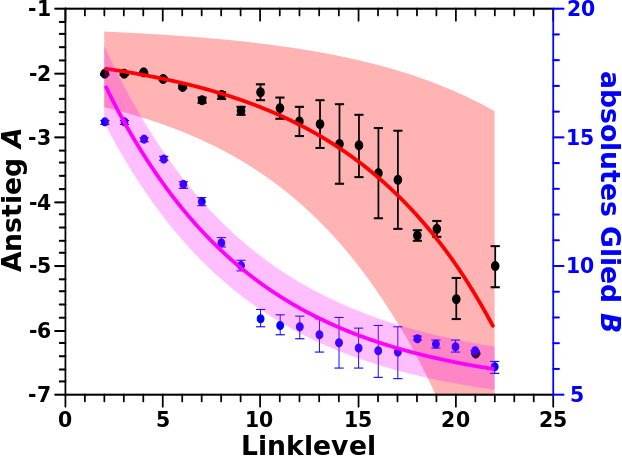
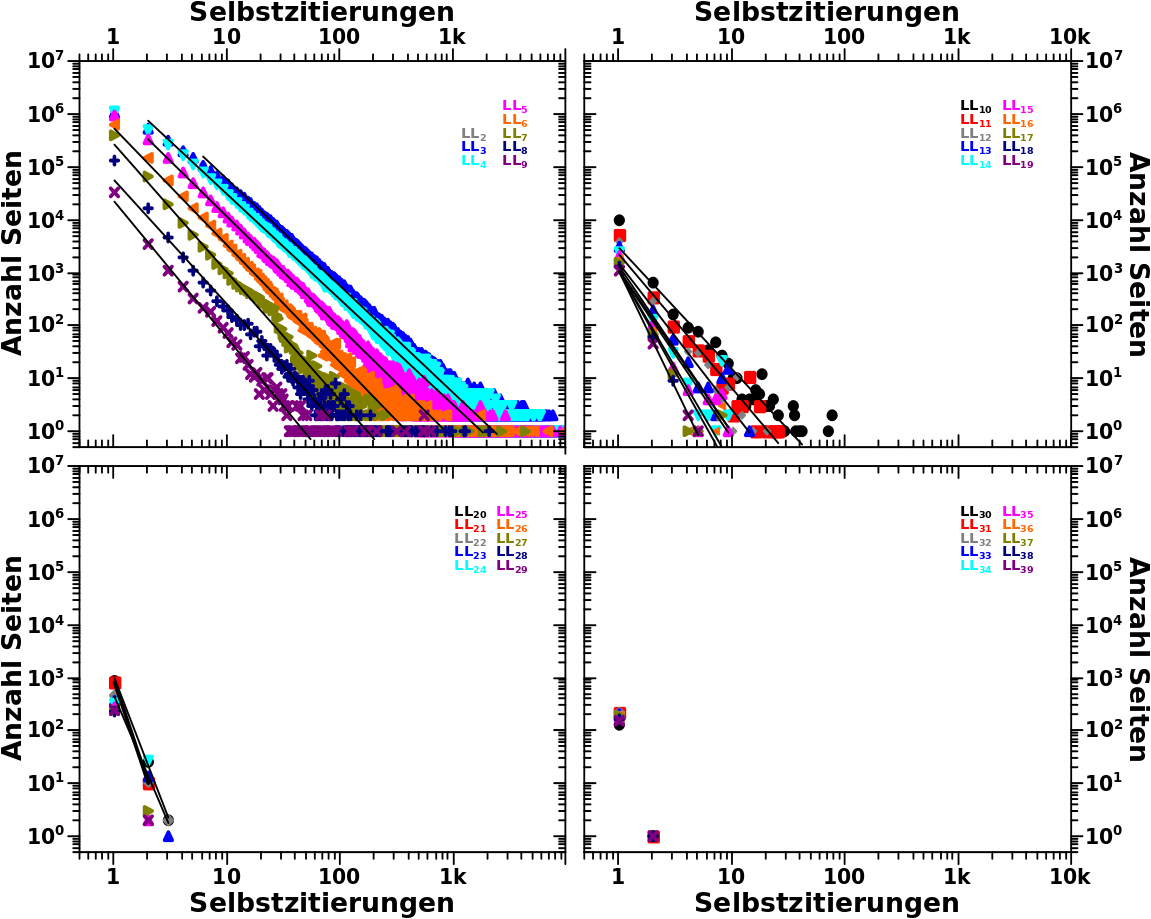
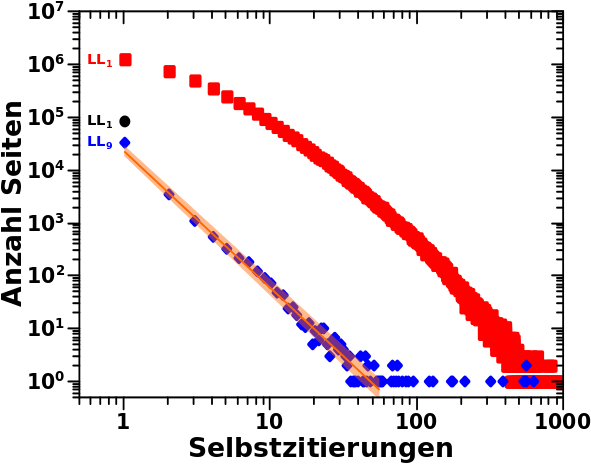
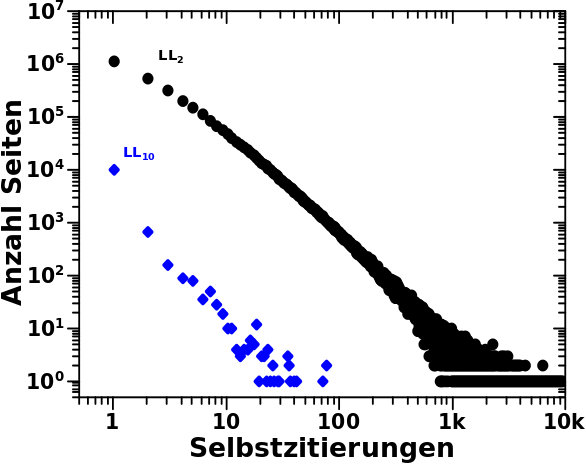
Schwupps … so schnell macht sich _noch_ eine neue Miniserie auf.
