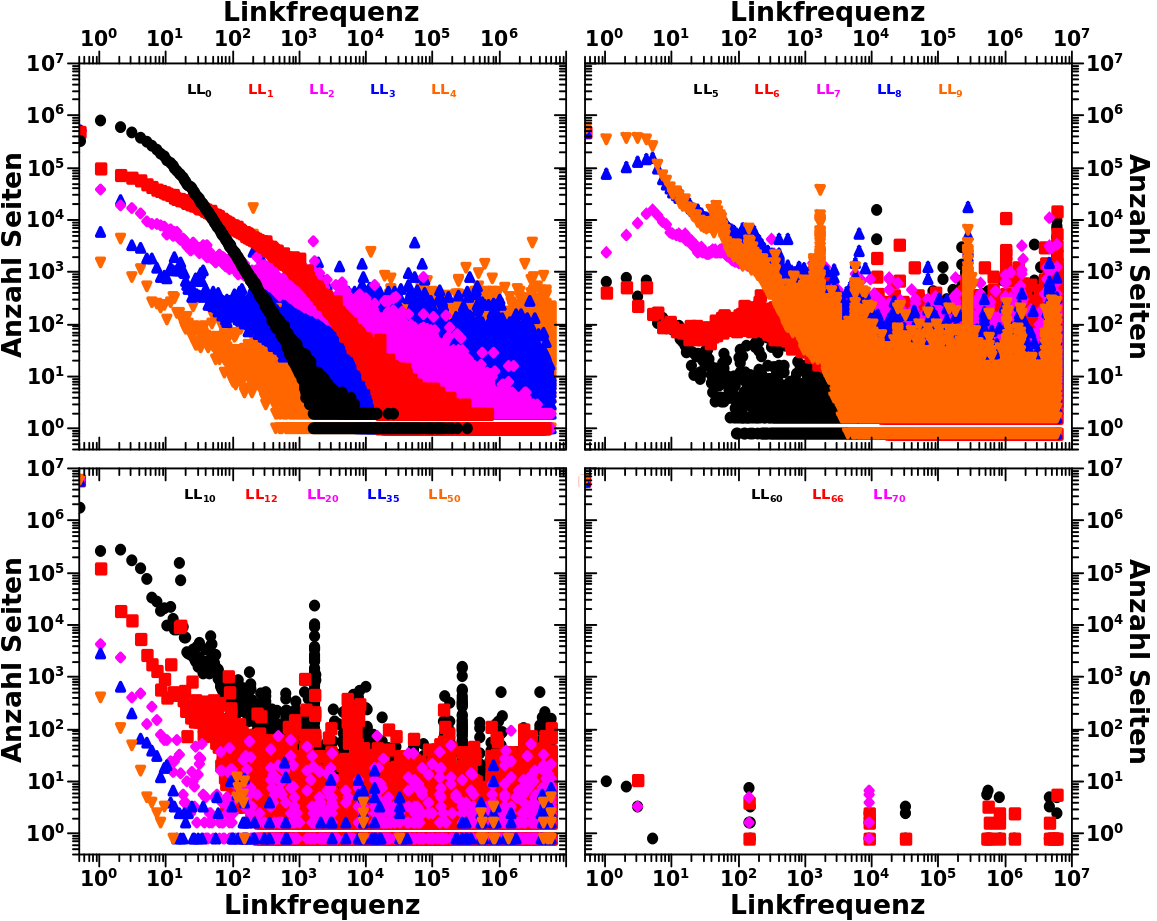
Beim letzten Mal erklaerte ich detailliert anhand der totalen Links und den Selbstreferenzen was ich mit den „Seiten pro Grøzenordnung“ meine. Deswegen kann ich heute ohne viel Aufhebens sofort zur Linkfrequenz uebergehen. Zunaechst wieder zwei repraesentative Verteilungen zur Erinnerung:
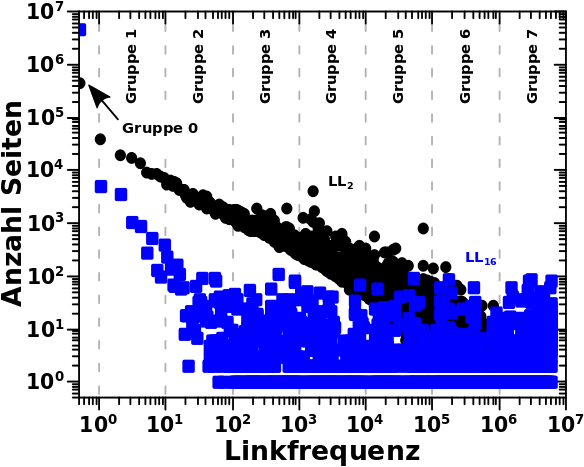
Am Beispiel der Daten von LL16 kann man noch einen anderen Grund sehen, warum ich ueberhaupt auf die Idee gekommen bin die Seiten pro Grøszenordnung zu untersuchen (abgesehen davon, dass ich die „kollektive Bewegung“ untersuchen wollte). Aufgrund der Ueberlappung der Datenpunkte und weil diese (scheinbar?) gleichverteilt sind (die „Amplitude bleibt im Mittel gleich ab einer Linkfrequenz von ca. 100), sieht es so aus, als ob in jedem Intervall ungefaehr gleich viele Seiten liegen. Dem sollte aber nicht so sein, allein schon wg. der (visuellen) „logarithmischen Komprimierung“.
