Zur Wiederholung: beim letzten Mal formulierte ich die Frage …
[…] wieviele „Schritte“ braucht man im Durchschnitt von irgendeiner Seite zu irgendeiner anderen Seite?
… und nahm die (kumulative) Anzahl der neuen Links zur Hilfe um diese zu beantworten. Aber das war nur eine Haelfte der Antwort, denn die neuen Links zeigen nur,
[…] wieviele Schritte […] eine [Urpsrungs]Seite im Durchschnitt machen [muss] um irgendeine andere Seite zu sehen […].
Die andere „Haelfte“ der Antwort muss schauen,
[…] wieviele Schritte […] ANDERE Seiten machen [muessen] um die eine Seite zu sehe.
Da sollte im Durchschnitt das Gleiche bei rauskommen, aber im konkreten Fall muss dem nicht so sein. Ich gab beim letzten Mal ein Beispiel und erwaehnte bereits, dass ich fuer die zweite Haelfte der Antwort die Linkfrequenz nutzen werde,
denn diese misst auf welchem Linklevel eine gegebene Seite von anderen Seiten gesehen wird […].
Leider wird bei der Linkfrequenz ein groszer Teil der urspruenglichen Information „verlustbehaftet komprimiert„, denn diese misst nur, OB eine Seite von einer anderen Seite (auf einem gegebenen Linklevel) gesehen wird. Weder beinhaltet die Linkfrequenz Information darueber wie oft die andere Seite die eine Seite (auf einem gegebenen Linklevel) sieht, noch ob die andere Seite die eine Seite bereits auf einem vorherigen Linklevel gesehen hat. Ersteres ist im hiesigen Zusammenhang nicht schlimm, denn das interessiert mich nicht. Letzteres ist fuer obige Frage allerdings von allergrøsztem Interesse.
Oder anders: in der Linkfrequenz einer Seite kommt es zu Mehrfachzaehlungen durch „Mehrfachsichtungen“. Bspw. kann die andere Seite die eine Seite sowohl auf LL5 als auch auf LL23 sehen. Die zweite Sichtung duerfte ich in Anbetracht dessen das was ich hier beantworten will NICHT mehr mitzaehlen. Aber eben genau diese Information, dass (im Beispiel) mindestens ein „Punkt“ des Wertes auf LL23 eine „wiederholte Sichtung“ ist, fehlt.
Mehrfachsichtungen sollten i.A. keine all zu grosze Rolle spielen auf sehr kleinen Linkleveln. Das liegt daran, weil bei kleinen Linkleveln, die zitierten Seiten thematisch nahe an der Ursprungsseite liegen. Da kommt es dann zwar bestimmt zu Mehrfachsichtungen „thematisch naher“ Seiten, das sind aber im Groszen und Ganzen nur ein paar Seiten und alle anderen Seite der Wikipedia tauchen noch gar nicht auf.
Andererseits verzweigt sich das Linknetzwerk extrem schnell und schon nach ein paar wenigen Linkleveln sieht man nicht mehr nur Seiten zu einem Thema, sondern zu sehr sehr sehr vielen Themen (und die Linkfrequenzen der entsprechenden Seiten gehen um eins hoch). Viele von diesen Seiten sieht man dann auf den darauffolgenden Linkeveln nochmal (auch wenn man dem Link nicht nochmal folgt) und deren Linkfrequenz geht (fuer das entsprechende Linklevel) wieder um eins hoch. Letzteres liegt einfach an der schieren Menge an gleichzeitig erreichten Seiten, welche schonmal gesehene Seiten (wieder) zitieren.
Eine wichtige Schlussfolgerung aus dem eben Gesagten ist, dass der (durchschnittliche) kumulative Anteil der Linkfrequenz nach genuegend Linkleveln die 100 % (deutlich) uebersteigen (sollte). Das wiederum hat eine weitreichende Konsequenz, denn anders als bei den neuen Links kann ich nun nicht mehr das Integral unter der (Summen)Kurve benutzen um den durchschnittlichen (nicht kumulativen) Anteil pro Linklevel auszurechnen.
