In den vorherigen Beitraegen habe ich untersucht, wie schnell man (im Durchschnitt) von den spezifischen Seiten einer Untergruppe zu irgendeiner (!) anderen Seite kommt … u.U.
Eine Sache die von Interesse ist kann ich leider nicht untersuchen: wie schnell kommt man von den spezifischen Seiten einer Untergruppe zu den spezifischen Seiten einer anderen Untergruppe … u.U. Ich wuerde bspw. vermuten, dass ich am schnellsten von Seiten mit vielen Links zu Seiten mit vielen Zitaten komme.
Die dafuer nøtige Information faellt bei der Netzwerkanalyse an. Die konnte aber leider nicht gespeichert werden, denn das wuerde ca. 100 TB erfordern. Ich hatte schon angefangen und das programmiert, denn ich hatte ein paar Ideen, wie man die Information verlustfrei (!) komprimieren kønnte … ich habe mir also meinen eigenen „Zip“-Algorithmus ueberlegt. Ich war maechtig stolz auf die Ideen die ich hatte, aber leider ist die Entropie in den entsprechenden Daten so grosz, dass ich das Datenvolumen auf maximal 1/3 reduzieren kønnte. Ungefaehr 30 TB sind immer noch zu viel. Dies insb. im Lichte dessen, dass erstens die Ergebnisse vermutlich nicht viel mehr Erkentnissgewinn zur Folge gehabt haetten, als das was ich mittels der neuen Links und der Linkfrequenz herausbekommen habe, ich zweitens nicht gewusst haette, was ich sonst noch mit den Daten machen soll, und dass ich drittens dann die gesamte (mehrmonatige) Netzwerkanalyse nochmal haette durchlaufen lassen muessen.
Anstatt dessen schau ich heute mal, wie ein „Nutzererlebniss“ aussieht, denn das ist ja doch anders als die abstrakten Betrachtungen vorher … naja … abstrakt bleibt es vermutlich, denn ich zeige immer noch Diagramme.
Da ich ein Nutzer der Wikipedia (meist mehrfach pro Tag) und ganz normal[Citation needed] bin, nehme ich meine eigene Erfahrung diesbezueglich als repraesentativ an.
Zunaechst ist dann zu sagen, dass ich praktisch gesehen die meistzitierten Seiten nie aufrufe. Klar, die laenderspezifischen Seiten sind sicherlich interessant fuer Millionen von Schulkindern pro Jahr, aber danach schauen die auch nie wieder drauf. Sicher, Japan schaute ich mir an im Zuge der Vorbereitung auf meine grosze Reise im Jahre 2023; aber Letztere war auszergewøhnlich und ich habe die Seite nie in einem anderen Zusammenhang besucht.
Desweiteren schaue ich mir nie die am wenigsten zitierten Seiten an … auszer im Rahmen dieses Projekts, da habe ich buchstaeblich tausende von denen gesehen. Aber ansonsten wuerde ich nie im Leben drauf kommen mich ueber Bacon in Ohio zu informieren.
Vielmehr schaue ich als Nutzer nach „normalen“ Seiten … hier ’ne Stadt … dort ’ne Person … und ab und zu mal ein Dingens (sehr weitgefasst). Beispielhaft dafuer nehme Kevin Bacon (wen auch sonst), das durch Monty Python beruehmt gewordene Trondheim, das Erzbistum Magdeburg und den guten alten Bleistift.
In diesem Diagramm zeige ich mittels der farbigen Baender nochmals die Bereiche der sechs Untergruppen und wie sich die vier Beispiele dazu verhalten:
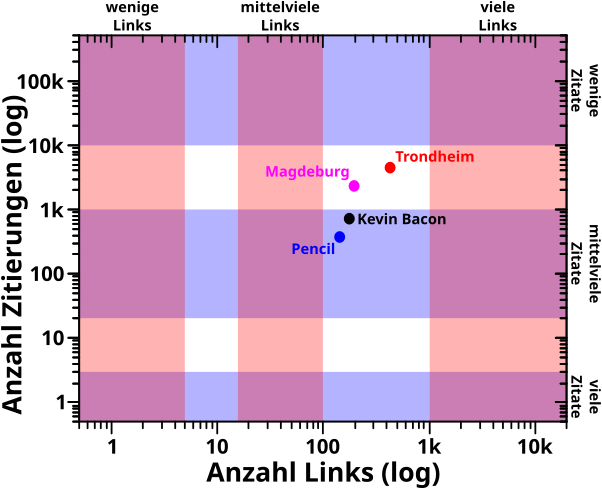
Interessant! Ich haette nicht erwartet, dass Trondheim so beliebt ist.
