Ganz unabhaengig von der Linknetzwerkanalyse betrachte ich damals die Titellaengen etwas genauer. Hier von Interesse ist nur die Verteilung derselben und daran hat sich wenig geaendert:
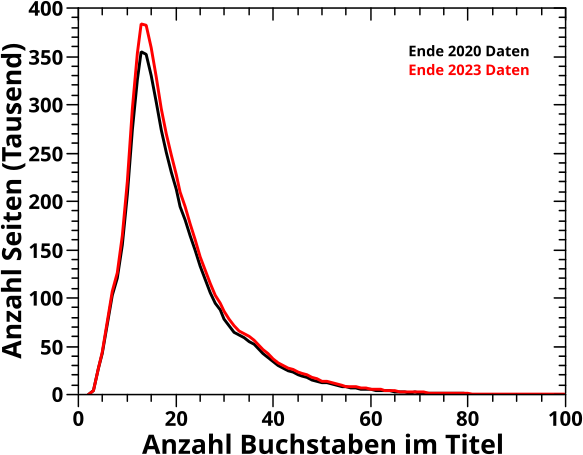
Das Integral unter der Kurve ist jetzt etwas grøszer (entsprechend der Anzahl der dazugekommenen Artikel), aber die Form ist so sehr die Gleiche, dass es fast schon das Selbe ist … mhmm … sprachlich gesehen ist „fast das Selbe“ sowas wie „fast schwanger“ … also Quatsch … aber ihr, meine lieben Leserinnen und Leser wisst sicherlich worauf ich hinaus will … aber ich schwoff ab.
Wenn man annimmt, dass alle neuen Artikel sich im Durchschnitt wie alle bereits vorhandenen Artikel „verhalten“ (und das schlieszt die Artikeltitel ein) war das zu erwarten. Und dies ist eine sehr sinnvolle Annahme und jede andere Annahme muss SEHR gut begruendet sein! Natuerlich sind Abweichungen vom Durchschnitt denkbar. „Nichtdurchschnittlich“ ist es bspw., wenn in den drei dazwischen liegenden Jahren nur Artikel ueber chemische Verbindungen mit langen Namen neu hinzugekommen waeren. So eine Anomalie ist an sich natuerlich interessant, aber die Wahrscheinlichkeit dafuer ist gering und deswegen verteilen sich Laengen der neuen Artikeltitel im Wesentlichen so wie die alten.
Damals konnte ich die Form der Verteilung mittels dreier (gaussverteilter) Prozesse anpassen. Fuer den staerksten dieser drei Prozesse versuchte ich die (Haupt)Ursache zu finden und landete letztlich auf Namen von (mehr oder weniger) beruehmten Leuten.
Dafuer simulierte ich vor drei Jahren zunaechst sehr viele Namen und konnte tatsaechlich (innerhalb vernuenftiger Grenzen) das Zentrum und die Amplitude des ersten erwaehnten Prozesses nachempfinden. Auch wenn ich das Programm dazu gerade nochmal neu schreibe, werde ich das hier nicht wiederholen, denn diese Simulation war von externen Daten abhaengig und wuerde heute genauso ausfallen.
Danach kam ich dann drauf mal zu schauen, ob es bei der Wikipedia vielleicht eine Kategorienseite mit links zu Seiten von Leuten gibt. Die gibt es, aber leider verteilen sich die fast 2 Millionen Seiten zu Leuten auf etlichen tausend Kategorien, weil die vielen Menschen alle fuer unterschiedliche Sachen beruehmt sind.
Einen leider nur halben Ausweg war die Kategorieseite aller lebenden Menschen. Halb deswegen, weil sich dort nur ca. 60 Prozent aller Seiten zu Leuten finden lassen. Das restliche Drittel sind schon verstorbene Menschen und die entsprechende Kategorieseite listet leider nicht die Links zu den Seiten sondern wieder nur die (vielen) Kategorieseiten unter die diese Leute fallen (fielen?).
Aber mit den 2/3 konnte ich zumindest eingeschraenkt arbeiten und die Verteilung der Titellaengen von Seiten zu lebenden Menschen hatte das Zentrum auch an der richtigen Stelle (weil aber so viele fehlten war die Amplitude nur halb so grosz wie die des erwaehnten Hauptprozesses).
Als ich die entsprechenden Programme nochmal schrieb, schaute ich wieder ueber viele Kategorieseiten und stolperte letztlich ueber die Kategorien Births per year und Deaths per year. Da sind die Leute zwar auch nicht direkt aufgelistet, aber die Links zu den Unterkategorien der Leute die in den entsprechenden Jahr geboren / gestorben sind ist systematisch und mit systematischen Sachen kann ich arbeiten.
Und siehe da …
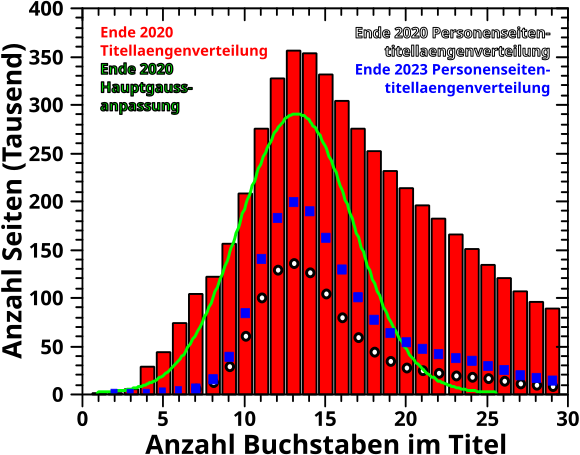
… ich konnte die allermeisten Seiten zu Leuten finden (und nicht nur ca. 60 %). Das sind sicherlich immer noch nicht alle Seiten zu Leuten, denn Autoren muessen die in den entsprechenden Kategorien eintragen, aber ich wuerde schaetzen, dass mir weniger als 5 % fehlen.
Und das Gute ist, dass sich nicht nur das Zentrum nicht verschiebt, sondern die Amplitude der neuen Daten 2/3 der Amplitude des besagten staerksten Prozesses erreicht. Damit ist das Ergebnis nahe genug dran, dass das fuer sich selber spricht und ich das so stehen lassen kann und (anders als damals) nicht rumdiskutieren muss, warum ich denke, dass die Daten (trotz merklich kleinerer Amplitude) vermutlich dennoch richtig sind.
Genug fuer heute … wenn ich das richtig sehe, dann gibt’s beim naechsten Mal nicht so viel zu schreiben … aber ich sollte lieber nix versprechen, was ich vermutlich nicht halten kann.
Leave a Reply