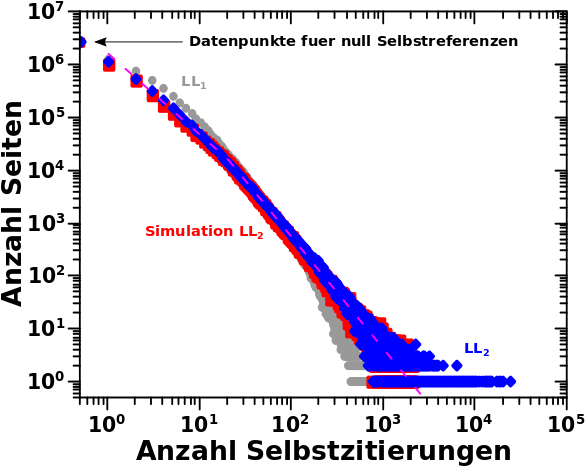
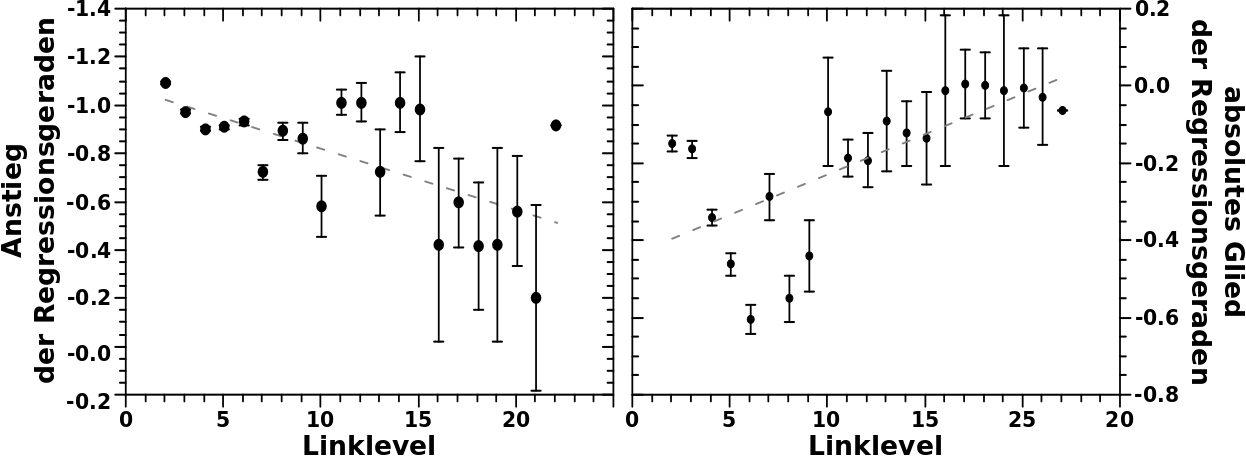
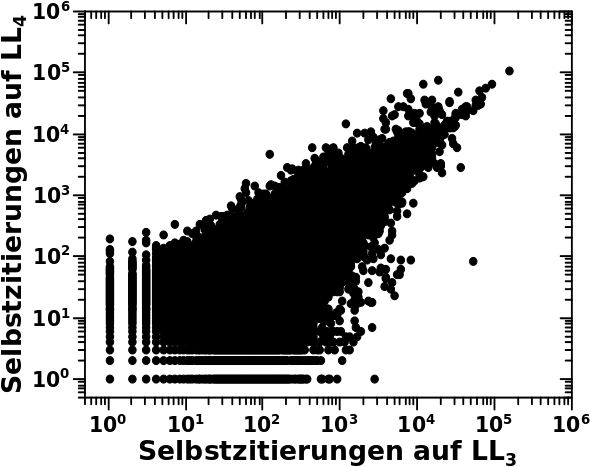
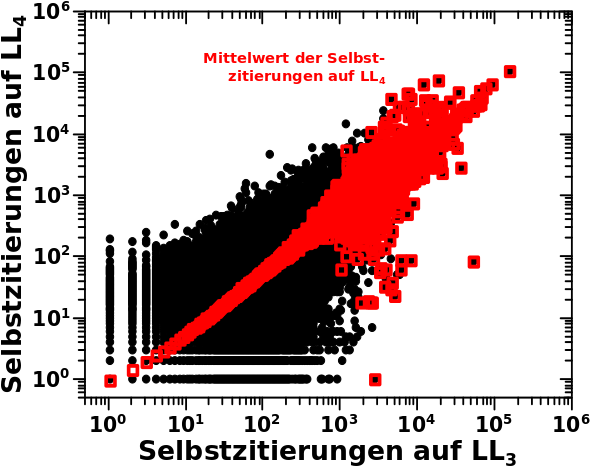
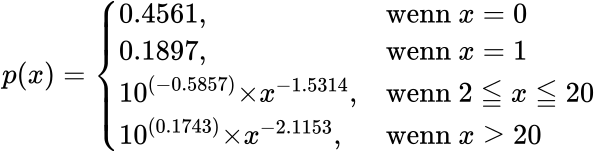Bei der Simulation hat man gesehen, dass diese systematisch zu zu hohen Werte fuehrt. Zum Einen lag das daran, dass die Parameter besagter Entwicklung konstant gehalten wurden. Die Entwicklungsparameter wiederum entsprechen der Regressionsgeraden und diese ist im Wesentlichen der Mittelwert zu einer gegebenen Anzahl an Selbstreferenzen. Das ist nicht falsch und funktioniert, wie beim letzten Mal diskutiert, im Mittel gar nicht so schlecht. Aber dieser Mittelwert entsteht aus einem „Blob“ an Datenpunkten.
Oder anders an einem Beispiel: in der Simulation wird fuer jede Seite die auf LL4 zehn Selbstzitierungen hat berechnet, dass diese den Schritt zu LL5 macht und dort dann oben erwaehnten Mittelwert an Selbstzitierungen annimmt. Hier treffen