Wieauchimmer, man sieht, dass die von mir als „normal“ empfundenen Seiten das zumindest teilweise mglw. gar nicht sind. Pencil und Kevin Bacon liegen bzgl. der Anzahl der Zitate von andere Seiten in der „mittelvielen“ Gruppe (die ich unterbewusst als „normal“ betrachte … hier sieht man aber einen der Gruende, warum ich fuer den Namen der Gruppen dieses Adjektiv nicht benutzen wollte). Man kønnte argumentieren, dass sie nahe genug an der gleichen Gruppe bzgl. der Anzahl der Links liegen, denn prinzipiell kønnte man da auch etwas (mehr) Spielraum einraeumen, wenn man die Grenzen fuer die Gruppen festlegt. Diese Argumentation kønnte man auch fuer Magdeburg vornehmen (auch bzgl. der Zitate), aber definitiv nicht fuer Trondheim. Letzteres liegt genau zwischen zwei Gruppen bzgl. beider Charakteristika.
Ganz schøn viele „kønnte“ in obigen Saetzen. Letztlich ist das aber nicht so wichtig. Fuer mich sind das „normale“ Seiten und ich wollte nur mal schauen wo die liegen. Von Interesse sind die kumulativen Anteile:
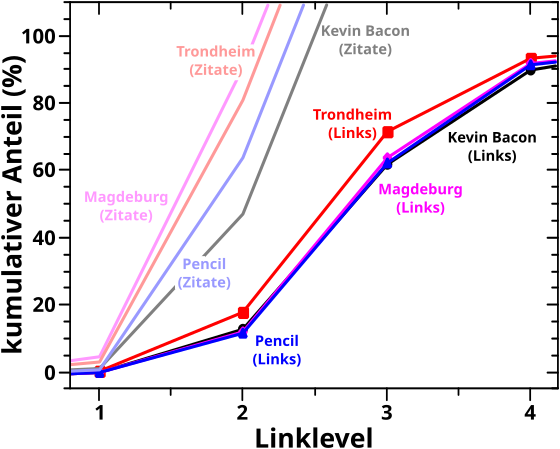
Bemerkung: mit „Zitate“ meine ich natuerlich die Linkfrequenz, aber das ist so viel zu schreiben und ich wollte es nicht abkuerzen … und das Diagramm war schon fertig … und so schlimm ist das nicht, denn Letztere kommt ja wegen Ersteren zustande.
OI! … alle vier Beispiele werden ungefaehr ein Linklevel „schneller“ von anderen Seiten gesehen (kumulativer Anteil Zitate, helle Kurven), als dass sie andere Seiten erreichen (kumulativer Anteil neue Links, nicht-helle Kurven) … *kurzer Blick auf das erste Diagramm* … das sollte mich eigtl. nicht verwundern, denn alle Beispiele haben (signifikant) mehr als Links als Zitate.
Wenn wir mal zur Analyse der Untergruppen zurueck schauen, so liegt der „50-Prozent-Uebergang“ der Beispiele bzgl. der Links an ca. der Stelle der Untergruppen mit den vielen Links / Zitaten. Das ist interessant, denn einige der obigen „das kønnte man auch dort und dort einordnen“ tendierten eher zur Untergruppe mit den „mittelvielen“ Links. Andererseits sprechen wir hier von vier Beispielen im Vergleich zu einer Gruppe mit ueber 2 Millionen Seiten.
Bzgl. des kumulativen Anteils der Linkfrequenz liegen die Beispiele zwischen den Untergruppen mit vielen bzw. mittelvielen Zitaten; Kevin Bacon und Pencil liegen naeher an Letzterer waehrend Trondheim und Magdeburg naeher an Ersterer liegen … was dem Erwartungsbild (nach dem ersten Diagramm) entspricht.
Alles in allem erwartete ich bei den vier Beispielen nix fundamental Unerwartetes und das ist dann auch eingetreten.
SO … nun aber … jetzt bin ich wirklich durch und beim naechsten Mal fang ich tatsaechlich (und endlich?) an „zusammen zu packen“.
Leave a Reply