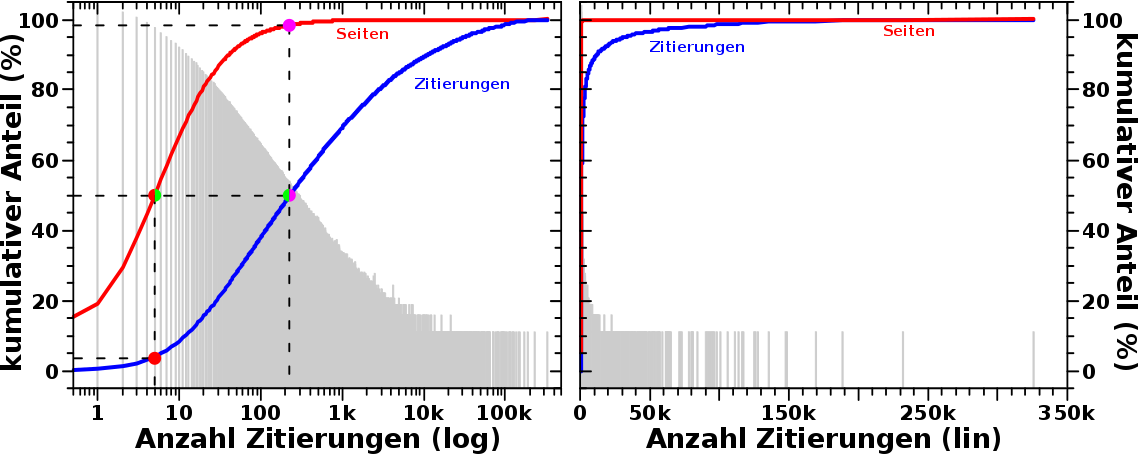
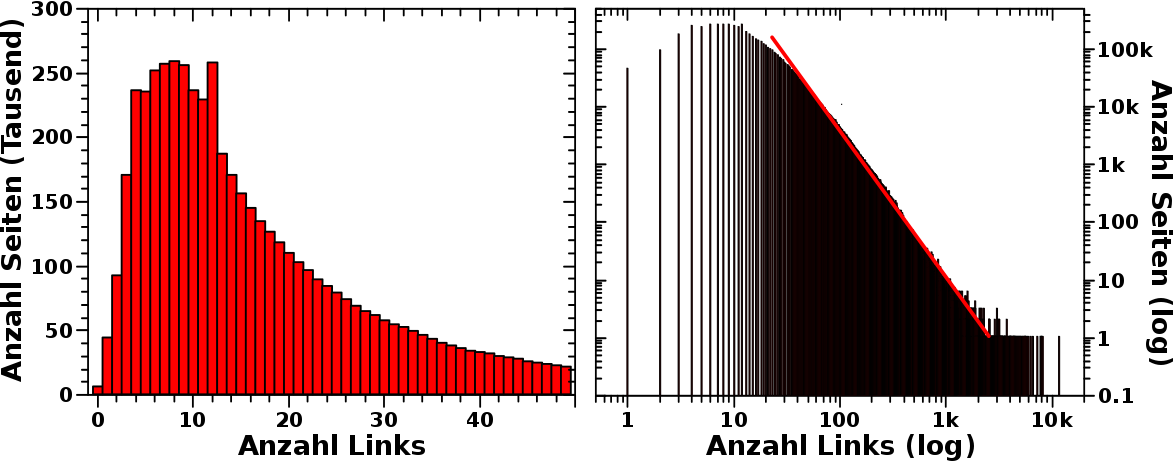
Kurze Wiederholung, weil es etwas komplizierter ist: beim letzten Mal stellte ich vor, dass sich die Relevanz von Wikipediaartikeln im Wesentlichen dadurch ausdruecken laeszt, indem man zaehlt wie oft ein Artikel zitiert wird. Der Einfachheit halber nenne ich hier Wikipeidaseiten mit kleinen Relevanzwerten „irrelevant“ (mit Anfuehrungszeichen). Das bedeutet nicht, dass die irrelevant (ohne Anfuehrungszeichen) sind.
Desweiteren stellte ich fest, dass die Wikipediartikel an den beiden Enden der Relevanzskala (die Artikel mit den kleinsten bzw. grøszten Relevanzwerten) vor allem von „irrelevanten“ Seiten zitiert werden. Daraus folgte, dass zumindest fuer die zwei meistzitierten Artikel die Relevanz nur deswegen zustande kommt, weil es die „irrelevanten“ Seiten gibt.