also zwei Dinge zusammen: jede einzelne Seite macht zwingend (!) den Schritt zum naechsten Linklevel und jede Seite hat dort die gleiche Anzahl an Selbstzitaten.
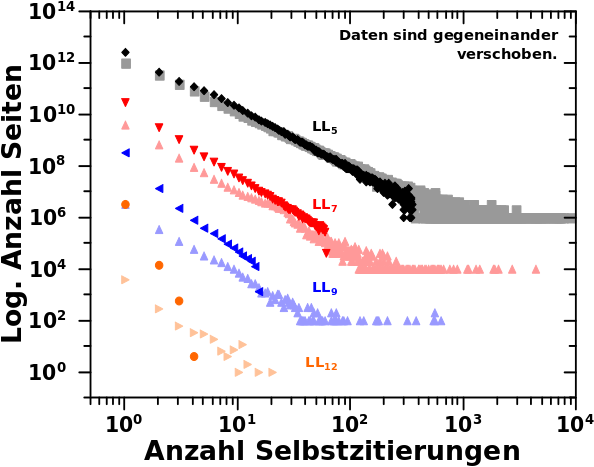
In Wahrheit sieht die Verteilung der Selbstzitate auf LL5 fuer alle Seiten die auf LL4 zehn Selbstreferenzen hat aber so aus:
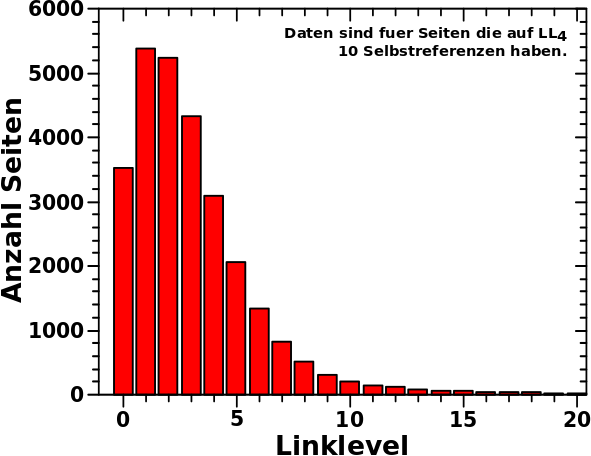
Das ist also eine Verteilung um den Mittelwert (aber keine Normalverteilung). Der (nicht aus den gewaehlten Entwicklungsparametern sondern hier genau berechnete) Mittelwert fuer 10 Selbstreferenzen auf LL4 fuehrt zu einem Wert von ca. 3 Selbstreferenzen auf LL5 und „ueberhøht“ somit das „mittlere Verhalten“ einer Seite. Letzteres deswegen weil, wie man am obigen Diagramm sieht, dass die Haelfte dieser Seiten zwei oder weniger Selbstreferenzen auf LL5 haben. Der ziemlich grosze Unterschied (hier 50 %!) zwischen Median und Mittelwert wird beim naechsten Beitrag nochmal wichtig.