Bei den totalen Links kommt so ein Eindruck nicht auf, weil sich die Seiten nicht gleich verteilen. Bei den Selbstreferenzen ebenso nicht aufgrund des linearen Zusammenhangs (die Amplitude veraendert sich ueber ein Intervall).
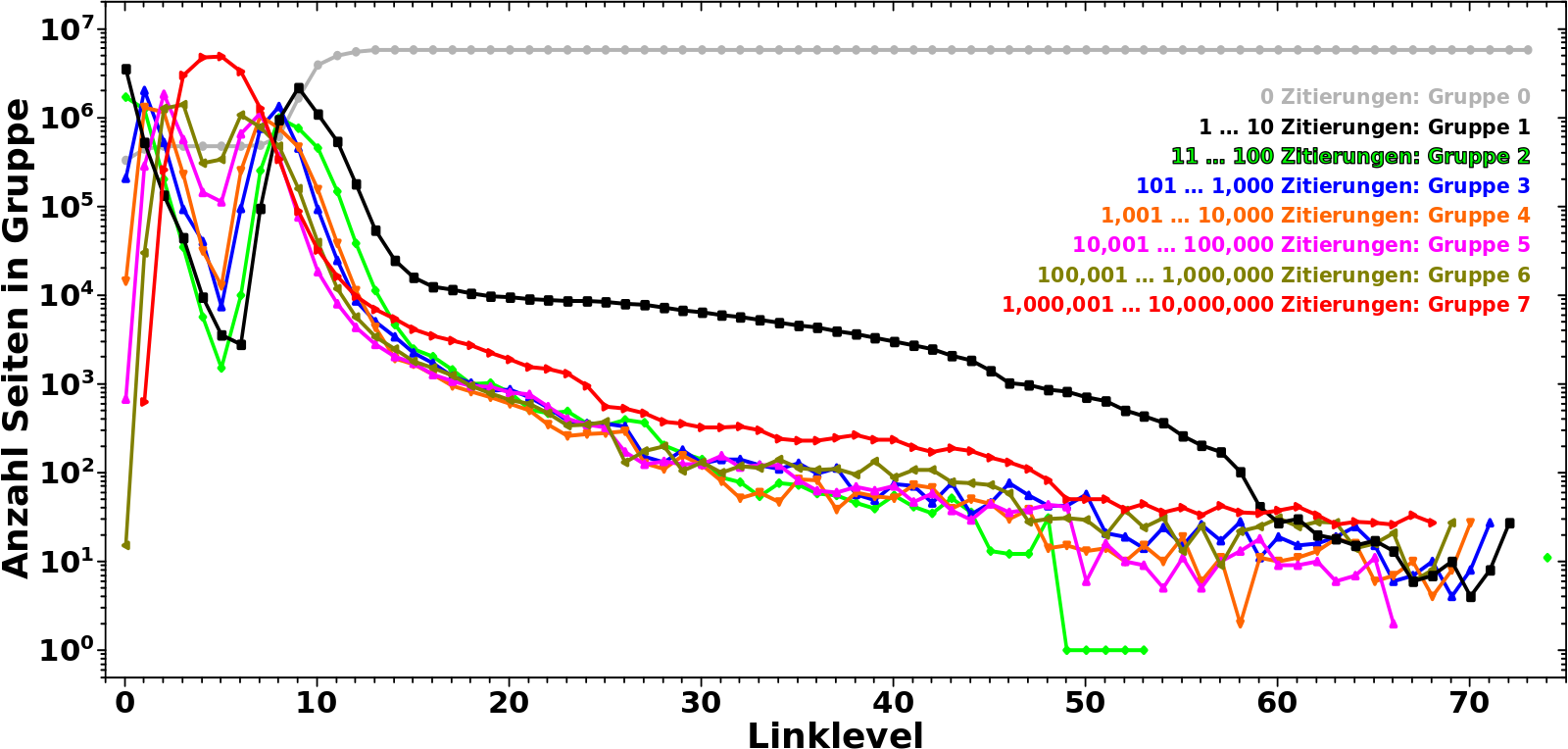
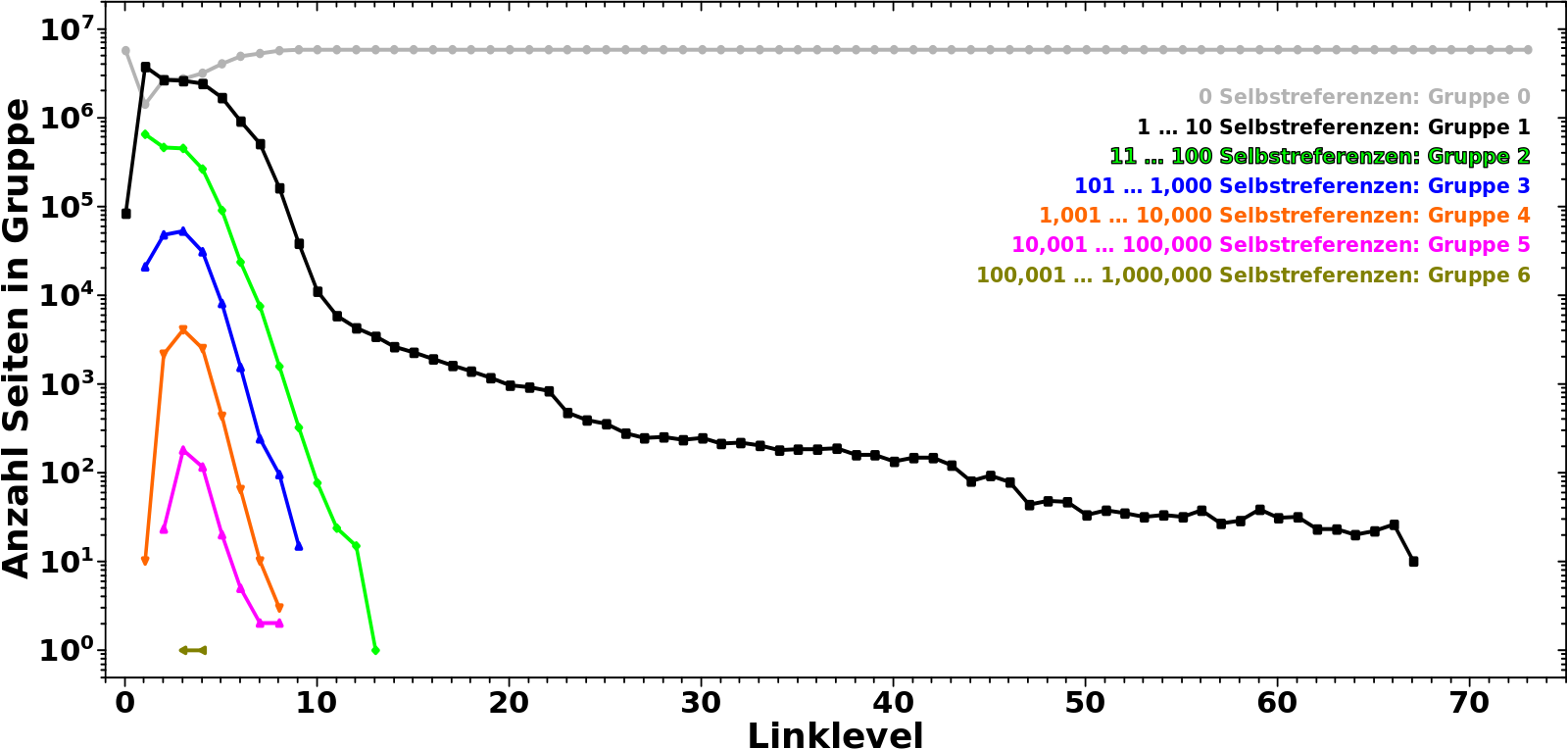
Darum nun endlich die Verteilung der Seiten ueber die Grøszenordnung(en) in Abhaengigkeit vom Linklevel:
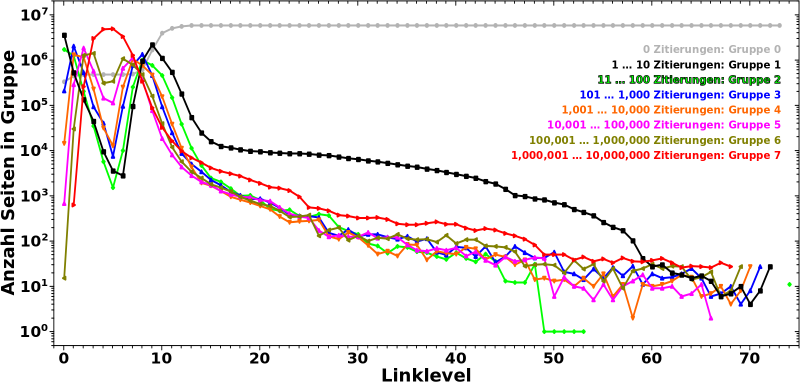
Uff, hier passiert am Anfang viel. Deswegen gehe ich da Schritt fuer Schritt durch.
Zunaechst lasse ich Gruppe 0 auszen vor. Die ist erstmal nicht relevant.
Auf LL0 befinden sich die meisten Seiten in Gruppe 1, werden also nur 1 bis 10 mal von anderen Seiten auf diesem Linklevel zitiert. Nur noch halb so viele Seiten werden 