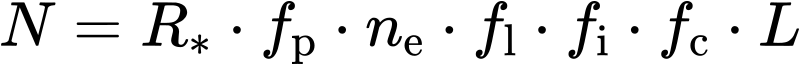Beim letzten Mal erwaehnte ich, dass fuer die Parameter der Drake-Gleichung derartig unterschiedliche Werte geschaetzt werden, dass man da urst krass verschiedene Resultate heraus bekommt. Das geht von einem leeren Universum (von uns mal abgesehen) bis zu so vielen auszerirdischen Zivilisationen, dass die sich fast schon gegenseitig auf die Fuesze treten. Die Literatur (meist die populaere, aber oft genug auch die wissenschaftliche) tendiert zu Letzterem — und das ist ja das Fermi Paradoxon.
Nun ist es aber so, dass bei der Berechnung von N, der Anzahl der Zivilisationen in unserer Galaxis, immer punktgenaue Werte fuer die Parameter genommen werden. Manchmal nehmen die Autoren dann noch andere (punktgenaue) Werte um zu zeigen wie unsicher die Rechnung ist. Das løst dann zwar nicht das Paradoxon, soll aber als ein Ausdruck fuer unser (wissenschaftliches) Unwissen angesehen werden. Und das ist eigentlich auch genau der richtige Weg … nur ist das nicht die richtige Herangehensweise, denn ein paar Werte in einer Gleichung zu aendern ist nicht systematisch.
Sandberg, A., Drexler, E. und Ord, T. (hiernach nur als SDO abgekuerzt) schauten sich unser Unwissen bzgl. der Parameter deswegen mal sytematisch an und meiner Meinung nach ist der Titel ihres Artikels mit „Dissolving the Fermi Paradox“ recht passend gewaehlt … wenn auch etwas provozierend, aber mich duenkt, dass das kalkuliert war (Wortspielkasse).
Als eine Nebenbemerkung: ich weisz nicht, wie ich arXiv-Artikel zitieren soll, auszer, dass ich den Link setze (in welchem die DOI steht fuer den Fall, dass der Link mal stirbt).
Aber der Reihe nach. SDO argumentieren, dass wir nicht nur irgendwelche zufaelligen Werte in die Drake-Gleichung einsetzen kønnen um irgendwas „zu zeigen“. Vielmehr sollten alle bisher publizierten Werte fuer die Parameter in ihrer Gesamtheit betrachtet werden. Dann ist der Unterschied in diesen Werten ein Ausdruck fuer unsere (wissenschaftliche) Unsicherheit. In den (zum Artikel) zusaetzlichen Dateien gibt es eine Tabelle, in der SDO alle (wissenschaftlichen) Quellen fuer die Parameter angeben, die sie finden konnten. Und die Unterschiede kønnen schon gewaltig sein. So gehen bspw. die Abschaetzungen fuer die durchschnittliche Lebensdauer einer Zivilisation von 45 Jahren bis 1 Milliarde Jahre. Oder die Werte bzgl. des Anteils der Planeten in der habitablen Zone mit Leben geht von 10-30 (!) bis 1. Ersteres ist echt urst krass klein, aber Letzteres bedeutet, dass Leben im Wesentlichen garantiert ist auf jedem Planeten der sich dafuer eignet. Andere Parameter hingegen haben eine viel kleinere Unsicherheit; die Schaetzungen der Sternentstehungsrate liegt bspw. zwischen 1 und 50 Sternen pro Jahr.
Das sind aber nur die Extremwerte. In viele Abschaetzungen findet man sehr aehnliche Werte fuer die Parameter. Das ist dann natuerlich Ausdruck fuer eine gewisse (wissenschaftliche) „Sicherheit“. Nicht unbedingt im Sinne von vorhandenen Messungen (die ohnehin nicht durchgefuehrt werden kønnen) aber im Sinne der Abschaetzungen eines Spock die Captain Kirk den sicheren Fakten anderer vorzieht. Nehmen wir bspw. nochmals die Werte fuer die Entstehung von Leben. Der extrem kleine Wert von 10-30 wird nur ein Mal angegeben. Hingegen wird in 17 Faellen abgeschaetzt, dass die Entstehung von Leben (beinahe) garantiert ist. Und dann natuerlich die Werte dazwischen.
