Wie bereits beim vorletzten Mal versprochen (und dann aus organisatorischen und didaktischen Gruenden einmal verschoben), gehe ich heute auf die zweite Art der Komprimierung ein.
Anders als bei der vorher behandelten Bedeutungskomprimierung, ist die Wertekomprimierung sehr einfach zu verstehen. Hierbei schaut man naemlich nur auf den Gesamtinhalt einer Spalte (oder Zeile) und setzt den ins Verhaeltniss zum Inhalt der gesamten Matrix. Im weiteren spreche ich nur von Spalten, aber wie vormals gilt das Gleiche auch fuer die Zeilen (mutatis mutandis … und ja, ich such nach Gelegenheiten diesen Ausdruck so oft wie møglich zu verwenden … ich find den so fein).
Der Inhalt der gesamten Matrix ist die Summe ueber alle (Gesamt)Spalteninhalte. Oder anders: das ist die Summe aller Zitate die alle Seiten haben … was natuerlich der Summe aller Links aller Seiten entspricht … was natuerlich der Summe ueber alle (Gesamt)Zeileninhalte ist … was natuerlich bedeutet, dass diese Zahl komplett unabhangig von den Achsenbedeutungen ist und dieser eine Wert sowohl fuer die Spalten- als auch die Zeilenkomprimierung zu benutzen ist.
Der Gesamtinhalt einer Spalte ist die Summe ueber alle Zellen der gegebenen Spalte. Es ist zu beachten, dass diese Werte davon abhaengig sind, welche Bedeutung die Abzsisse und Ordinate haben, obwohl es sich hierbei NICHT um eine Bedeutungkomprimierung handelt. Ich gehe darauf weiter unten etwas genauer ein.
Fuer jede Spalte wird dann der Anteil berechnet, den diese am Inhalt der gesamten Matrix hat und dieser Wert wird dann wie bei der Bedeutungskomprimierung herangezogen um zu ermitteln, wie wieviele Spalten aufaddiert werden muessen, um den festgelegten Komprimierungswert zu erreichen.
Insgesamt hat man also vier verschiedene Komprimierungen fuer die Spalten und Zeilen. Wenn die Abzsisse die Anzahl der Zitate (die eine Seite erhalten hat) repraesentiert, dann ist der Gesamtinhalt einer gegebenen Spalte unabhaengig davon, ob die Ordinate das Selbe repraesentiert, oder die Anzahl der Links einer Seite. Es gibt also nur zwei unterschiedliche Komprimierungen fuer die Spalten, entsprechend den zwei møglichen Bedeutungen; nennen wir diese hier mal kurz A und B. Das Gleiche gilt natuerlich fuer die Zeilen und diese zwei Komprimierungen nenn ich mal kurz 1 und 2. Beides kombiniert ergibt am Ende vier Falschfarbenbilder, mit den Komprimierungskombinationen A1, A2, B1 und B2.
Hier muss ich etwas weiter ausholen, denn auf den ersten Blick scheint das wie bei der Bedeutungskomprimierung zu sein; dort gab es auch vier Falschfarbenbilderkomprimierungskombinationen. Der wichtige Unterschied ist aber, dass die Bedeutungskomprimierung nur fuer eine Achse ausgerechnet werden muss und dann auch fuer die andere Achse gilt (so diese dann die selbe Bedeutung hat). Bei der Wertekomprimierung gilt das nicht und kurz gesagt liegt das daran, dass die Seiten auf der Abzsisse von den Seiten auf der Ordinate zitiert werden.
Oder anders: bei der Bedeutungskomprimierung hat man nur zwei Komprimierungen (A & 1) und die Kombinationen waeren AA, A1, 1A und 11. Es ist zu beachten, dass es bei der Wertekomprimierung KEINE AA-, BB-, 11-, oder 22-Komprimierungskombinationen gibt.
Ein Beispiel macht das hoffenlich anschaulicher. Man denke sich eine Seite die 5 Mal zitiert wird und selber 23 Zitate hat. Wenn die Abzsisse die Anzahl der Zitate repraesentiert wird diese Seite in Spalte 5 gezaehlt und wenn die Bedeutung der Abzsisse die Anzahl der Links ist in Spalte 23. Qualitativ ist das bei beiden Komprimierungsarten im Wesentlichen das Gleiche (auch wenn quantitativ was anderes bei raus kommt). Wichtig ist nun, dass, wie auch immer die Bedeutung der Abzsisse ist, diese Seite in jedem Fall zu der jeweiligen Spalte immer nur 5 „Punkte“ beitraegt, denn (und ich wiederhole mich hier) in den Falschfarbenbildern ist dargestellt, wie oft die Seiten auf der Abzsisse von den Seiten auf der Ordinate zitiert werden.
