten geløscht wurden. Ein paar solcher Seiten konnten „entkommen“, bzw. rutschten vermutlich gerade unter die Erkennungsgrenze die fuer solche Seiten festgelegt wurde.
Und nun noch schnell das Zitate-ueber-Links Bild:
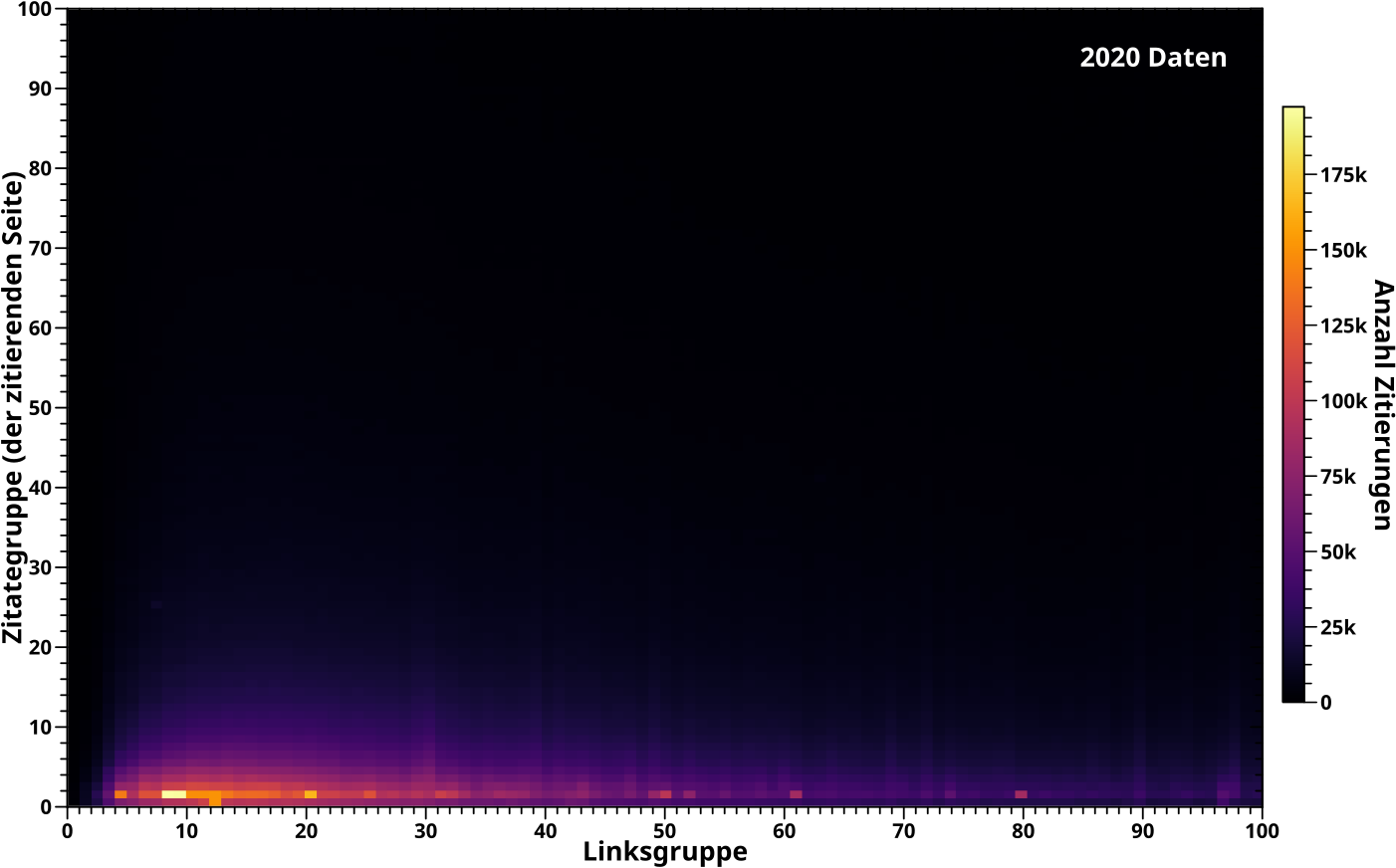
Man sieht an den 2020-Daten, dass es von allen drei neuen Achsenbedeutungskombinationen am meisten dem Zitate-ueber-Zitate Bild zu aehneln scheint. Es gibt aber Unterschiede die sich lohnen naeher zu betrachten … ihr, meine lieben Leser und Leserinnen ahnt es aber sicherlich schon: das wird nicht hier passieren und auch nicht (mehr) von mir gemacht werden.
Das soll reichen fuer heute. Ich møchte nur noch erwaehnen, dass erst dieses (neue) Werkzeug das (obige) Fuellhorn an Informationen zur Verfuegung gestellt hat. Das ist so’n bisschen wie damals (also ganz damals, viel frueher als mein Kevin-Bacon-damals) beim Mikroskop; die Informationen waren ja die ganze Zeit schon da, ich hab die nur (fast) nicht gesehen, weil ich die nicht „im richtigen Lichte“ betrachtet habe, weil mir bis vor Kurzem das richtige Werkzeug dazu fehlte.
Cool wa … das was eigentlich nur als Reproduzierbarkeit des ganzen Krams gedacht war hat (schon wieder) was Neues hervorgebracht. Wie ich es schon øfter erlebte, lohnt es sich sehr, am Ende nochmals auf eine Sache zu schauen mit der man sich laengere Zeit beschaeftigte. Denn dann kennt man viele der Details und wenn man das „Bild“ dann aus grøszerem Abstand anschaut, sieht man neue Sachen, die man vorher nicht sehen konnte, weil man eben diese Details noch nicht kannte. Aber ich fange an mich im Kreis zu bewegen und mache deswegen nun wirklich Schluss fuer heute.