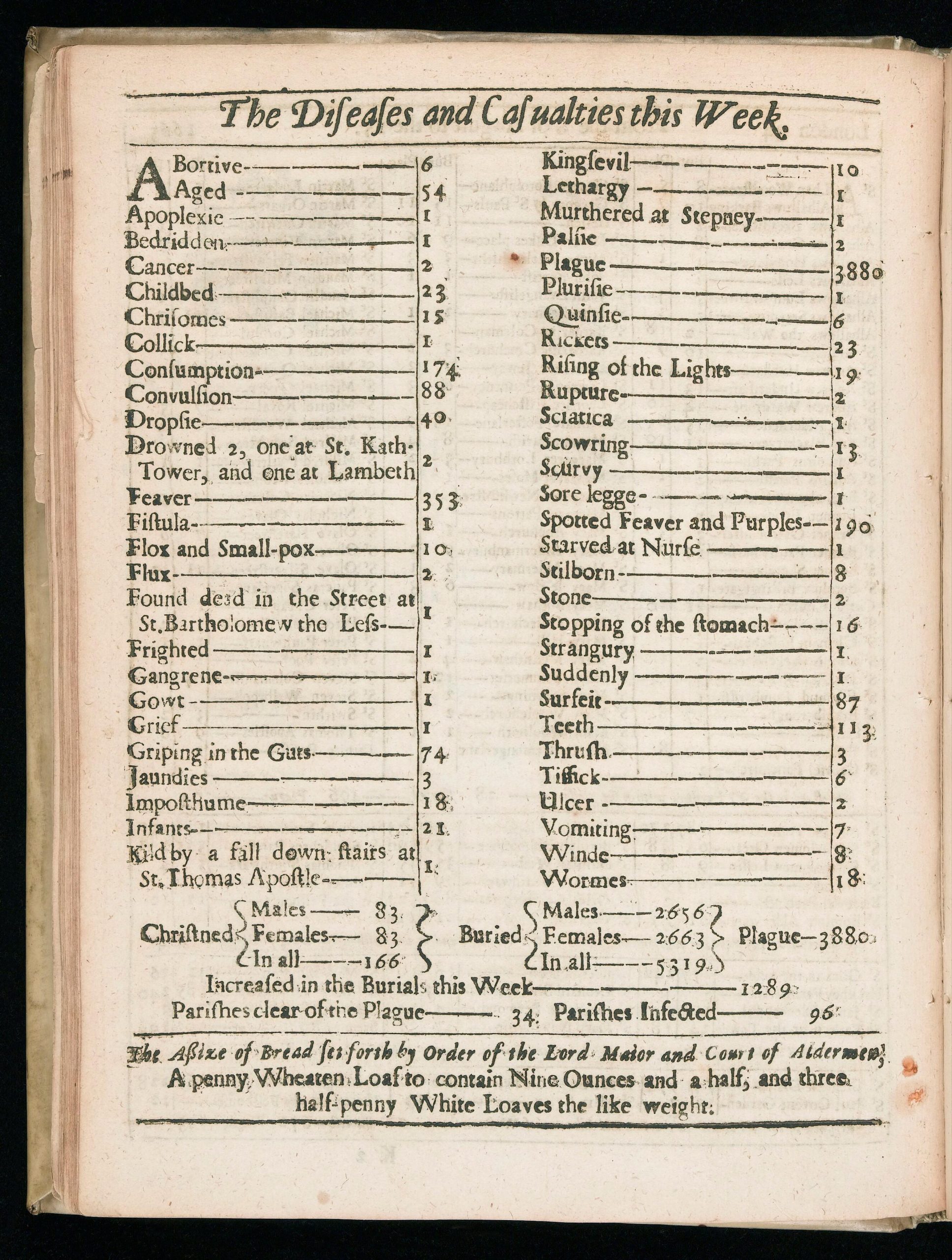
Geburtstagsbeitrag! Und wieder einmal schreibe ich ueber ein Thema, welches vermutlich nicht interessant ist fuer den Rest der Menschheit, aber was mich schon laenger beschaeftigt.
