Als ich mich das erste Mal mit der Verteilung der Laenge der Wikipediaartikeltitel beschaeftigte, simulierte ich sehr viele Namen um etwas genauer zu untersuchen und meinte beim letzten Mal bzgl. der Simulation:
Auch wenn ich das Programm dazu gerade nochmal neu schreibe, werde ich das hier nicht wiederholen, denn diese Simulation war von externen Daten abhaengig und wuerde heute genauso ausfallen.
Und damit lag ich zwar nicht komplett daneben … es war aber auch nicht ganz richtig, denn ich kam sehr wohl auf andere Ergebnisse. Dazu weiter unten mehr.
Zunaechst møchte ich aber nochmal darauf eingehen, wieviele Vornamen man braucht um 50 Prozent aller Babies einen Namen zu geben (wenn diese nach der Beliebtheit ihrer Vornamen sortiert werden). Das war selbst mir zu periphaer vor drei Jahren und ich hatte das deswegen in den damaligen Geburtstagsbeitrag ausgelagert (ich meine das zweite Bild). Dabei hatte ich aber nur Daten betrachtet die „ueber alle Babies gehen“ (also eine Art „Summensignal“).
Jetzt beim Neuschreiben der Programme fuegte ich eine Funktion ein, welche mir auch die zwei Teile dieses „Summensignals“ separat ausspuckt. Oder anders: ich habe jetzt auch nach Maechen und Jungs getrennte Ergebnisse und das sieht so aus:
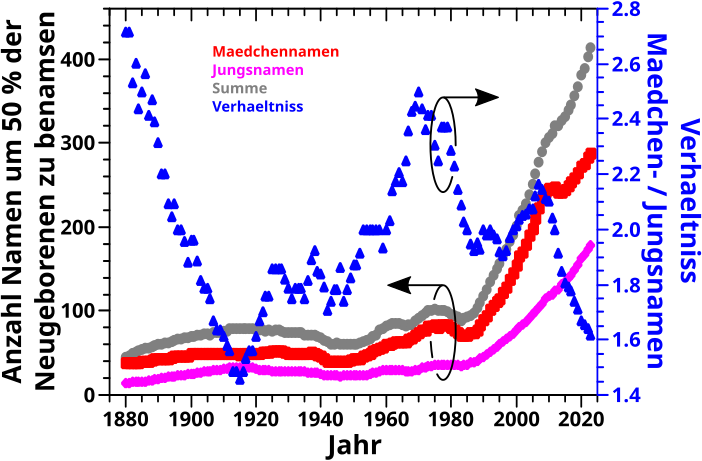
Das „Summensignal“ (graue Punkte) ist das Selbe wie beim vor drei Jahren (auszer, dass drei weitere Jahre dazugekommen sind). Ich fand es aber erstaunlich, dass die Variation bei den Maedchennamen immer ca. 1.5 bis fast 3 Mal grøszer ist (siehe die blauen Punkte). Maedchennamen machen also den Hauptteil am Summensignal aus und deswegen bringe ich das hier doch nochmal, denn das habe ich ja damals ueberhaupt nicht gesehen.
Nun stellt sich natuerlich die Frage warum das so ist, welche ich hier aber nicht beantworten kann (einfach weil ich’s nicht weisz und nicht wuesste wie ich an entsprechende Daten kommen kønnte). Aber zwei potentielle Ursachen fallen mir ein. Zum Einen, kønnten Jungs staerker irgendwelchen Namenstraditionen unterliegen als Maedchen; der Uroppa hiesz schon so und deswegen heiszt der Enkel auch so. Zum Anderen kønnte es aber auch sein, dass es mglw. mehr Maedchennamen als Jungsnamen gibt; der „Maedchennamentopf“ ist also „grøszer“. Das wuerde nicht mal unbedingt mit dem Anstieg ab ca. Mitte der 80er Jahre im Konflikt stehen, denn das Verhaeltniss der Namen bleibt (so ungefaehr) das Gleiche. Besagter Anstieg haengt mglw. mit dem demographische Wandel in den USA zusammen, was zu einem (viel) mehr an Namen fuehrt. Aber dieses „Mehr an Namen“ verteilt sich (mehr oder weniger) gleichmaeszig ueber Jungs- als auch Maedchennamen.
