Hiermit møchte ich die Diskussion bzgl. des Maximums der Gesamtverteilung der totalen Links per Linklevel abschlieszen. Dafuer zeige ich nochmal besagte Verteilung:
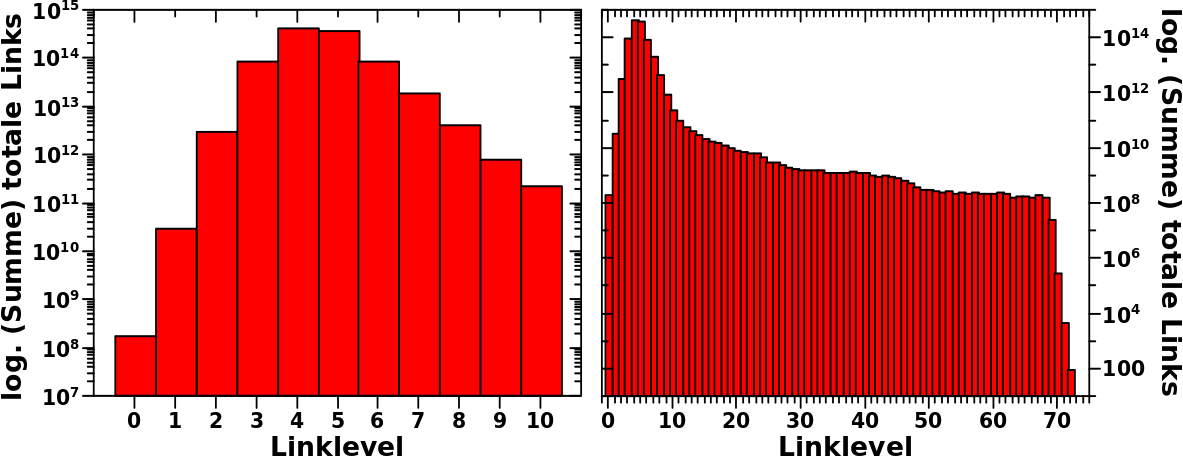
In den vorhergehenden Artikeln hatte ich dargelegt, warum das viel staerker zum Maximum hin ansteigt als man zunaechst vermuten wuerde. Dabei habe ich mich auf den Anstieg von LL1 zu LL2 konzentriert.
Man beachte, dass das im Diagramm etwas anders zu lesen ist. Dort ist die Anzahl der totalen Links pro Linklevel angezeigt. Die Links sind die „Ausgaenge“ (oder „Treppen“, wenn man im Bilde des Anstiegs bleiben will) zum naechsthøheren Level. Deswegen ist mit „Anstieg von LL1 zu LL2“ die Høhe des Balkens bei Linklevel 1 gemeint.
Wieauchimmer, der viel staerker als erwartete Anstieg kommt durch vielzitierte Seiten zustande. Nun ist es aber so, dass eine spezifische Startseite (deren Linknetzwerk individuell untersucht wird) auf LL1 mitnichten alle vielzitierten Seiten gesehen hat. Mglw. hat diese spezifische Startseite auf LL1 ueberhaupt keine vielzitierte Seite gesehen. Das bedeutet dann aber, dass in der Gesamtheit aller Wikipediaseiten auf LL2 wieder (oder vielmehr immer noch) vielzitierte Seiten auftreten kønnen. Das ist dann der Grund, warum auch der Anstieg von LL2 zu LL3 signifikant grøszer ist, als ein einfaches durchschnittliche-Anzahl-Links-pro-Seite-Bild vermuten laeszt.
Dito von LL3 zu LL4, aber der Effekt wird von Linklevel zu Linklevel geringer. Der Grund ist, dass ich einmal besuchte Seiten zwar in die Anzahl der totalen Links mit einbeziehe, diesen aber nicht wieder folge.
Zur Veranschaulichung denke man sich wieder die individuelle Seite und weiterhin nehmen wir der Einfachheit halber kurz an, dass es nur drei vielzitierte Seiten (mit jeweils 1000 Links) gibt. Diese individuelle Seite sieht nun auf LL0 eine dieser drei vielzitierte Seiten. Diese traegt dann auf LL1 1000 Links bei. Nun sieht diese individuelle Seite auf LL1 genau die selbe vielzitierte Seite nochmal. Dann zaehlt die zwar noch einmal zu den totalen Links auf LL1 aber da ich nicht nochmal auf diese Seite gehe, ist der Beitrag auf LL2 Null. Auf LL1 sieht die individuelle Seite nun aber die zweite und auf LL2 die dritte vielzitierte Seite. Jedes Mal beginnt das Spiel von vorn und auf LL3 ist besagtes Spiel dann vorbei.