Dieses Mal geht es darum, dass es vielleicht der letzte Geburtstagsbeitrag ist. Hoffentlich nicht weil ich bald sterbe, sondern weil ich schon seit Jahren immer wieder mit dem Gedanken spiele mit dem Weblogschreiben aufzuhøren. Der Grund liegt darin, dass ich das jetzt 15 Jahren mache und das doch relativ viel meiner Zeit braucht.
Aber relativ viel Zeit brauchte es schon immer und schon seit Jahren denke ich mir zwar ein Publikum wenn ich einen Beitrag schreibe, bin mir aber bewusst, dass hier (fast?) niemand mehr liest … der Zeitaspekt kann also nicht der einzige Grund fuer diese Gedanken sein.
An der Stelle wuerde ich jetzt „Aber der Reihe nach“ schreiben … nur gibt’s diesbezueglich keine Reihe. Dies ist eher ein „Work in Progress“ als ein logisch und konsistent ausgearbeitetes Gedankengebaeude (weswegen es ganz hervorragend als Geburtstagsbeitrag passt). Es sind also Spruenge in den unten angesprochenen Themen zu erwarten.
Angefangen habe ich urspruenglich um die in Dtschl. gebliebenen Bekannten auf dem Laufenden zu halten wie das so in Norwegen ist. Das wurde aber schnell „alt“.
Im Nachhinein sehe ich, dass ich zu dem Zeitpunkt bereits in einer „Periode der wilden Entdeckungen“ war, welche meine persønliche Entwicklung _MASSIV_ vorantrieben. Die zwei groszen Stichworte sind hierbei Anarchismus (im Kropotkinschen Sinne) und Postmodernismus … wobei das Ganze natuerlich viel komplexer ist als zwei Wørter und viele Jahre dauerte, bevor ich da ueberhaupt halbwegs durchblickte und was fuer mich persønlich „draus machen“ konnte. Letztlich gab es dadurch einen (mehr oder weniger) flieszenden Uebergang in eine zweite Phase dieses Weblogs, welche fuer mich ein Art „goldenes Weblogzeitalter“ war in dem ich viel ueber diese ganz wunderbaren Ideen schrieb.
Aber das ist nun auch schon eine Weile vorbei. Nicht dass ich mit obigen Ideen „fertig“ waere — mitnichten! — aber ich bin schon seit Jahren auf keine mir fundamental neuen Ideen gestoszen. Und das fuehrte in eine dritte Phase des Weblogs, die eher eine Art „øffentliches Tagebuch“ als „ich-muss-meine-Gedanken-bzgl.-dieser-fantastischen-Ideen-unbedingt-loswerden-damit-mein-Kopf-vor-Freude-und-Begeisterung-darueber-nicht-explodiert“ ist. Klar freu ich mich immer noch ganz betraechtlich ueber das was ich hier schreibe (und ueber mindestens 100 Mal mehr Sachen ueber dich ich nicht schreibe) und will das der Welt immer noch mitteilen … aber … mhm … ich sag jetzt mal „der Ton“ ist ein anderer … und das ist OK.
Und da ist es schon. Auch wenn hier immer noch regelmaeszig Artikel erscheinen, so geht mir das Material aus worueber ich schreiben will … ich wiederhole mich zwar oft, aber wenn ich das Gefuehl habe, dass ich etwas oft genug gesagt habe, dann kommt auch nix mehr (bzw. viel viel weniger); siehe wieder Anarchismus (im Kropotkinschen Sinne) und Postmodernismus.
Kurzer Sprung zu Ideen an sich. Ein Kuenstler (mich duenkt das war Ruthe oder Flix) meinte mal, dass Kuenstler (mglw. insb. Cartoonisten) immer gefragt werden, wo sie denn ihre Ideen hernehmen und dass das ja ganz erstaunlich ist wie viele verschiedene das sind. Seine Antwort war, dass er da gar nix macht, auszer mit „wachen Augen“ durch die Welt zu laufen.