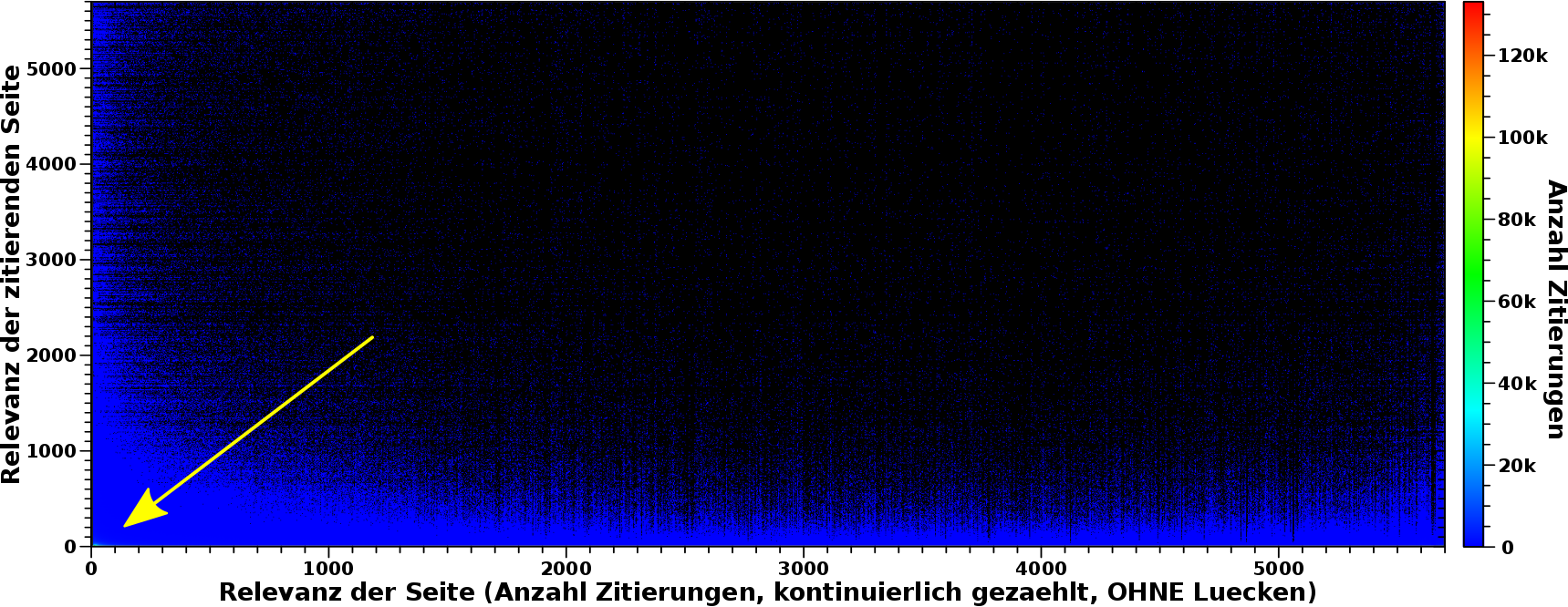
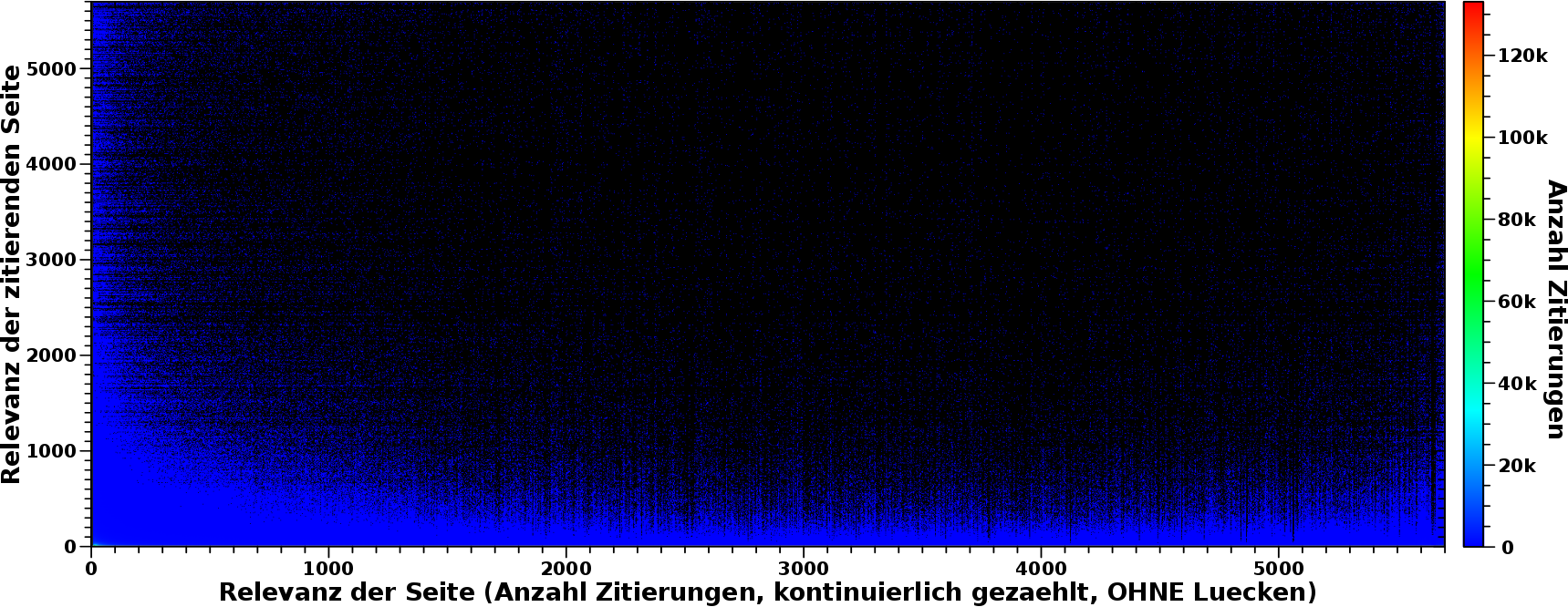
Das waren aber nur vier Beispiele und ich setzte mich mal hin und schaute mir das fuer _alle_ Wikipediaseiten an. Dies hier ist das Ergebnis:
Wenn das Bild geklickt wird, dann wird das grøszer.
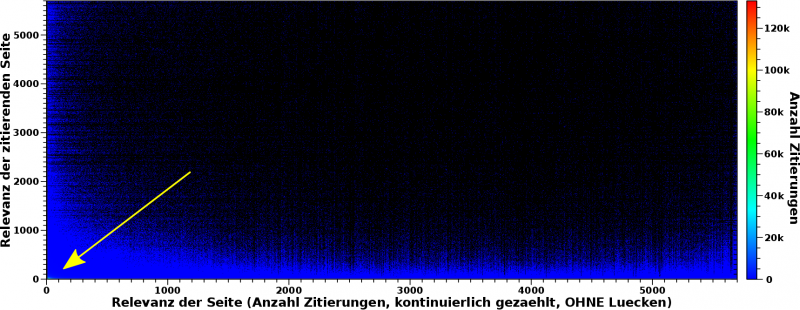
Was sieht man hier eigentlich? Die Abszisse repraesentiert den oben erwaehnter Relevanzwert einer Seite. Bis 2075 Zitierungen entspricht das der Anzahl der Zitierungen die eine Seite erhalten hat. Danach weichen die Relevanzwerte von der Anzahl der Zitierungen ab. Der Grund ist, dass die Werte der Abszisse das Resultat einer Abbildung einer Grøsze mit ungleicher „Schrittweite“ (Anzahl der Zitierungen) auf eine Grøsze mit konstanter „Schrittweite“ (Relevanzwert) ist. Ein kurzes Beispiel: es gibt keine Seite die 2076 mal zitiert wurde aber 2 Seiten die 2077 mal zitiert wurden. Der Relevanzwert zaehlt also „OHNE Luecken“.