Das bereitete mir zunaechst Kopfzerbrechen, aber letztlich kam ich dann auf die folgende, hoffentlich plausible Methode um eben diesen durchschnittlichen Anteil (pro Linklevel) auszurechnen (und daraus dann den kumulativen Anteil).
In kurz: das Summensignal der Linkfrequenz muss auf jedem Linklevel zwei Mal (!) durch die Anzahl aller Seiten geteilt werden.
Fuer die etwas laengere Erklaerung denke man sich zunaechst die Linkfrequenz EINER Seite auf einem sehr niedrigen Linklevel (bspw. LL1). Diese Seite kann prinzipiell von allen (fast) 6 Millionen anderen Seiten gesehen werden. Um den durchschnittlichen Anteil der Seiten zu bekommen die diese Seite auf dem Linklevel sehen, muss ich die erste Division durch (fast) 6 Millionen ausfuehren.
Das Summensignal ist nun aber die Summe (Doh!) der Linkfrequenzen ALLER ((fast) 6 Millionen) Seiten. Daher die zweite Division.
Aber Achtung (kurzer Einschub): wenn man nur bestimmte Untergruppen (z.B. vielzitierte Seiten) betrachtet, dann ist der Nenner bei der zweiten Division natuerlich NICHT (fast) 6 Millionen sondern NUR durch die Anzahl der Seiten in der Untergruppe. Die Situation bzgl. der erste Division aendert sich bei Untergruppen nicht. Ich greife damit aber vor und das wird erst im naechsten (oder vllt. uebernaechsten) Artikel wichtig; ich wollte das nur hier schon erwaehnen, damit es erledigt ist.
Diese ganze Huette ist der Grund, warum ich das Thema mit den neuen Links angefangen habe; bei denen ist das alles viel einfacher zu verstehen und ich musste nicht lang und breit erklaeren, wie ich die Information von Interesse aus den Daten gepolkt habe. Die Linkfrequenz ist aber nicht aus Unueberlegtheit mit „Informationsverlust“ konzipiert worden. Vielmehr stand ich vor dem Dilemma, dass das Datenvolumen der Resultate der Linknetzwerkanalyse ohne diese „verlustbehaftete Komprimierung“ der Information mindestens etliche hundert Terabyte (mich duenkt gar im niedrigen Petabyte Bereich) betragen haette.
Aber nun ist alles zum Verstaendniss wichtige gesagt und ich kann das gleiche Diagramm wie beim letzten Mal zeigen; die Summe aller Linkfrequenzen fuer kleine Linklevel und der durchschnittliche kumulative Anteil der Seiten die eine andere Seite bis zum gegebenen Linklevel gesehen haben:
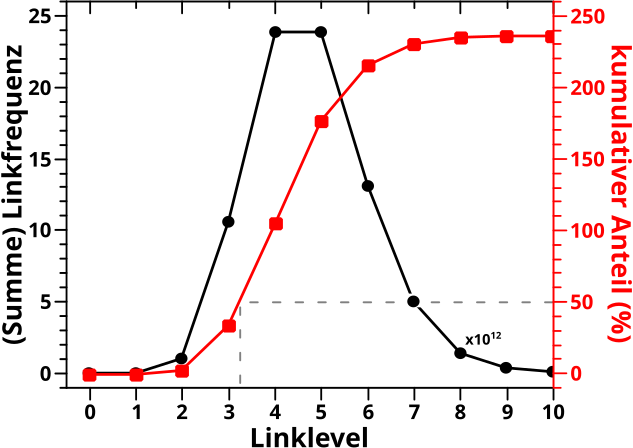
Wie beim letzten Mal gilt, dass die schwarze Kurve mit einer Billion multipliziert werden muss. Aber auch heute ist die nicht wirklich von Interesse, denn die wurde bereits hier besprochen (das ist uebrigens kein Plateau, das sieht nur so aus, weil da so wenig passiert).