Eigentllich muesste man diese Verteilung in die Simulation einbauen. Aber dafuer muesste man fuer jedes Linklevel und fuer jede Anzahl an Selbstreferenzen diese Verteilung ermitteln, analysieren und dann modellieren fuer die Simulation. Ersteres ist an sich gar nicht so schwer, denn das kann automatisiert werden. Zweiteres ginge prinzipiell auch noch. Die Betonung liegt auf „prinzipiell“, denn dabei handelt es sich sicherlich um Tausende von Verteilungen. Desweiteren nehme ich an, dass die aus der Analyse herausfallenden Parameter signifikant streuen. Womit man wieder in der gleichen Situation wie bei der Bestimmung der letztlich benutzten Entwicklungsparamter ist und dann mglw. doch wieder nur alles (unzureichend?) vereinfachen muesste. Deswegen spare ich mir das lieber gleich.
Eine andere Sache die bereits erwaehnt wurde ist aber viel einfacher zu korrigieren: Seiten deren Kette an Selbstreferenzen gebrochen ist, die also null Selbstreferenzen auf dem naechsten Linklevel haben, kønnen „rausfliegen“. Das waere sogar eine Korrektur mit „langfristiger“ Wirkung. Nicht nur tragen solche „ausgestiegenen“ Seiten faelschlicherweise zum Signal auf dem naechsten Linklevel bei, sondern auch bei den Linkleveln die danach kommen. Wie man am obigen Diagramm sieht, kann es sich mitunter um eine signifikante Menge an „Aussteigern“ handeln und deren Bezug auf eine sich erhøhende Diskrepanz zwischen gemessenen und simulierten Werten ist leicht einzusehen.
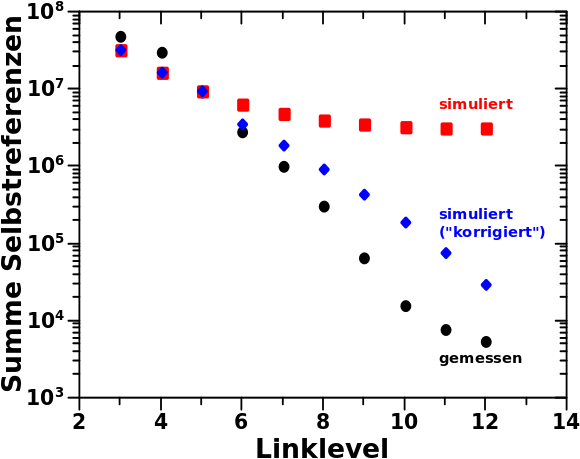
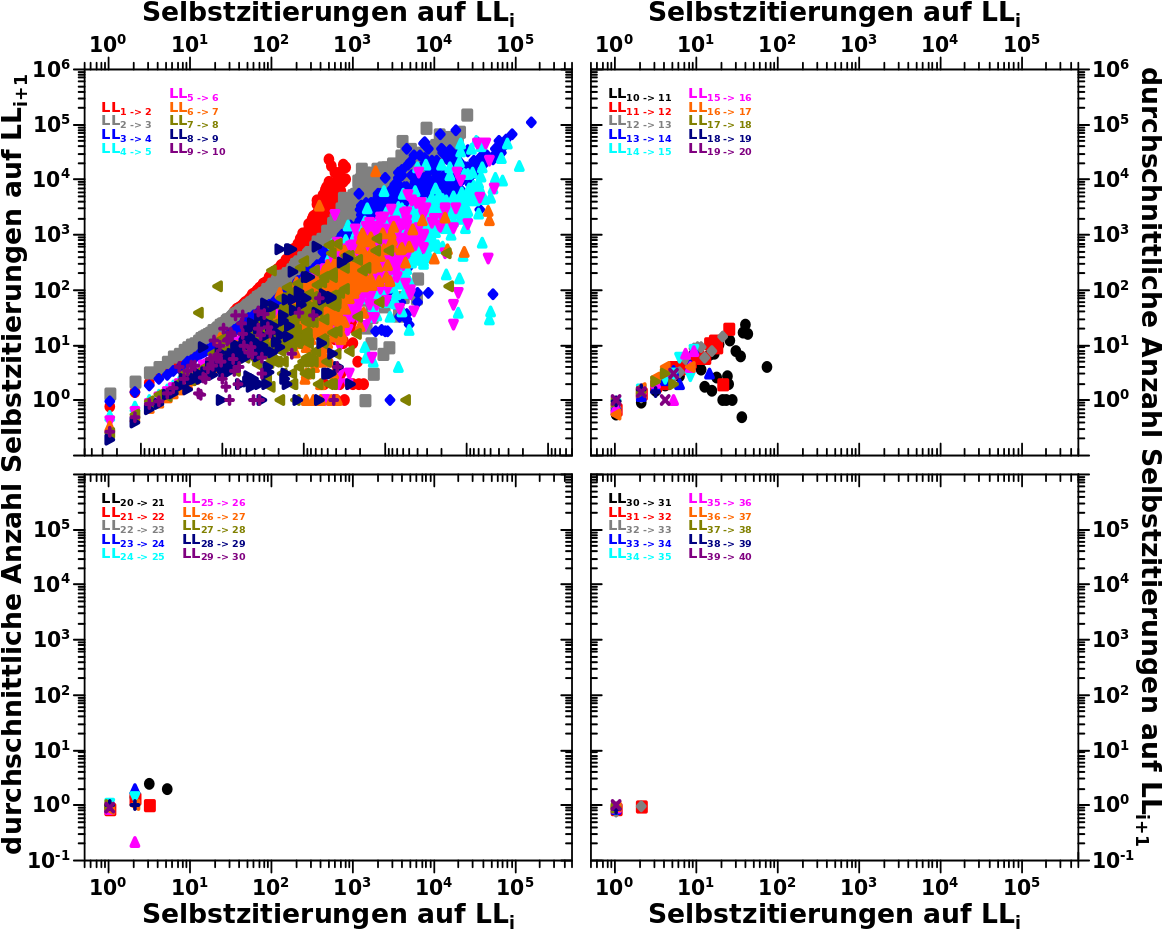
Deswegen habe ich hier im linken Diagramm mal aufgetragen, wie viele Seiten pro Linklevel aussteigen:
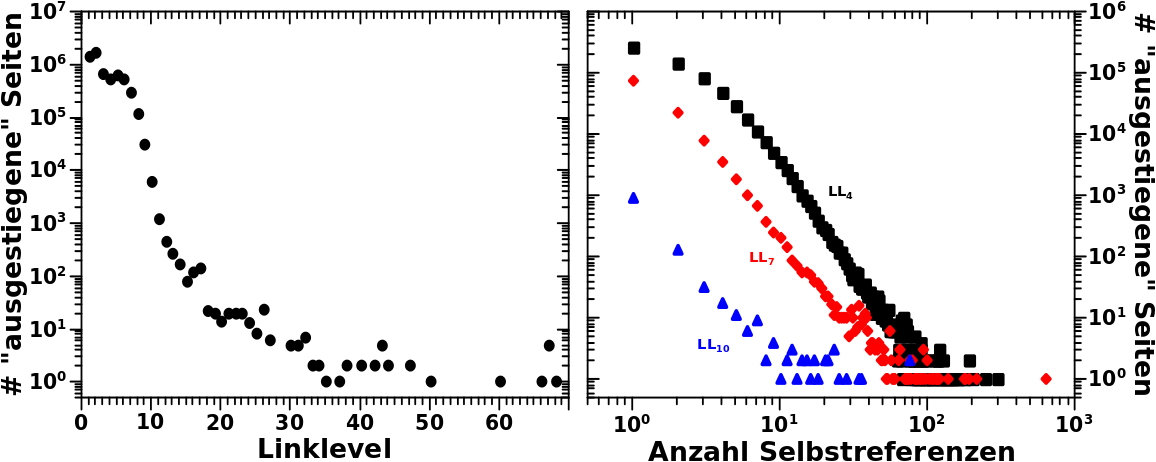
Das sind ja insbesondere auf den ersten Linkleveln ganz schøn viele! Selbst unter dem Aspekt, dass es mich bis LL3 nicht kuemmert, denn die bis dahin ausgestiegenen Seiten wurden in der Praeparierung des Ausgangszustands beruecksichtigt.