Von der Bedeutung aendert sich aber nichts: je mehr Zitierungen eine Seite hat, desto relevanter ist diese (wohl) und entsprechend grøszer ist der Relevanzwert.
Die Ordinate repraesentiert im Wesentlichen die gleiche Grøsze, aber fuer die zitierende Seite.
Der Farbwert entspricht nun wie oft Seiten gefunden wurden, die einen bestimmten Relevanzwert haben und von einer (anderen) Seite mit einem (anderen) bestimmten Relevanzwert zitiert wurde.
Wenn also Seite A drei mal zitiert wurde von drei anderen Seiten die selber drei, elf und siebzehn mal zitiert wurden, dann zaehlt der Wert bei den „Koordinaten“ (3, 3), (3, 11) und (3, 17) ein mal hoch.
Wenn nun Seite B auch drei mal zitiert wurde, von Seiten die drei, sechs und sieben mal zitiert wurde, zaehlen die Werte bei den entsprechen „Koordinaten“ eins hoch. Der Wert bei (3, 3) ist nun zwei.
Diese Zaehlung habe ich nun fuer alle Wikipediaseiten gemacht und tritt fuer eine „Koordinate“ kein „Ereigniss“ auf, so bleibt das „Pixel“ fuer diese Koordinate schwarz.
