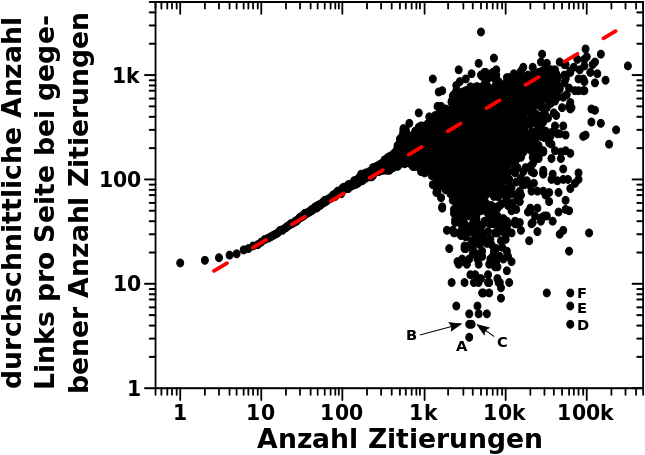
Der schwarze Fleck vom vorletzten Mal suggeriert, dass die Anzahl der Links unabhaengig ist von der Anzahl der Zitierungen fuer Seiten mit weniger als 1000 Zitierungen.
Bei dieser Aussage schaute ich aber nur auf die individuellen Seiten (die vielen vielen vielen Punkte, die zusammen besagten schwarzen Fleck ergeben) und habe nicht die Anzahl der Seiten mit der gegebenen Anzahl an Zitierungen in Betracht gezogen. Dies war aber genau das, was ich beim letzten Mal bei der individuellen „Signalstaerke“ machte.
Wenn man nun die individuelle Signalstaerke durch die Anzahl der Seiten und die Anzahl der Zitierungen, bei der gegebenen Anzahl an Zitierungen teilt, dann erhaelt man die durchschnittliche Anzahl an Links in Abhaengigkeit von der Anzahl der Zitierungen. Das muss man so machen, wenn man die Anzahl der totalen Links auf LL1 benutzt und ich erwaehne das hier, weil ich die ganzen vorherigen Artikel LL1 diskutiert habe. Auf LL0 muesste man natuerlich nur die Anzahl aller Links bei einer gegebenen Menge an Zitierungen, durch die Gesamtzahl der Seiten die so oft zitiert wurden dividieren. Egal wie man’s macht, DAS ist mal ein krasses Ergebniss:
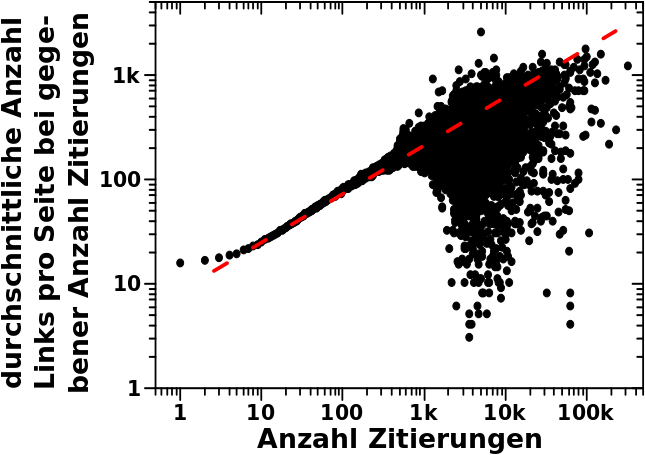
Die Abhaengigkeit folgt einem maechtigen Gesetz mit dem Exponent 1/2 (zwei Grøszenordnungen auf der Ordinate, vier Grøszenordnungen auf der Abzsisse) und einem Vorfaktor von ungefaehr 7.5 .
Das erstaunliche hieran ist, dass dies im Wesenlichen fuer den gesamten (!) Bereich auf der Abzsisse gilt, also egal ob die Anzahl der Zitierungen klein oder grosz ist.
Ich schreibe „im Wesentlichen“, denn natuerlich gibt es Abweichungen. So kønnte man in absoluten Zahlen durchaus auch sagen, dass die Anzahl der Links pro Seite fuer kleine Zitierungen halbwegs konstant ist. Die Abweichungen vom maechtigen Gestz betragen dann ca. einen Faktor zwei, fallen also bei realen „Anwendungen“ nicht sooo sehr ins Gewicht.
Ab ca. 1000 Zitierungen scheint es dann gewaltige Abweichungen zu geben. Aber das taeuscht hier wieder durch die bereits beim letzten Mal erwaehnte „logarithmische Komprimierung“ und die Ueberlappung hunderter (tausender) von Punkten.