In der Statistik spricht man von Sachen wie Varianz, Mittelwert und Median einer Verteilung. Man beachte, dass, abhaengig von der Art der Verteilung, solche Werte nicht immer angegeben oder gar definiert werden kønnen. Aber die Werte der Parameter der Drake-Gleichung sind logarithmisch normalverteilt (das bedeutet, dass der Logarithmus der Werte genommen wird und dann sind diese (logarithmierten) Werte normalverteilt) und da ist das alles kein Problem.
Damit kann man dann aber stochastische Modelle erstellen, in denen unsere Unsicherheit modelliert werden kann und wie sich das auf N auswirkt.
Was mit „unsicherheit modellieren“ gemeint ist, møchte ich eine mehr intuitive Erklaerung des Prozesses geben (um dann die rigorose statistische Modellierung SOD zu ueberlassen).
Wir wissen nicht, welche Werte fuer die Paramter „richtig“ sind. Und wie oben erwaehnt werden dann oft ganz andere Werte genommen, welche ein vøllig unterschiedliches Resultat zur Folge haben. Dieses wird dann im Umkehrschluss angesehen als „Beweis“, dass die Drake Gleichung nicht brauchbar ist.
Was aber, wenn wir nicht nur eine Rechnung, sondern eine Million Rechnungen machen? Und jedes Mal waehlen wir aus allen publizierten Werten (inklusive derjenigen die mehrfach auftauchen!) zufaellig aus, welcher denn fuer eine gegebene Rechnung benutzt werden soll. Dieser Prozess des „zufaelligen Ziehens“ von (publizierten) Werten modelliert auf eine gewisse Weise unsere Unsicherheit bzgl. der Parameter. Und weil wir das eine Million mal machen, kønnen wir statistische Aussagen ueber unsere Unsicherheit bzgl. N modellieren. Ich komme darauf nochmal zurueck, weil ich ja noch den Bogen kriegen muss, warum dies das Paradoxon aufløst.
Das habe ich mal gemacht und die Frage war dann: wie oft erhalten wir mittels dieser Methode „vertraute“ Resultate fuer N und wie oft Werte die ein leeres Universum bedeuten? Das Ergbniss meiner Rechnungen sieht man hier:
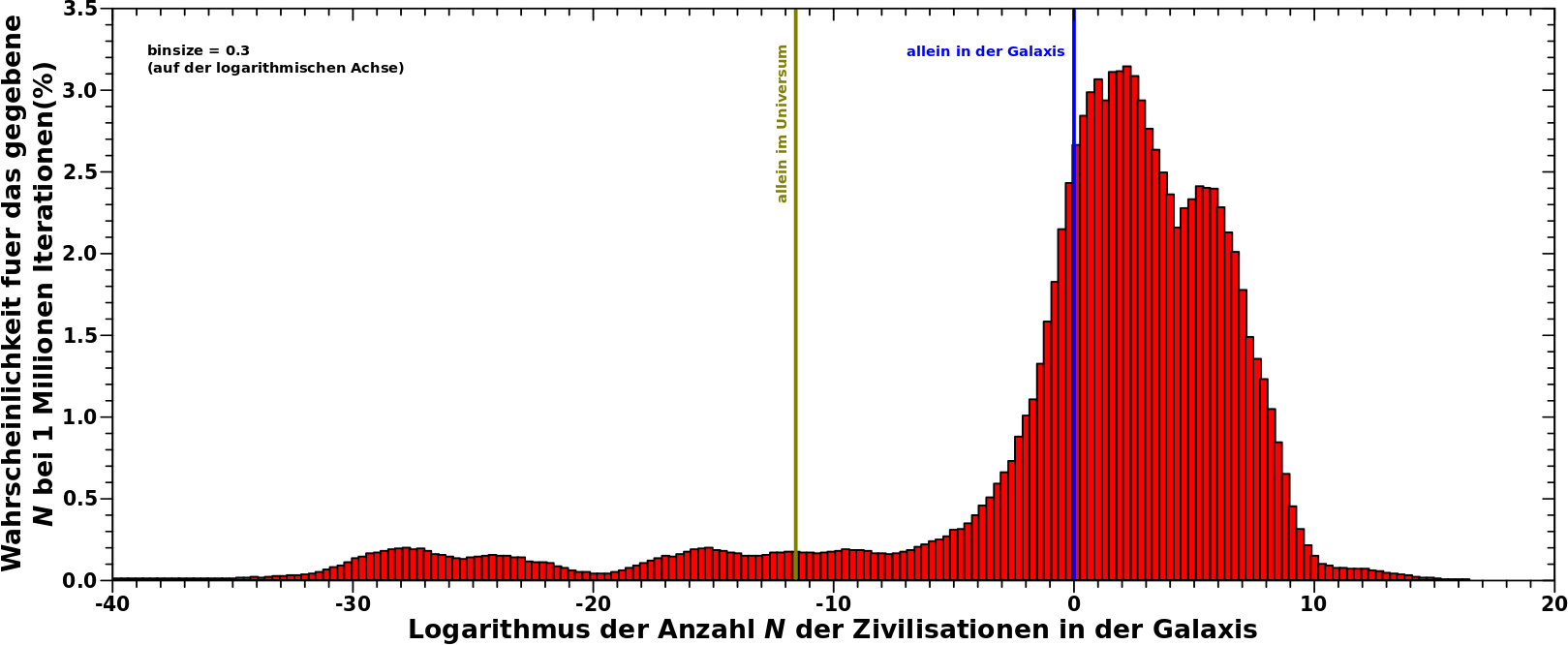
Man beachte, dass die Abzsisse logarithmisch ist. Sonst benutze ich die nicht-logarithmischen Werte (in diesem Fall fuer N) um die Achse zu beschriften und variiere den Abstand der kleinen Teilstriche entsprechend. Dieses mal benutze ich den logarithmierten Wert, also den Exponenten der Grøszenordnung des Wertes (vulgo, das „hoch y“ in „x mal zehn hoch y“). Von Strich zu Strich steigert sich der Wert von N also um einen Faktor zehn (!) auch wenn das linear aussieht!
Ich musste das so machen, weil es sonst nicht so schick ausgesehen haette, denn ich wollte das Ausmasz zeigen, ueber wie viele Grøszenordnungen sich N strecken kann. Und eigentlich geht das noch 15 Grøszenordnungen runter, denn die kleinsten Werten haben einen Exponenten von -65.
Das Maximum dieser Verteilung (jaja … da ist noch ein Nebenbuckel aber ich irgnoriere den mal) liegt bei 100 Zivilisationen in der Galaxis. Sehr haeufig erhaelt man sogar deutlich høhere Werte; bspw. eine Million oder gar eine Milliarde Zivilisationen in unserer Galaxis. Zunachst kønnte man da denken, dass das dann doch genau wieder das Fermi Paradoxon ist und in dem Sinne stimmt das auch, aber dann ignoriert man das, was Links des Peaks ist.
Die blaue Linie bei 100 markiert unsere (einzige) „Messung“: eine Zivilisation in unserer Galaxis. Und man sieht, dass die Wahrscheinlichkeit dort und auch bei Werten noch weiter links davon erstaunlich hoch ist. Geht man noch weiter zur (oliv)gruenen Linie, dann sind wir schon bei einem komplett leeren (observierbaren) Universum.
Kurze Abschweifung: New Horizons hat nicht nur ein paar Bilder vom Pluto gemacht (auch wenn mir scheint, dass dies das Einzige ist, was in der Øffentlichkeit wahrgenommen wird), sondern hat neben der Kamera auch noch ein paar andere Messinstrumente fuer uns mitgenommen. Eines davon hat gemessen, wie dunkel das Weltall denn eigentlich ist.