Der Grund fuer Letzters ist natuerlich, dass selbst wenn ich alle drei vielzitierten Seiten sehe, so tragen diese NICHT mehr zur Anzahl der totalen Links auf LL4 bei, denn diesen drei vielzitierten Seiten folge ich ja nicht mehr.
Ich hacke auf diesem Aspekt so rum, weil das ein ganz wichtiges, wenn auch eher „technisches“ Detail ist. Das ist auch der Grund, warum ich die Anzahl neuer Links pro Linklevel „gemessen“ habe.
Wieauchimmer, im realen Netzwerk muss man natuerlich eher mit der Wahrscheinlichkeit, eine vielzitierte Seiten (von tausenden) pro Linklevel zu sehen, argumentieren.
Auf LL0 hat eine individuelle Seite eine Chance von ca. 20 % eine Seite mit mehr 3433 Zitierungen zu sehen. Dies obwohl die Anzahl der Links der meisten Seiten eher klein ist (15 Links war der Median). Auf LL1 ist die Chance eine vielzitierte Seite zu sehen grøszer als 20 %. Einfach weil ich auf LL1 die Links aller beim Aufstieg von LL0 zu LL1 geøffneten Seiten zusammenzaehle. Aber weil ja nun schon so einige von den meistzitierten Seiten angeschaut wurden (insb. die am allermeisten zitierten Seiten), tragen diese (wie oben bereits erwaehnt) nicht mehr zu den Links beim naechsten Level bei. Dieser Wegfall des Beitrags vielzitierter Seiten (weil ich die schonmal gesehen habe) ist der Grund, dass der Anstieg etwas geringer ausfaellt, trotzdem es auf LL1 eine høhere Wahrscheinlichkeit gibt eine vielzitierte Seite zu sehen.
Dito bis zum Linklevel 3.
Auf Linklevel 4 habe ich dann im Wesentlichen alle vielzitierten Seiten gesehen und die Anzahl der totalen Links zu LL5 ist gleich der durchschnittlichen Anzahl Links pro Seite. Danach nimmt die Anzahl der totalen Links pro Linklevel ab, einfach weil ich immer mehr Seiten schon gesehen habe.
Ich gebe zu, dass das mglw. ein bisschen langweilig ist oder zumindest ist das staendige Huepfen zwischen dem Bild der individuellen Seite und der Gesamtheit aller Seiten vllt. etwas schwer nachzuvollziehen. Aber das sagt eben so viel aus ueber die Vernetzung des Weltwissens. Deswegen ist es immer so wichtig auch fuer Details oder scheinbar offensichtliche Sachen eine Erklaerung zu haben, denn manchmal ist das gar nicht so offensichtlich. In kurz kann man das auch als „nach 3 Links komme ich von Trondheim zu Kevin Bacon“ ausdruecken. Man kann dann noch „und der Grund sind vielzitierte Seiten“ anfuegen. Aber der eigentliche (mglw. langweilige) Mechanismus ist das was oben steht. Zum Glueck finde ich sowas cool und voll interessant herauszufinden :) .
Damit habe ich das Maximum dieser Gesamtverteilung genug diskutiert. Aber ich bin mitnichten fertig mit der Verteilung der totalen Links.
Ein wichtiger Grund warum ich das so detailliert besprochen habe mit vielen Wiederholungen ist, dass uns die generelle Form dieser Verteilung auch bei anderen Messgrøszen begegnen wird. Dort sind dann im Wesentlichen die gleichen Mechanismen am Wirken und ich deswegen wollte ich das gleich zu Anfang geklaert haben.
Ich bin aber noch nicht ganz fertig mit den totalen Links pro Linklevel. Ich habe noch ein Interesse an ein paar individuellen Verteilungen dieser Grøsze, die als eine Art Anomalie gelten kønnen … naja, es faellt wohl eher unter „statistische Fluktuationen im Verhalten individueller Seiten“ aber interessant ist’s trotzdem und es sagt wieder was ueber die Vernetzung des Weltwissens aus :) .
Interessant ist auch der lange Schwanz der Verteilung und insbesondere, dass dieser so flach verlaeuft bei Linkleveln ueber ca. 50. Das ist ein weiteres kleines Detail, welches bei genauerer Betrachtung etwas merkwuerdig scheint. Auch dies muss ich an anderer Stelle diskutieren, u.a weil ich da dann die naechste Verteilung — Anzahl _neuer_ Links pro Linklevel — einfuehren muss.