Es gibt 4,696 „Messwerte“ mit ueber 1000 Zitierungen. Diese kommen durch insgesamt 15,282 Seiten zustande. Allein hieran sieht man, dass etwaige Abweichungen in diesem Bereich nicht relevant sind fuer die (immer noch) fast 6 Millionen Wikipediaseiten, die anscheinend dem Gesetz „gehorchen“. Aber wir sind ja nun konkret an den Seiten mit mehr als 1000 Zitierungen interessiert.
Zur Veranschaulichung der Taeuschung møchte ich die folgenden Werte anfuehren. Zunaechst setze ich (willkuerlich) fest, dass eine Abweichung von drei als nicht mehr OK gilt. Das bedeutet, dass ich es als Abweichung zaehle, wenn der tatsaechliche Durchschnittswert dreimal grøszer oder weniger als 1/3 des vom maechtigen Gesetz vorausgesagten Wertes ist.
Dies ist der Fall fuer 976 „Messwerte“ und entspricht ca. 21 % aller „Messungen“ mit ueber 1000 Zitierungen. Andererseits kommen diese 976 „Messwerte“ nur durch 1,303 Seiten zustande. Letzteres entspricht dann nur noch ca. 8 Prozent aller Seiten mit ueber 1000 Zitierungen. Das faellt dann also wieder unter den beruehmten Zehn-Prozent-Fehler.
Wenn ich viel strikter bin und Abweichungen ab einem Faktor 2 zaehle so erhøht sich der erste Wert auf ca. 38 % und der letzte Wert auf ca. 21 %. Das ist mehr als eine „normale Fehlerbreite“ erwarten laeszt. Die Aussage, dass die Mehrheit der Seiten dem maechtigen Gesetz unterliegt wird dadurch allerdings nicht beeinflusst.
Ach so, wenn man alle Punkte mit in diese Ueberlegungen einbezieht, also auch die mit weniger als (oder gleich) 1000 Zitierungen so fallen (bei Faktor 3) immer noch ca. 17 % der Punkte unter die Rubrik „Abweichung“, aber diese kommen dann nur noch durch ca. 2 % aller Seiten zustande.
Ich sagte ja, dass dieses Resultat voll cool ist! Beim vorletzten Mal schrieb ich:
[…] in diesen [vielzitierten] Artikeln [ist] vermutlich jedes kleine bisschen verlinkt […]. Je populaerer ein Artikel ist, um so mehr beinhaltet dieser vermutlich, was dann wiederum zu mehr Links fuehrt.
Dennoch, dies war eine spannendes Resultat, eben weil mich das so ueberrascht hat.
Diese Aussage entstand aus einem Bauchgefuehl und fuehlte sich logisch und richtig an, auch wenn ich es nur fuer Artikel mit mehr als 1000 Artikeln einschraenkte. Das obige Ergebniss zeigt aber ganz deutlich, dass dies nicht fuer die gewaltige Mehrheit ALLER Artikel gilt. Vielmehr existiert eine ganz konkrete, quantifizierbare Gesetzmaeszigkeit dahinter. Das haette ich nicht erwartet und das ist, was ich so krass cool fand.
Und das ist dann die Freude des Forschers. Man guckt sich kleine Details an (wie bspw. ein Balken in einer Verteilung der ein bisschen zu lang erscheint) und aus deren Erforschung ergibt sich eine allgemeine Gesetzmaeszigkeit fuer (mehr oder weniger) die gesamte Wikipedia! Geil wa!
Dies war definitiv einen eigenen Beitrag wert.
Aber Achtung! Das maechtige Gesetz gilt nicht zwangslaeufig fuer alle indivduellen Seiten. Der schwarze Block beim vorletzten Mal zeigte, dass die tatsaechliche Anzahl an Links einer Seite deutlich davon abweichen kann. Bei diesen Betrachtungen (und auch bei denen beim letzten Mal) werden individuelle Seiten unter dem Merkmal „Anzahl Zitierungen“ zusammengefasst. Und diese Ensembles verhalten sich im Durchschnitt wie oben angegeben! Das ist wie in der statistischen Mechanik, da betrachten wir auch keine einzelnen Atoemchen, sondern die potentiellen Zustaende eines System als Ganzes.