11 bis 100 mal zitiert (Gruppe 2) und gar 20 mal weniger Seiten befinden sich in Gruppe 3. Noch sehr viel (viel viel) weniger Seiten sind in den Gruppen 4 bis 6. Keine einzige Seite wir mehr als 1 Million mal zitiert.
Auf LL1 gibt es dann aber schon massiv viel mehr (totale) Links (zu LL2) und deswegen bewegen sich 80 % der Seiten aus Gruppe 1 raus und in høhere Gruppen hinein (werden also von (deutlich) mehr als 10 anderen Seiten zitiert, auch wenn der Wert von Gruppe 2 ebenso etwas abnimmt). Entsprechend steigt der Wert fuer alle høheren Gruppen an und wir sehen auch zum ersten mal Seiten die sich in Gruppe 7 befinden.
Auf den naechsten paar Linkleveln nimmt der Wert fuer høhere Gruppen weiter zu. Aber je „tiefer“ eine Gruppe liegt, um so eher ereilt sie das gleiche Schicksal wie Gruppe 1 und 2; die Seiten bewegen sich von dort zu høheren Gruppen. Fuer Gruppen 3 und 4 geschieht das auf LL2, fuer Gruppen 5 und 6 auf LL3 bzw. LL4.
Letztlich landen die allermeisten Seiten in Gruppe 7 deren (zugegeben relativ breites) Maximum ungefaehr mit den Minima der anderen Gruppen zusammen faellt.
Nach dem Durchschreiten des Maximums von Gruppe 7 aendert sich das Vorzeichen der „Bewegung“ und die Werte aller Gruppen (auszer von Gruppe 7) steigen ab LL7 wieder an. Hier aber geschieht das Gegenteil zum Anfang. Je „høher“ eine Gruppe ist, um so kuerzer ist die „Erholungsperiode“, denn die Seiten „migrieren“ schnell weiter zu „tieferen“ Gruppen. Entsprechend fallen die Werte aller Gruppen nach durchlaufen eines (weiteren) Maximums rasch wieder ab.