Wieauchimmer, die rote Kurve zeigt die Groesze die hier von Interesse ist und die Form ist die selbe „S“-Kurve wie beim letzten Mal. Ebenso wie beim letzten Mal (und wie erwartet) wird der 50 % Anteil zwischen dem 3. und 4. Linklevel ueberschritten. Und letztlich, wie erwaehnt, fuehren die Mehrfachzaehlungen dazu, dass der endgueltige kumulative Anteil 100 % uebersteigt; genauer gesagt wird im Durchschnitt jede Seite (fast) zweieinhalb Mal von jeder anderen Seite gesehen.
Jetzt ist noch von Interesse, inwieweit die Ergebnisse vom letzten Mal mit den Ergebnissen von heute uebereinstimmen. Wie gesagt, das sollte im Durchschnitt (!) das Gleiche sein (bis der Einfluss von Mehrfachzaehlungen zu grosz wird und einen Vergleich nicht mehr zulassen). Deswegen habe ich das hier mal zusammen aufgetragen:
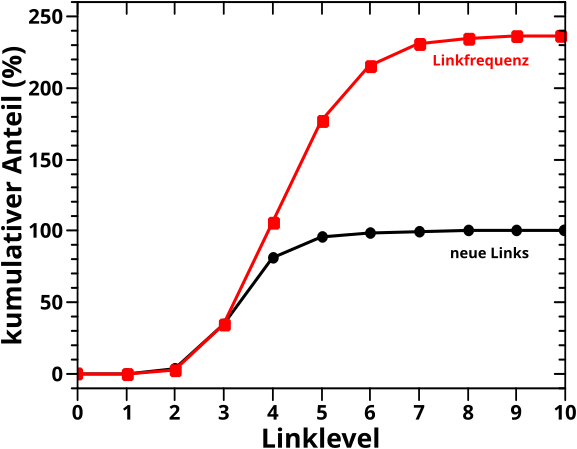
Ich muss sagen, dass mir ein Stein vom Herzen gefallen ist, als ich sah, dass beide Kurven bis LL3 (beinahe) deckungsgleich sind. Ich haette naemlich nicht gewusst, wie eine signifikante Diskrepanz zu erklaeren ist.
So … damit ist die implizite Frage des ersten Beitrags beantwortet. Ich bin aber noch nicht fertig, denn zwischen dem allerersten und diesem Beitrag habe ich viel gelernt ueber die Wikipedia. Eine der wichtigsten Erkenntnisse war, dass nicht alle Seiten gleich sind und die Dynamik von ein paar wenigen Seiten absolut dominiert wird (siehe bspw. hier, das zieht sich aber durch etliche Beitraege).
Oder anders: es gibt „wichtige“ und „unwichtige“ Seiten … und mglw. auch „mittelwichtige“ … womit sich die Frage stellt, ob das Ergebniss fuer alle Seiten gleich aus sieht? Mein Bauchgefuehl sagt erstmal nein … aber dann will mein Bauch auch gerne wissen ob er richtig liegt und wie die Unterschiede aussehen.
Lange Rede kurzer Sinn: im Durchschnitt ist alles fertig und die Frage beantwortet, ich werde aber das Verhalten von Untergruppen noch naeher untersuchen. Dazu werde ich beim naechsten Mal zunaechst drei Untergruppen definieren (Spoiler: das hat rein GAR NIX mit „wichtig“ oder „unwichtig“ zu tun) um mir deren Verhalten beim uebernaechsten Mal genauer anzuschauen.
Aufgrund der bereits geleisteten Vorarbeit wird das dann auch alles mit weniger Geschreibe zu erledigen sein (hoffe ich).
Leave a Reply