Der Grund ist, dass ich im letzten Jahr angefangen habe ein paar Buecher (und viele Comics) nochmal zu lesen, deren erste Lektuere 10, 15 oder gar (mehr als) 20 Jahre zurueck liegt.
Bei den Buechern lese ich nur solche nochmal, die einen herausragenden Eindruck hinterlassen haben. Oder wo ich das Gefuehl habe, dass ich die nochmal lesen sollte, weil ich die beim ersten Mal mlgw. nicht so richtig verstanden habe und sich das irgendwie wichtig anfuehlt. Bei den Comics lese ich alles nochmal. Nicht weil die so gut sind (obwohl viele es durchaus sind), sondern aus nostalgischen Gruenden.
Man beachte den Gebrauch des Plurals, woraus die Miniserie folgt.
Beim nochmaligen Lesen mache ich mir natuerlich Gedanken und wenn die es meiner Meinung nach wert sind aufgeschrieben zu werden, dann wird daraus ein kurzer Artikel … bzw. bei den Comics møchte ich gerne Cover zeigen … und dann denke ich mir dazu eben auch noch Text aus.
Los geht’s mit dem ganz fantastischen (ein wiederkehrendes Thema) Die Hyperion-Gesaenge von Dan Simmons. Die gesamte Serie umfasst vier Buecher (und ein paar Kurzgeschichten), aber ich meine damit nur die ersten Beiden, welche ich in einer Gesamtausgabe habe:

Ich las die Buecher zum ersten Mal nach meinem Studium (aber bevor es nach Norwegen ging) und habe sie „verschlungen“ und als definitiv (und zu Recht) zu den wichtigen Buechern des Sci-Fi-Genres zu zaehlenden empfunden; Letzteres wird ein zweites, wiederkehrendes Thema in dieser Miniserie.
Kurioserweise ist dieses Gefuehl, dass ich etwas Ueberragendes gelesen habe, so ziemlich das Einzige was ich noch von dem Buch wusste. Von der Story wusste ich im Wesentlichen nur noch, dass ein paar Reisende zu irgendwelchen Ruinen unterwegs sind … dies ist dann ein Drittes wiederkehrendes Thema — dass ich den Inhalt der gelesenen Buecher vergessen habe (das ist aber mitnichten schlimm, denn dadurch kann ich das alles nochmal als (fast) neu erleben … toll wa).
Beim zweiten Lesen wurde dieses Gefuehl zum Glueck bestaetigt.
Die Hyperion-Gesaenge erschienen um 1990 und standen damit an einem Scheidepunkt der Sci-Fi. Die meisten „alten Meister“ hatten seit Jahren nix mehr produziert, welches in der Bedeutung ihren frueheren Werken auch nur nahe kam. Klar, dank William Gibson gab es seit ein paar Jahren Cyberpunk, aber das war nun auch schon etabliert. Gesehen aus dem Jahre 2023 gab es 1990 aber „neue“ (oder auch „moderne“ oder „zeitgenøssische“) Sci-Fi a la Ted Chiang, Liu Cixin oder (bedingt) China Mieville natuerlich noch nicht (bzw. steckte deren Entstehung erst in den ganz fruehen Anfaengen und war laengst noch nicht abzusehen). Nun wollte man aber dennoch etwas haben was den Sci-Fi-Epen besagter „alter Meister“ entspricht … und dann kamen (durchaus unerwartet) diese zwei Buecher und „belebten“ die (man kønnte sagen: „eher traditionelle“) Sci-Fi wieder :) .
Die Buecher sind natuerlich so toll, weil die Geschichte(n) spannend sind. Das liegt aber nicht nur an dem Erzaehlten an sich, sondern auch wie diese sich zusammenfuegen und die Charaktere darin agieren. Hinzu kommt all das Gesagte mit Bezug auf das „Hintergrunduniversum“.
Im ersten Teil (eigtl. im ersten Buch, aber die sind bei mir ja zu einer Ausgabe zusammengefasst, weswegen ich „erster Teil“ sage) gibt es zwar gewaltige Brueche in den Geschichten besagter Charaktere (zum Teil wird das Genre komplett veraendert, wenn auch innerhalb der Sci-Fi bleibend), aber der „Fluss“ ist ganz hervorragend und traegt gewaltig zur „Tollheit“ bei. Dies sowohl intern (also innerhalb besagter Geschichten) als auch extern (also das Hintergrunduniversum betreffend).
Und dann ist da noch die Sprache … also das „wie es geschrieben ist“. Manche Autoren haben es echt drauf und zumindest in diesem Buch zaehlt Dan Simmons zu diesen Autoren; auch in der dtsch. Uebersetzung.
Lang Rede kurzer Sinn: wer sich fuer Sci-Fi interessiert sollte es unbedingt lesen; fuer Leute dich sich nicht fuer Sci-Fi interessieren ist es immer noch lohnenswert, eben weil es so gut ist (insb. der erste Teil).
Die Fortsetzung(en) habe ich nicht als so herausragend in Erinnerung und deswegen auch (erstmal) nicht vor nochmal zu lesen.