Und das geht mir genauso. Am offensichtlichsten ist das bei den vielen Artikeln solcher Art. Aber nicht nur bei denen, denn manchmal (in der 2. Phase des Weblogs auch øfter als nur manchmal) wenn ich was lese denke ich: .oO(das lohnt sich darueber ’nen Artikel zu schreiben). Da ich einen Teil lese, kommt da ueber die Zeit so Einiges zusammen.
Aber auch hier bemerke ich seit Jahren, dass ich das weniger oft denke … meistens aus den gleichen Gruenden wie oben.
Deswegen gibt es Fuellartikel … aber bevor ich zu denen komme møchte ich zunaechst sagen, dass ich sehr gerne schreibe … ich nehme an, dass dies das wichtigste „Gegengewicht“ zum obigen Zeitaspekt und der Hauptgrund ist, warum mein Weblog nicht laengst vor langer Zeit das selbe Schicksal erlitten hat wie so viele andere Weblogs.
Vielleicht der wichtigste Grund warum ich so gerne schreibe ist, dass es mir hilft Dinge und mich und andere und die Welt und das Universum besser zu verstehen. Das ist also sowas wie die Gummiente beim Programmieren; nicht genau das Gleiche, aber aehnlich.
An der Stelle møchte ich gerne aus einem anderen (Achtung: eher konservativen) Weblog (den es bestimmt bald nicht mehr gibt) ausfuehrlich zitieren:
When you are grasping at something through your keyboard. When you have read something on the ancient Yamnaya and the North American native nations and the French after WWII and you find a common thread. You have grasped at some subterranean layer of truth. And you try and draw it out for others, but really for yourself. And you create it and share it online and never look at it again but you know it is there and that it is good.
Das manifestiert sich dann auch darin _wie_ ich schreibe. Verøffentlicht werden die Artikel seit bald 10 Jahren regelmaeszig an jedem Primzahltag … auszer dem 23. September, dann das ist nur einen Tag nach meinem Geburtstag und manchmal erschienen Artikel auch an Tagen die durch andere Zahlen als nur Eins und sich selber teilbar sind.
Geschrieben wurden (und werden) die aber oft in „Schreibrunden“ von oft nur wenigen Wochen mit laengeren und langen Pausen dazwischen. Bspw. ist es jetzt gerade erst Anfang August, aber seit Mitte Juli sind bis Mitte November Artikel vorbereitet (und diesen Geburtstagsbeitrag habe ich lange vor mir hergeschoben).
Das scheint nur ein nebensaechlicher Aspekt zu sein, aber ist ein Ausdruck zweier Dinge. Zum Einen dessen was ich oben schrieb: ich mag es zu schreiben und wenn ich erstmal dabei bin, dann „flieszen“ die Gedanken von selber in meine Finger und selbige „fliegen“ ueber die Tastatur. Der andere Aspekt ist das Gegenteil dessen, denn nach einer Pause faellt es mir immer schwer wieder anzufangen mit dem Schreiben.
Oder anders: wenn ich weniger Artikel schreiben und diese unregelmaesziger verøffentlichen wuerde, dann ist das vermutlich das Ende dieses Weblogs.
Und hier kommt ein weiterer Stolperstein, denn seit einiger Zeit habe ich den Eindruck, dass bzgl. meiner persønlichen Entwicklung (siehe oben) nicht mehr so viele aufschreibenswerte grosze Dinge dazukommen. Das sieht man ja auch ganz deutlich daran, wie sich die Art der Themen an denen ich mich ausfuehrlich abarbeite geaendert haben. Die seit langer Zeit laufende (aber auch auf das Ende zugehende) Kevin Bacon Maxiserie ist im Wesentlichen nur ein „Notbehelf“ um einen Grund zum Webblogschreiben zu haben. Auch wenn ich die Untersuchungen sehr interessant finde (und nur durch das Schreiben auf so viele Ideen gekommen bin), so sind dies keine (neuen) Ideen, die mir helfen das Universum und meine Position darin besser zu verstehen.