Achtung: das obige Bild ist eine quadratische Matrix! Aufgrund gegebener Limitierungen in der Praesentation habe ich mich aber entschieden die Abszisse „laenger“ zu machen als die Ordinate.
Nochmal Achtung: Das ist zwar eine quadratische, aber keine symmetrische Matrix! Auch wenn auf den Achsen beide Male Relevanzwerte dargestellt sind, so ist die Bedeutung geringfuegig anders (wie oben beschrieben).
Wir sehen im Bild nun, dass das ueberwiegend schwarz ist. Bei den meisten Koordinaten zaehlt also nix hoch, weil es keine Seiten mit dem jeweiligen Relevanzwert gibt, die zitiert werden von Seiten mit dem (anderen) jeweiligen Relevanzwert. Schaut man genau hin, ist da „Rauschen“ drin. Ich komme da spaeter drauf zurueck.
Desweiteren sieht man, dass sich alles an der linken und unteren Kante abspielt — der blaue „Saum“. Das ist wichtig, denn dies ist eine Bestaetigung der beim letzten Mal getroffenen Aussage. Egal wie wichtig eine Seite ist (Wert auf der Abszisse), diese erhaelt ihre Wichtigkeit vor allem dadurch, weil sie von „irrelevanten“ Seiten zitiert wird (Wert auf der Ordinate). Das ist das blaue Band am unteren Rand.
Das blaue Band am linken Rand besagt nun, egal wie wichtig eine Seite (Ordinate) ist, diese zitiert vor allem „irrelevante“ Seiten (Abszisse). Und das ist krass!
Warum ist das krass? Nun ja, die erste Aussage (Wichtigkeit nur durch die Zitierung von „irrelevanten“ Seiten) ist ja eindeutig. Aber das Ganze geht noch weiter! Denn die zweite Aussage bedeutet, dass selbst die relevantesten Seiten ueber irrelevante Sachen schreiben (weil man ja zitieren muss worueber man schreibt).
Und DAS bedeutet dann nicht nur, dass relvante Seiten nur durch die Zitierungen irrelvanter Seiten relevant werden, sondern dass es relevante Seiten gar nicht geben wuerde, wenn diese nicht ueber „irrelevante“ Seiten schreiben kønnten!
DAS ist so krass, denn dies setzt der Relevanzdiskussion ein Ende und die Inkludisten sind die eindeutigen Gewinner!
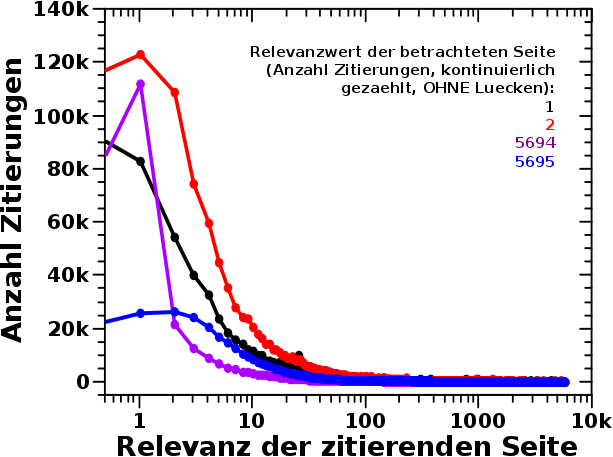
Das ist das Resultat. Nun ist’s aber nicht ganz so einfach … und warum geht die Farbskala eigentlich bis ueber 120-tausend Ereignisse, wenn im Bild entweder alles schwarz oder blau (ein paar tausend Ereignisse) ist?
Nun ja, deswegen ist da ein Pfeil im Bild.