Nun wende man sich zur Ordinate. Hier findet sich diese Seite in Zeile 5 oder 23 wieder. Soweit erstmal kein Unterschied und das ist der Grund, warum man die Bedeutungskomprimierung nur fuer eine Achse ausrechnen musste. Weil diese Seite aber 23 andere Seiten zitiert, ist der Beitrag dieser Seite zur jeweils gegebenen Zeile 23 „Punkte“. Oder anders: ein und die selbe Seite traegt zu den Spalten anders bei als zu den Zeilen. Deswegen muss man jeweils zwei Anteilverteilungen (der jeweiligen Spalte / Zeilen) pro Achse berechnen.
Und jetzt passiert was kurioses … ist aber logisch, wenn man mal drueber nachdenkt, was ich euch, meinen lieben Leserinnen und Lesern als Hausaufgabe ueberlasse. Wenn die Abzsisse die Anzahl der Zitate repraesentiert so ist der SPALTENanteil identisch mit der Bedeutungskomprimierung, bezogen auf die ZITATE. Das gilt nicht, wenn die Abzsisse die Anzahl der Links repraesentiert.
Der ZEILENanteil wird identisch mit der Bedeutungskomprimierung, bezogen auf die LINKS, wenn die Ordinate die Anzahl der Links repraesentiert. Das passiert aber nicht wenn die Ordinate die Anzahl der Zitate repraesentiert.
Oder anders: wenn ich die Links ueber Zitate darstelle, so sollten die Falschfarbenbilder der Bedeutungs- und Wertekomprimierung identisch sein … da muss ich dran denken, dass beim naechsten Mal zu kontrollieren.
Ich erwaehne das, denn dieser Umstand ist hier und heute von Vorteil. Anstatt vier Anteilsverteilungen (und deren Komprimierungen) muss ich nur zwei zeigen, denn die anderen beiden sind ja schon im Beitrag vom vorletzten Mal zu sehen … man muss dann in Gedanken nur die Beschriftung der Ordinate aendern, aus „Anteil an allen Zitaten / Links (%)“ wird „Spaltenanteil (%)“ bzw. „Zeilenanteil (%)“ (dito … mutatis mutandis … hehe … bei den Anteilen der komprimierten Gruppen).
Nun muss ich gar nicht mehr all zu viel sagen zu den folgenden Diagrammen, denn beim Beitrag zur Bedeutungskomprimierung hatte ich ausfuehrlich besprochen, wie man solche Diagramme liest und deren Informationsinhalt betrachtet.
Hier die Diagramme mit der neuen Information bzw. des Spalten- bzw. Zeilenanteils (bei entsprechender Bedeutung der jeweiligen Achse):
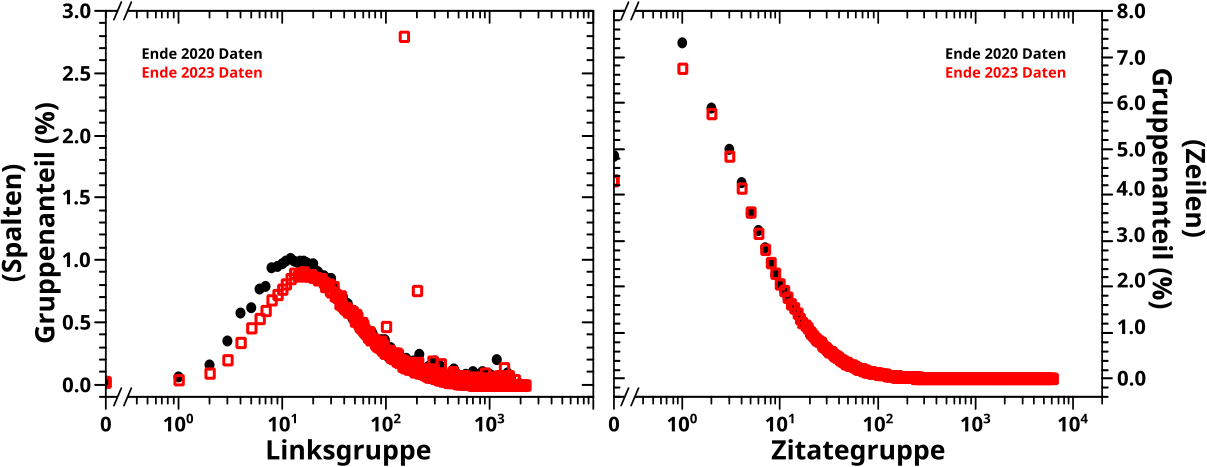
Form und Maximum der Kurve des Spaltenanteils (wenn die Abzsisse die Linksgruppen repraesentiert, linkes Diagramm) sind qualitativ wie bei der Bedeutungskomprimierung (aber quantitativ natuerlich anders). Das Einzige was (sogar im Wortsinne) heraus sticht ist der von der Wikipedia Hauptseite verursachte Punkt in den 2023 Daten. Das ist ja nun nicht mehr unerwartet, aber dieser macht den Unterschied in den beiden Komprimierungsmethoden deutlich, trotz aller qualitativen (und bei entsprechenden Achsenbedeutungen auch quantitativen) Aehnlichkeiten.