Klar ich stolpere immer noch ueber interessante Sachen, die ich in mein Weltbild einbaue, aber das sind dann eher Modifikationen als „Durchbrueche im Verstehen der Welt“ … aber ich wiederhole mich, denn darueber liesz ich mich weiter oben bereits aus.
Damit komme ich zu den Fuellartikel zurueck. Die erkennt man meistens daran, dass diese an Tagen erscheinen, von denen es nur 2 Tage bis zum naechsten Primzahldatum sind. Fast immer sind diese kuerzer. Mit Ausnahmen natuerlich, bspw. sind die Krebs-Artikel (aber auch andere) eigentlich keine Fuellartikel, aber wg. Kevin Bacon sind die Plaetze fuer lange Artikel ausgebucht.
Auf die Idee der Fuellartikel um mich am Schreiben zu halten kam ich vor ein paar Jahren und dafuer nahm ich zuerst meine Toilettenbilder her … was letztlich fast 250 Artikel wurden. Als ich keine Toilettenbilder mehr hatte, schrieb ich ueber 300 Weltraumabenteuerartikel; da habe ich zwar noch ein paar offen, aber letztlich ist da auch „die Luft raus“. Es gab auch viele Fuellartikel in anderer Form (bspw. das was z.Z. unregelmaeszig unter der Ueberschrift „Revisited“ erscheint).
Und mehr als ein paar Mal passierte (und passiert) es, dass ich nur kurz was schreiben wollte und „aus Versehen“ entwickelte sich ein langer Artikel daraus, weil beim Schreiben noch mehr Gedanken dazu kamen und Verknuepfungen enstanden und dadurch Zusammenhaengen ersichtlich wurden … siehe das Zitat weiter oben: intellektuelle stimulierung durch das Schreiben an sich. Das ist (wieder: intellektuell) natuerlich sehr befriedigend und somit eine Art positive Rueckkopplungsschleife warum ich so gerne Schreibe.
Das Konzept der kurzen Fuellartikel ist also ganz wichtig, um mich am Schreiben zu halten … nun gehen mir aber nicht nur die neuen (des Aufschreibens wuerdigen) „groszen Gedanken“ aus, sondern auch die „Kleinen“ fuer Fuellartikel.
Andererseits klage ich (intern) da seit Jahren drueber und bisher hab ich doch immer noch was gefunden.
Als letzten Aspekt fragte ich mich ob ich hier nur noch schreibe, weil ich schon so viel Zeit in diesen Weblog gepackt habe. Das waere eine aehnliche Situation wie als die Regierungen der Briten und Franzosen beim Concorde-Projekt dem vielen schlechten Geld noch mehr gutes Geld hinterhergeworfen haben, anstatt das alles abzubrechen. Auch wenn hier Geld keine Rolle spielt, also eine Art des „Versunkene-Kosten-Irrtums„.
Ich habe ehrlich das Gefuehl, dass dem nicht so ist. Hauptsaechlich aus dem oben genannten Grund, dass ich wirklich gerne (hier) schreibe, trotz des immensen Zeitaufwands.
Alles in allem kann das ganz kurz zusammengefasst werden:
1.: mir geht das Material aus und …
2.: … wenn ich nicht regelmaeszig schreibe, schreibe ich gar nicht.
Deswegen die Frage im Titel … vllt. komme ich noch bis zum naechsten Geburtstag, oder vielleicht auch darueber hinaus. Ein paar Ideen hab ich noch und dann wollte ich auch einige der hier vorgestelten Datensachen (bspw. Kino, oder Strøm und so) auf den neuesen Stand bringen.
So lange was da ist, werde ich schreiben … aber vllt. krieg ich irgendwann ’n Rappel ganz pløtzlich und dann wisst ihr meine lieben Leserinnen und Leser jetzt schon, warum vielleicht pløtzlich nix mehr kommt.