Das ist wichtig, denn in der Umgebung der Erde kann man das nicht machen. Hier gibt es total viel Staub und deswegen „glitzert und blinkert“ das auf allen Bildern von Messinstrumenten in der Naehe der Sonne (Naehe muss in diesem Satz gesamtsonnensystemtechnisch interpretiert werden). Das fuehrt dann dazu, dass man ganz schwache, weit entfernte Galaxien nicht sehen kann, weil die schwaecher leuchten als das „glitzern und blinken“. Aber wenn man weisz, wie stark das „glitzern und blinken“ ist, dann kann man aus der Anzahl der weit entfernten Galaxien die wir sehen abschaetzen, wie viele Galaxien wir nicht sehen kønnen.
Vor ein paar Jahren haben das mal ein paar Leute gemacht und die kamen zu dem Schluss, dass wir ca. 90 % der Galaxien nicht sehen. Die geschaetzte Zahl aller Galaxien im Universum lag dann (plusminus) bei 2 mal 10 hoch 12.
New Horizons hat nun, fern abseits des „Glitters“ im inneren Sonnensystems, festgestellt, dass das Universum deutlich dunkler ist als erwartet. Das wiederum bedeutet, dass es deutlich weniger unentdeckte Galaxien gibt. Man nimmt jetzt an, dass nur ungefaehr die Haelfte aller Galaxien nicht gesehen werden kønnen. Damit nimmt die Anzahl aller Galaxien im Universum um eine Grøszenordnung auf (plusminus) ca. 2 mal 10 hoch 11 ab.
Aber genug der Abschweifungen. Ich wollte nur kurz sagen wo der Wert des (oliv)gruenen Striches herkommt, weil das coole Wissenschaft (Wortspielkasse) ist.
Jedenfalls sehen wir im obigen Histogramm, dass selbst bei der (oliv)gruenen Linie noch ein betraechtliches „Signal“ ist! Die kumulative Wahrscheinlichkeit verdeutlicht besser, was dieses „Signal“ eigentlich bedeutet:
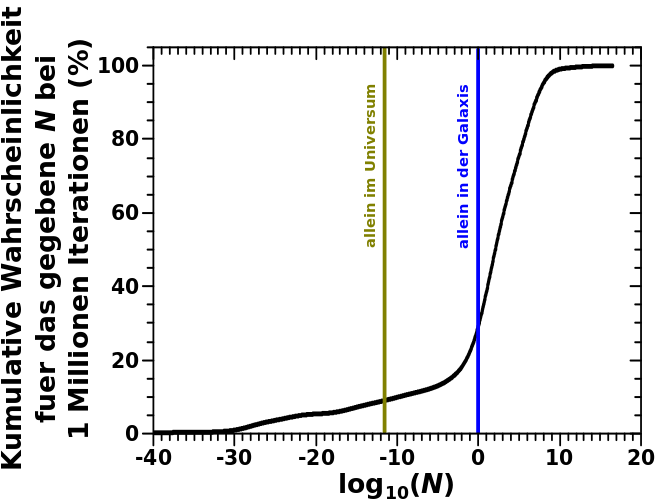
Die hier zu sehende Kurve stellt dar, wie grosz die Wahrscheinlichkeit ist, ein N zu erhalten welches kleiner oder gleich dem Wert auf der Abzisse ist. Man summiert also alle individuellen Wahrscheinlichkeiten (die einzelnen Balken im Histogramm) bis zu dem gegebenen N auf.
Wenn wir nun den Wert bei N = 100 ablesen, so erhalten wir eine kumulative Wahrscheinlichkeit von fast 31 %. So weit, so gut, aber was bedeutet das eigentlich? … Dafuer muss ich etwas weiter ausholen.
Um es gleich zu sagen: dieses Resultat bedeutet NICHT, dass wir mit einer Wahrscheinlichkeit von 31 % allein sind in unserer Galaxis.