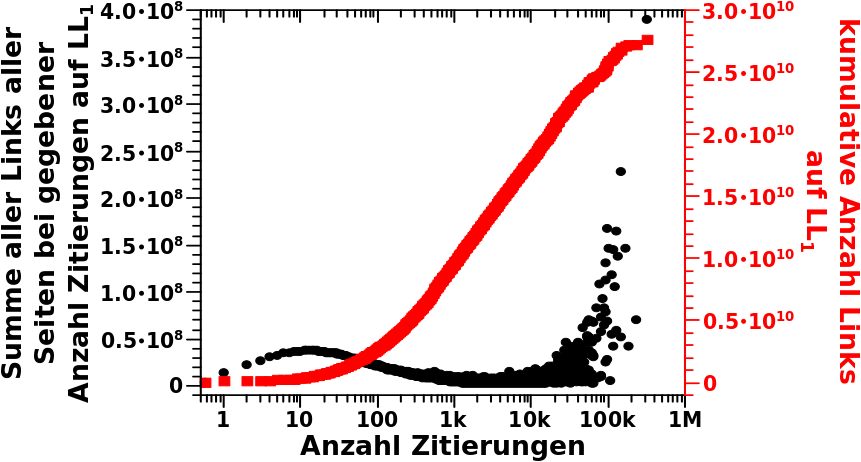
Ach so, das ist dann natuerlich der zweite Teil der Erklaerung, warum die rote „Gesamtsignalkurve“ im letzten Beitrag, trotz kleiner individueller Beitrage so stark ansteigt. Das sind zwar relativ wenige individuelle Seiten, aber die haben maechtig viel mehr Links.
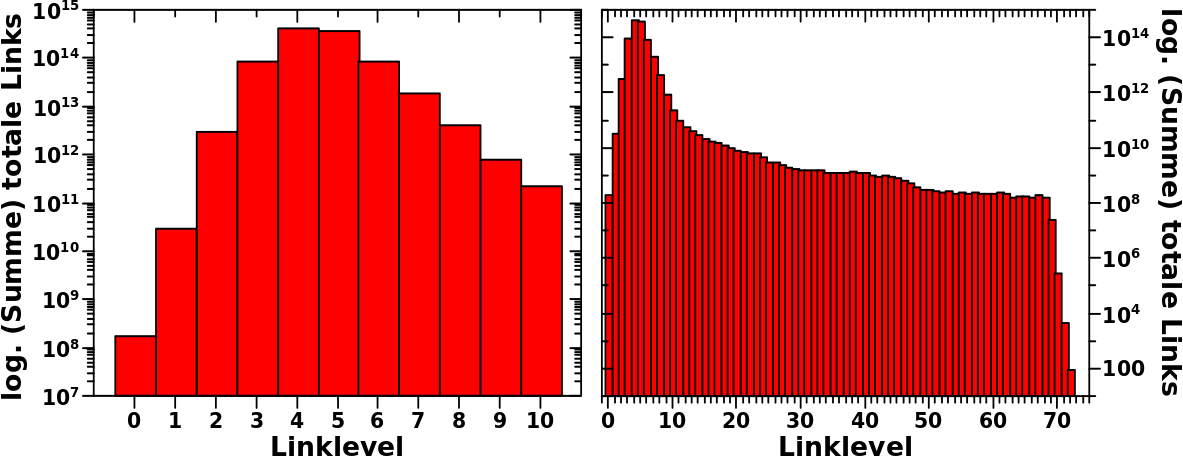
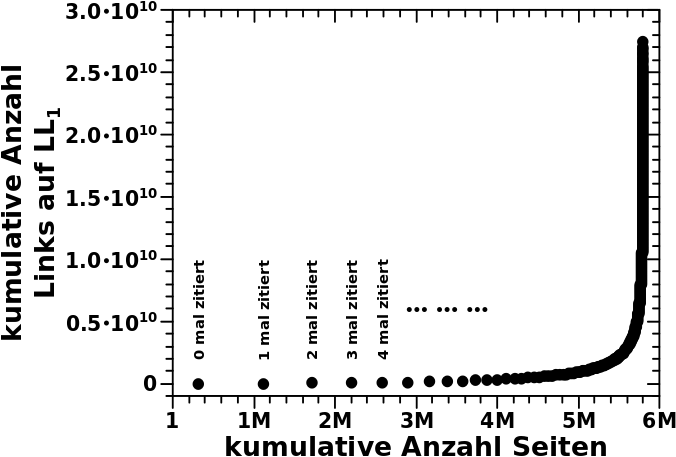
Ich habe in den letzten zwei und diesem Artikel dargelegt, dass vielzitierte Seiten ueberproportonal zur Anzahl der Links von LL1 zu LL2 2 beitragen. Beim naechsten Mal schliesze ich die Untersuchung dieses kleinen Details ab, mit einer Visualisierung, WIE gewaltig diese Ueberproportionalitaet wirklich ist.