Die Kurve fuer den Zeilenanteil (wenn die Ordinate die Zitategruppen repraesentiert, rechtes Diagramm) ist hingegen vøllig anders; wenn man aber mal drueber nachdenkt dennoch logisch.
Hier sieht man auch, warum solche Diagramme wichtig sind, um die komprimierten Falschfarbenbilder vernuenftig zu interpretieren. Ich werde naemlich wieder ein Komprimierungsintervall von einem Prozent waehlen, aber die ersten zehn Zitategruppen liegen da extrem deutlich drueber.
Viel mehr gibt’s hierzu nicht zu sagen und ich kann ohne Umschweife zu den (auf ca. 1 %) komprimierten Gruppen kommen:
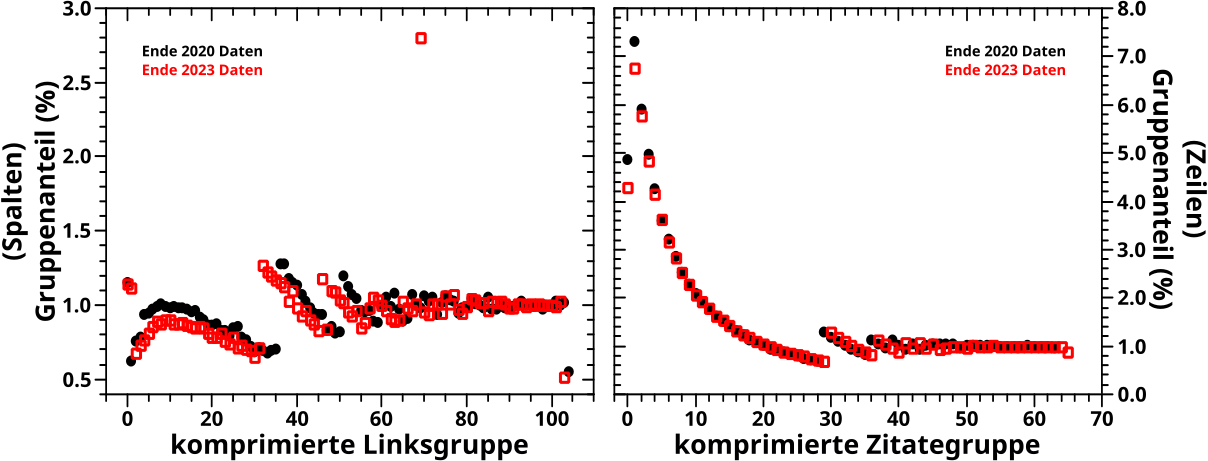
Hier muss ich nun fast gar nix mehr sagen, denn die Spruenge, warum einige Punkte unter, bzw. ueber ein Prozent liegen und wieso die Anzahl der komprimierten Gruppen nicht 100 betraegt, wurde ausfuehrlich beim letzten Mal diskutiert. Was ich im letzten Abschnitt bzgl. den extrem-deutlich-ueber-1-%-Anteilen der ersten zehn Zeilen sagte spiegelt sich natuerlich im rechten Diagramm wieder und ist der Grund, warum es hier gerade mal 66 komprimierte Gruppen gibt.
Alright … wenn’s nix zu sagen gibt, dann will ich das auch nicht unnøtig in die Laenge ziehen. Beim naechsten Mal gibt’s die dazugehørigen Falschfarbenbilder.
Leave a Reply