Ab LL9 fangen die meisten Seiten an in Gruppe 0 ueber zu gehen und ab LL11 sind die allermeisten Seiten dort angelangt, werden also nicht mehr zitiert.
Ich wuerde noch nicht sagen, dass dort dann schon die zitierenden Ursprungsseiten ins „São Paulo FC“-Artefakt „eingetreten“ sind. Dafuer ist die Dynamik in den Kurven der Gruppen noch zu grosz. Aber das laeszt nicht lange auf sich warten und auch wenn ich den genauen „Eingang ins Artefakt“ bisher nicht entdeckt habe, so ist mir das in so vielen „Messungen“ begegnet, dass ich sagen wuerde, dass der um LL20 liegt. Der ganze lange Schwanz kann ab dort eigentlich auszer acht gelassen werden.
Als ich mir die Kurven genauer anschaute wurde ich stutzig. Das sieht doch so aus, als ob das (zweite) Maximum von Gruppe 1 genau am Wendepunkt der Kurve von Gruppe 7 ist. Faszinierend! Also habe ich die Gruppe 7 Kurve zwei Mal (numerisch) abgeleitet und siehe da …
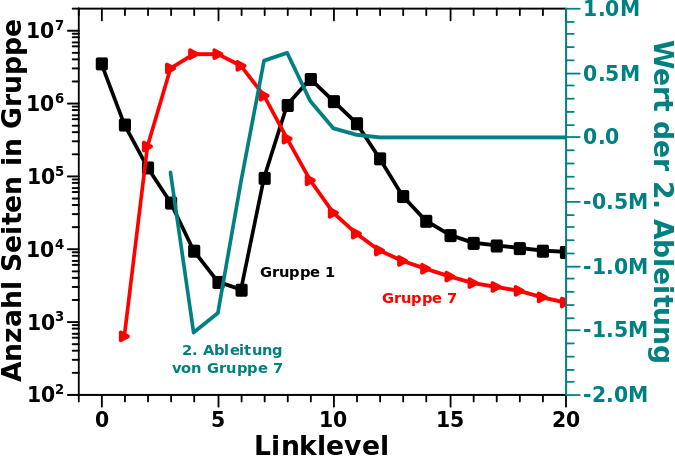
… qualitiativ (also von der Form) aehnelt die Kurve von Gruppe 1 tatsaechlich der 2. Ableitung der Kurve von Gruppe 7.
Ich zerbrach mir einen Abend und den darauffolgenden Morgen den Kopf wie das sein kønnte. Ich ueberlegte hin und her wie die kollektive Bewegung der Seiten aussieht und verlor manches Mal den Ueberblick wo sich denn eine Seite nun befindet von einem Linklevel zum naechsten bzw. was eine Bewegung bedeutet. Am Ende kam ich auf den folgenden Mechanismus der obige Beobachtung erklaeren wuerde.
Die erste Ableitung ist der Anstieg einer Kurve. In diesem Zusammenhang also wie viel grøszer (oder kleiner) der Wert der Kurve von Gruppe 7 auf dem im naechsten Linklevel ist. Der Wert auf dem naechsten Linklevel wird aber dadurch bestimmt, wieviele Seiten von „niedrigeren“ Gruppen sich zu Gruppe 7 bewegen. Das wuerde zur Folge haben, dass die Kurven von niedrigeren Gruppen eigtl. der 1. Ableitung aehneln sollten. Und wenn man da mal schaut, dann findet sich durchaus eine Aehnlichkeit (auch wenn ich das hier nicht zeige, weil’s reicht das zu sagen). Fetzt ja.
Aber warum aehnelt die Kurve von Gruppe 1 dann der 2. Ableitung? Nun ja, (fast) alle Seiten befinden sich zunaechst in Gruppe 1. Von dort migrieren sie aber nur in den seltensten Faellen direkt zu Gruppe 7 (wenn ueberhaupt, ich habe das nicht kontrolliert). Viel mehr ist es so, dass sich die Seiten von Gruppe 1 zunaechst in die Gruppen 2 bis 6 bewegen. Damit „treiben“ die Seiten die Aenderung der Werte in diesen „Zwischengruppen“. Aha! Gruppe 0 ist demnach der Anstieg von denen. Und wenn die Zwischengruppen den Anstieg von Gruppe 7 bestimmen, so ist Gruppe 0 der Anstieg vom Anstieg und das ist genau das was die 2. Ableitung ist. Cool wa!