Das war das Ergebnis das sich nicht aenderte. Im gleichen Geburtstagseintrag zeigte ich aber auch die Parameter der Gausskurven fuer jaehrliche Simulationen … und die haben sich geaendert. Hier sieht man das fuer die Position des Zentrums …
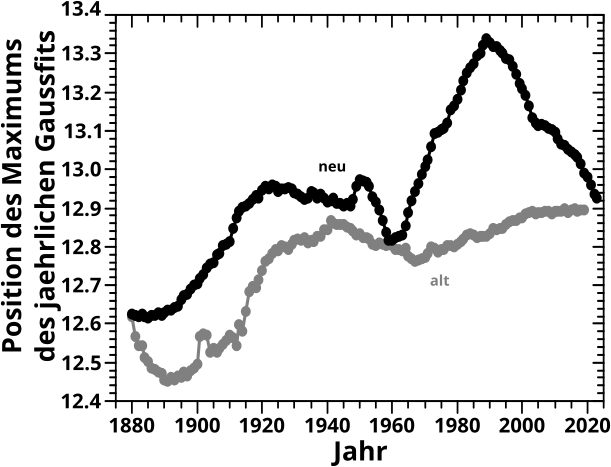
… welches im Mittel jetzt sogar noch besser mit dem beim letzten Mal erwaehnten „Hauptprozess“ uebereinstimmt … und hier fuer die Amplitude und Standardabweichung besagter jaehrlichen Gaussfits:
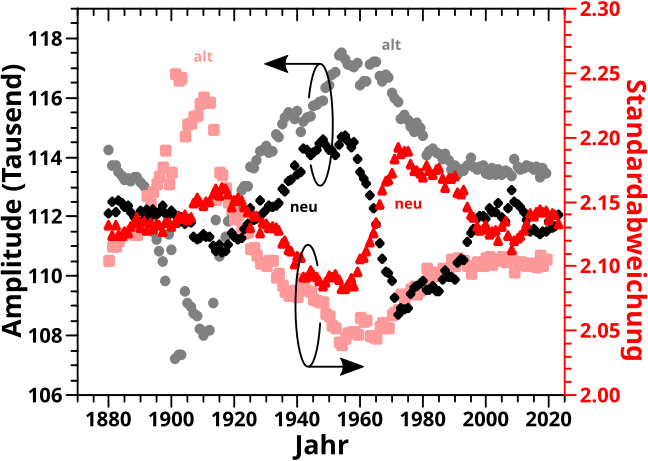
Zum Glueck liegen die Ergebnisse nicht nur in der selben Grøszenordnung, sondern auch innerhalb des selben (sehr engen) Bereichs. Auszerdem sind die allgemeinen Merkmale (wann die Kurven hoch oder runter gehen bzw. so ungefaehr gleich bleiben) im Wesentlichen auch die Gleichen. Ja es gibt Abweichungen (die ja auch der Grund sind, warum ich das hier doch nochmal bringe) aber weil sich das alles ohnehin in sehr engen (Zahlen)Bereichen befindet sind sowieso nur die grøszeren Trends von Interesse und deswegen aendert sich an meinen damaligen Aussagen nix.
Aber es machte mich natuerlich sehr stutzig, dass bei gleichen Ausgangsdaten (zur Erinnerung: fuer diese Simulationen benutzte ich externe Namensdaten und nicht die Wikipedia und an denen hat sich nix geaendert seit 2021) und eigentlich (und auch uneigentlich) gleicher Methode ueberhaupt etwas anderes raus kam.
Es stellte sich heraus, dass der Fehler bei mir lag. Zur Erinnerung: beim zufaelligen „Ziehen“ von Namen aus dem groszen Namenstopf war die Wahrscheinlichkeit einen bestimmten Namen zu ziehen davon abhaengig wie oft der (im jeweiligen Jahr) an Babies vergeben wurde. Fuer 1880 gab es also viele Marys und Johns im Namenstopf, aber nur sehr wenige Wilmas und Zachariahs.
Wie oft ein Name im Topf vorkommt berechnete ich nun so, dass ich die Anzahl der Babies mit einem gewissen Namen durch die Anzahl aller Babies teilte (so weit so gut) und dann mit der Anzahl der Namen die ich insgesamt simulieren wollte multiplizierte (immer noch so weit so gut). Aber weil ich bei meinem selbtgeschriebenen „Namen-aus-dem-Topf-zieh“-Algorithmus nur mit ganzen Zahlen arbeiten konnte, hab ich bei dezimalen Wahrscheinlichkeiten einfach alles nach der ganzen Zahl abgeschnitten. Fuer Namen die im Namenstopf oft genug vorkommen macht das keinen groszen Unterschied. 23517.5 ist nicht viel anders als 23517 … das kann man sogar fuer 10.9 noch argumentieren … mglw. sogar noch fuer 5.5 oder auch fuer 3.9 (selbst hier ist der Fehler ja nicht mal 25 %).
Aber bei all zu kleinen Zahlen kann das Abschneiden der Dezimalstellen im Groszen und Ganzen zu Problemen fuehren, denn es gibt recht viele Namen die bei meinem „selbstgestrickten“ Algorithmus nur ein- oder zweimal im Namenstopf waren und deswegen im Extramfall nur halb so oft gezogen wurden, wie sie haetten gezogen werden sollen.
Beim nochmal Neuschreiben des Programms habe ich das nicht nochmal selbst geschrieben, sondern geschaut was in den vielen umfangreichen Mathebibliotheken von Python zu finden ist und ein entsprechendes Modul benutzt. Besagtes Modul macht alles richtig und deswegen sieht es jetzt anders aus, weil die „Ziehwahrscheinlichkeit“ nun auch fuer sehr selten vorkommende Namen richtig ist.
Zum Glueck ist es aber so, dass sehr selten vorkommende Namen nur sehr selten gezogen werden (selbst wenn mein erster Algorithmus die sogar noch seltener gezogen hat) und deswegen sind die ersten Ergebnisse nicht komplett falsch sondern nur im Detail.
So, das soll jetzt dazu reichen und ich verbleibe wie beim letzten Mal:
[…] wenn ich das richtig sehe, dann gibt’s beim naechsten Mal nicht so viel zu schreiben … aber ich sollte lieber nix versprechen, was ich vermutlich nicht halten kann.
Leave a Reply