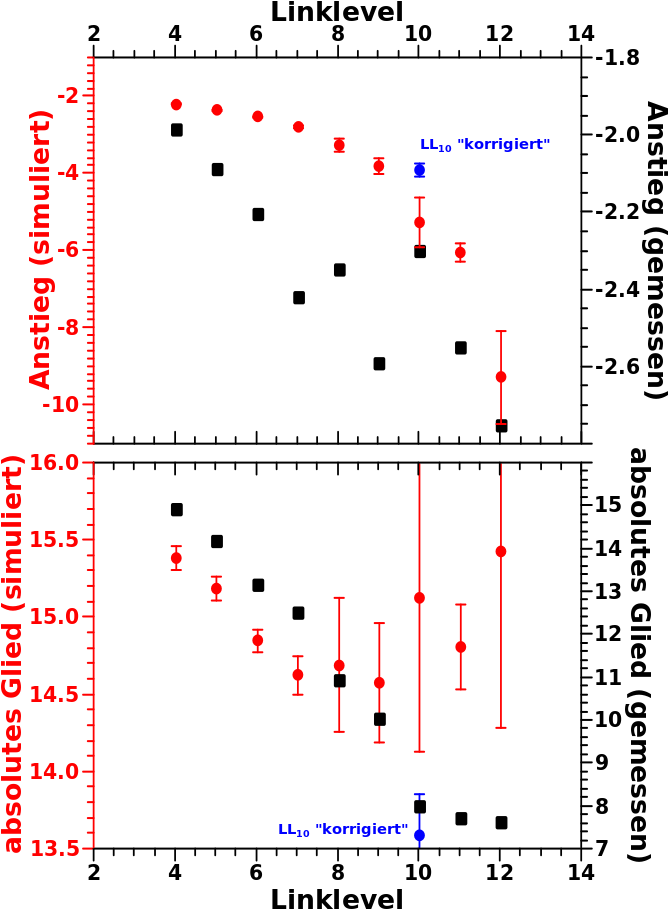
Nun ist aber die Anzahl der aussteigenden Seiten nicht nur vom Linklevel sondern auch von der Anzahl der Selbstreferenzen auf diesem Linklevel abhaengig. Dieser Sachverhalt ist an drei Beispielen im rechten Diagramm gezeigt. Wie zu erwarten war, steigen (deutlich) mehr Seiten mit wenigen Selbstreferenzen auf einem gegebenen Linklevel auf, als solche mit vielen Selbstreferenzen. Aber wenn man diese Information pro Linklevel hat, dann kann man sich an eine Korrektur machen.
Dazu komme ich aber erst beim naechsten Mal.
Ach so, eine letzte Sache noch. Bei diesen Grafen kann (und soll) Doppelzaehlung auftreten.
Ein Beispiel: Wenn fuer eine Seite die Kette von Selbstreferenzen auf LL3 abbricht, so steigt diese auf LL3 aus. Man nehme nun an, dass auf LL5 und LL6 (aber nicht danach) jeweils eine weitere Selbstreferenz auftritt. Dann hat man eine neue Kette, die auch wieder abbricht. Somit steigt diese Seite zwei Mal aus und wird entsprechend doppelt gezaehlt.
Aber ich nehme an, dass diese Mehrfachaussteiger insgesamt nicht sehr zahlreich sind und deshalb nicht all zu sehr ins Gewicht fallen werden. Der Grund liegt darin, dass man sich thematisch immer schneller von der Ursprungsseite entfernt und es sehr schnell unwahrscheindlich wird eine Selbstreferenz zu erhalten (und somit neue Ketten aufzubauen).
Mit einer Ausnahme: sehr fruehe Linklevel und wenn es sich nur im eine (reaktivierte) Selbstreferenz handelt. Aber diese sind bei der Korrektur der Simulation nicht all zu sehr von Interesse, denn zum Einen ist der Ausgangszustand fuer die Simulation erst bei LL3 und dass die Simulation ein Problem mit zu vielen einfachen Selbstreferenzen hat ist bekannt und an entsprechender Stelle bereits diskutiert worden.