Aber wie oben erwaehnt kennen wir die genauen Werte fuer die Parameter der Drake-Gleichung nicht. Unsere Unsicherheit drueckt sich in den verschiedenen (publizierten) Werten aus. Einige werden sicher naeher an der Wahrheit liegen als andere. Aber das wissen wir eben nicht. Bei den 1 Million Berechnungen wurde diese Unsicherheit „implementiert“, indem Werte zufaellig ausgewaehlt wurden und das hat das oben praesentierte Histogramm zur Folge.
Die kumulative Wahrscheinlichkeit (die ja aus dem Histogramm folgt) sagt uns nun, dass bei unserem derzeitgen Wissensstand, oder vielmehr bei unserer derzeitigen Unsicherheit bzgl. der Parameter, wir uns nicht wundern sollten, dass wir keine galaktischen Nachbarn sehen … oder høren? … aber Radiowellen sind ja auch nur elektromagnetische Wellen, also ist „Sehen“ gar nicht so verkehrt. Wieauchimmer, Letzteres ist die „Fermi Beobachtung“ und diese liegt absolut innerhalb dessen was zu erwarten ist, bei adaequater Betrachtung unserer Unsicherheiten.
Im Wesentlichen ist das das gleiche Argument, warum Physiker zehn Fantastilliarden Messungen machen bevor wir eine Entdeckung verkuenden. Selbst dann, wenn nach der 23. Messungen schon klar ist, was man vor sich hat. Eben um den „Raum der Møglichkeiten“ weiter einzuschraenken — oder anders: um unsere Unsicherheiten kleiner zu machen.
Aber mich duenkt SDO druecken das besser aus (alle Hervorhebungen von mir):
[…] this conclusion does not mean that we are alone (in our galaxy or observable universe), just that this is very scientifically plausible and should not surprise us. It is a statement about our state of knowledge, rather than a new measurement.
Und das ist dann auch die Aufløsung des Paradoxons! Denn …
[t]he Fermi observation […] provides only very weak evidence about whether we will soon go extinct or whether interstellar communication or travel is impossible.
Die Fermi Beobachtung ist unser (einziger) Messwert, der im Zusammenhang mit punktgenauen Angaben fuer die Parameter der Drake-Gleichung oft als Paradoxon interpretiert wird. Und dieses Paradoxon wird oft genug maximal fatalistisch interpretiert. Nur die Interpretation als Paradoxon ist bereits falsch, denn wenn man die Unsicherheiten ordentlich mit einbezieht, dann ist das ueberhaupt kein Paradoxon. Vielmehr ist die Fermi Beobachtung einfach nur eine weitere, gar nicht mal so unwahrscheinliche Møglichkeit in Raum aller Møglichkeiten. Oder anders (und wieder besser) in den Worten von SDO:
While using point-estimates in the Drake equation frequently generates estimates of N that would produce a Fermi paradox, this is just an artefact of the overconfidence implicit in treating them as having no uncertainty.
Und das finde ich natuerlich ziemlich knorke, wenn wir nicht alle garantiert sterben muessen.
Die obigen Berechnungen sind nur eine ganz krude Implementierung unserer Unsicherheit in die Diskussion rund um die Ergebnisse der Drake-Gleichung. SDO haben das dann noch rigoros mathematisch behandelt und kommen (bei unserem derzeitigen (Un)Wissensstand) auf gar noch deutlich høhere Wahrscheinlichkeiten, fuer das keiner-da-zum-spielen-Szenario.
Wobei zu sagen ist, dass diese Erkentniss nicht an und fuer sich neu ist. Im wissenschaftlichen (im Gegensatz zum populaeren) Diskurs wurde die Møglichkeit dass N = 1 ist immer als ein wahrscheinliches Resultat akzeptiert.
Zum Abschluss des Artikels møchte ich dann noch sagen, dass das obige Ergebniss auch komplett anders interpretiert werden kann: (sehr) grosze Werte liegen mit guten Wahrscheinlichkeiten innerhalb des Møglichkeitraumes und wir sollten absolut Lauschen ob einer unserer Nachbarn „Hallo“ sagt :)