Da hab ich mich urst gefreut, dass ich darauf gekommen bin … … … und dann machten sich bereits am fruehen Nachmittag Zweifel breit, denn das ist alles viel zu gut um wahr zu sein.
Deswegen suchte ich nach Fehlern und fand die nicht in der Argumentation sondern in der Ausgangslage. Denn wenn man mal genauer hinschaut, dann aehnelt die Kurve von Gruppe 1 deutlich weniger der 2. Ableitung der Kurve von Gruppe 7, als es im obigen Diagramm den Anschein hat. Da ist mein Gehirn auf seine eigene, von der Evolution so eingerichteten, Mustererkennung hereingefallen.
Klar, das sieht auf den ersten Blick so aus, aber die Minima und Maxima der beiden Kurven sind selbst bei groszzuegiger Interpretierung um mindestens ein Linkelvel verschoben. Das fuer sich allein ist erstmal nicht so schlimm. Ich bin sicher, dass man dafuer eine Erklaerung finden kann und ich hatte schon angefangen nach einer zu suchen.
Dann kommt aber hinzu, dass die Funktionswerte auch nicht hinhauen. Klar, oben sind die linke und die rechte Ordinate schøn skaliert (hab ich mit Absicht gemacht). Aber die 2. Ableitung hat viel kleinere und auszerdem auch negative (!) Werte.
Es bleibt also nur noch die Form der Kurven ueber. Und wenn ich da ehrlich bin, sollte man nicht das Eine logarithmisch und das Andere linear darstellen sondern beide linear und das sieht dann so aus:
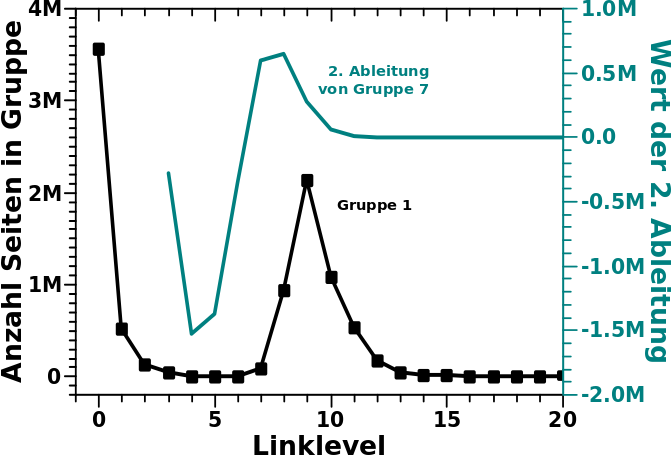
Tjaaaa … da war die grosze Aehnlichkeit dann (fast) ganz fort. Naja, intellektuell war’s dennoch ein interessantes Puzzle, auch wenn’s nicht stimmt.
Andererseits wiederum denke ich, dass obiger Mechanismus plausibel ist. Mein Bauchgefuehl sagt mir, dass das zumindest eine Rolle bei der „kollektiven Bewegung“ spielt. Aber in der mathematisch „geschlossenen“ Form wie besagter Mechanismus vorgaukelt sicherlich nicht.
Ich finde es wichtig auch die Fehler und wie man zu denen kommt und diese erkennt zu zeigen. „Falsch“ eingeschlagene Wege und daraus gelernte Lektionen sind (sehr) oft ein Weg zu neuen Erkenntnissen. Fehler sind also ein wichtiger Teil der wissenschaftlichen Methode, aber meistens unsichtbar, weil man ja nur die Erfolge aufschreibt.
Ach ja, es war natuerlich natuerlich ein „brain fart„, dass ich aus der (scheinbaren) Position des (zweiten) Maximums von Gruppe Null ueber dem Wendepunkt von Gruppe 7 schloss, dass Erstere die 2. Ableitung der Letzteren ist. Im Wendepunkt wird die 2. Ableitung naemlich null.
Und damit soll’s genug sein fuer heute.