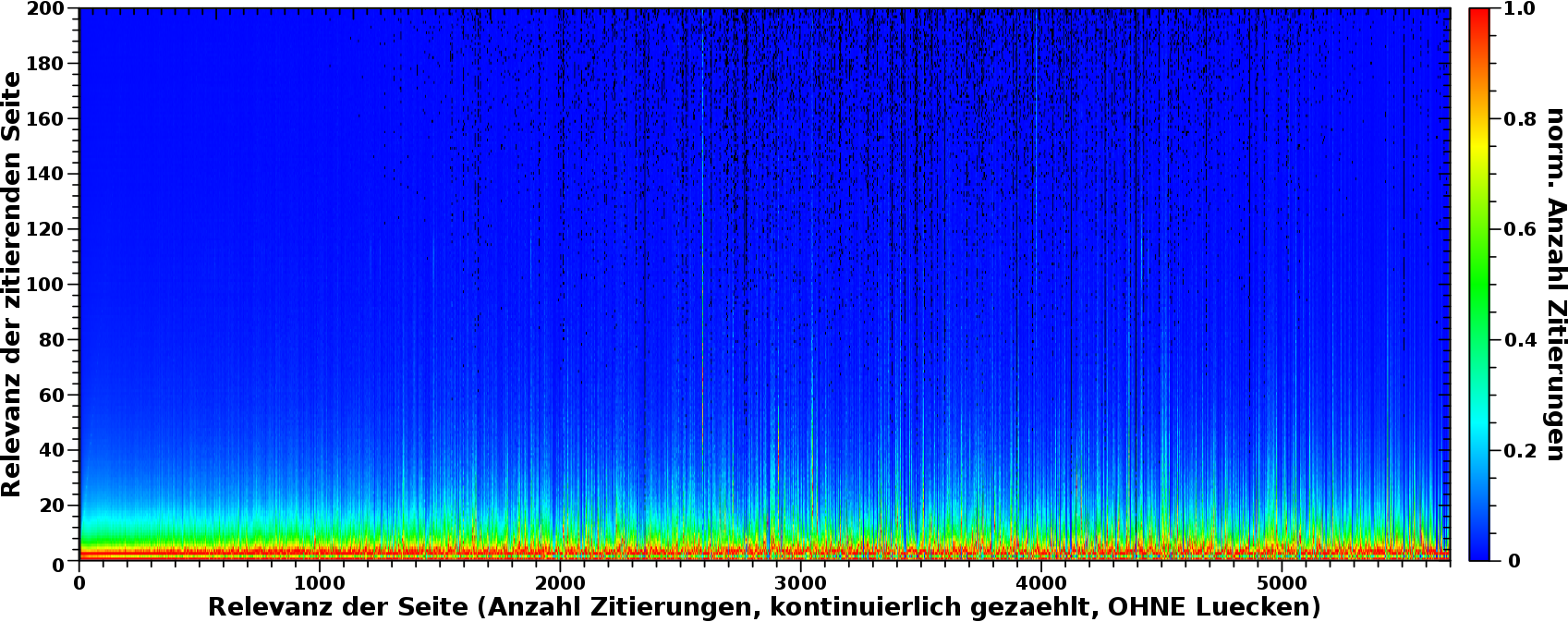
Ich zoome mal rein:

AHA! Da wird’s rot. Im Bereich bis zu Relvanzwerten von 100 passiert alles … bzw. nix, denn der schwarze Balken bei einer Relevanz von Null liegt natuerlich daran, dass diese Seiten null mal zitiert werden … aber ich schwoff ab.
Koordinaten fuer Seiten die ein bis zehn mal zitiert werden, von Seiten die selber null bis zwei Zitierungen haben sind im gelb/roten Bereich. Das sind also 10 mal 3 mal 100-tausend „Ereignisse“ die sich dort „versammeln“. Diese Gruppe ist umgeben von einem deutlich breiteren, gruenen „Halo“ welche Ereignisse mit Zaehlungen bis ca. 60-tausend beinhaltet.
Die Vielzahl der „irrelevanten“ Seiten die sich selber zitieren fuehrt zu so krass vielen Zitierungen (Ereignissen), dass das was in diesem Bereich angehaeuft ist vom absoluten Wert alles andere in den (blauen) Schatten stellt. Und weil die „Ausdehnung“ dieser Gruppe so klein ist, sieht man das im ersten Bild nicht.
Das ist jetzt natuerlich ein Problem in Bezug auf die obigen Aussagen. Die schiere Menge an Zitaten von (und an) „irrelevante(n)“ Seiten erdrueckt das Signal der Seiten mit grøszeren Relevanzwerten.
Aber zum Glueck ist dies mit einer simplen mathematischen Transformation sehr leicht in Betracht zu ziehen: jede Spalte muss normiert werden.
Das hørt sich jetzt fancy-pancy an, was das bedeutet ist aber, dass alle Werte in einer Spalte durch den grøszten Wert dieser Spalte geteilt werden. Besagter grøszter Wert wird dann natuerlich zu 1. Das Gute ist nun, dass ALLE grøszten Werte ALLER Spalten den Wert 1 haben. Dadurch wird das „Gewicht“ von der Farbskala genommen und Spalten mit groszen Relevanzwerten kønnen mit Spalten mit kleinen Relevanzwerten verglichen werden. Dabei ist natuerlich immer im Hinterkopf zu behalten, dass dies relative Vergleiche sind, im Gegensatz zum Vergleich der absoluten Werte in den obigen beiden Bildern.
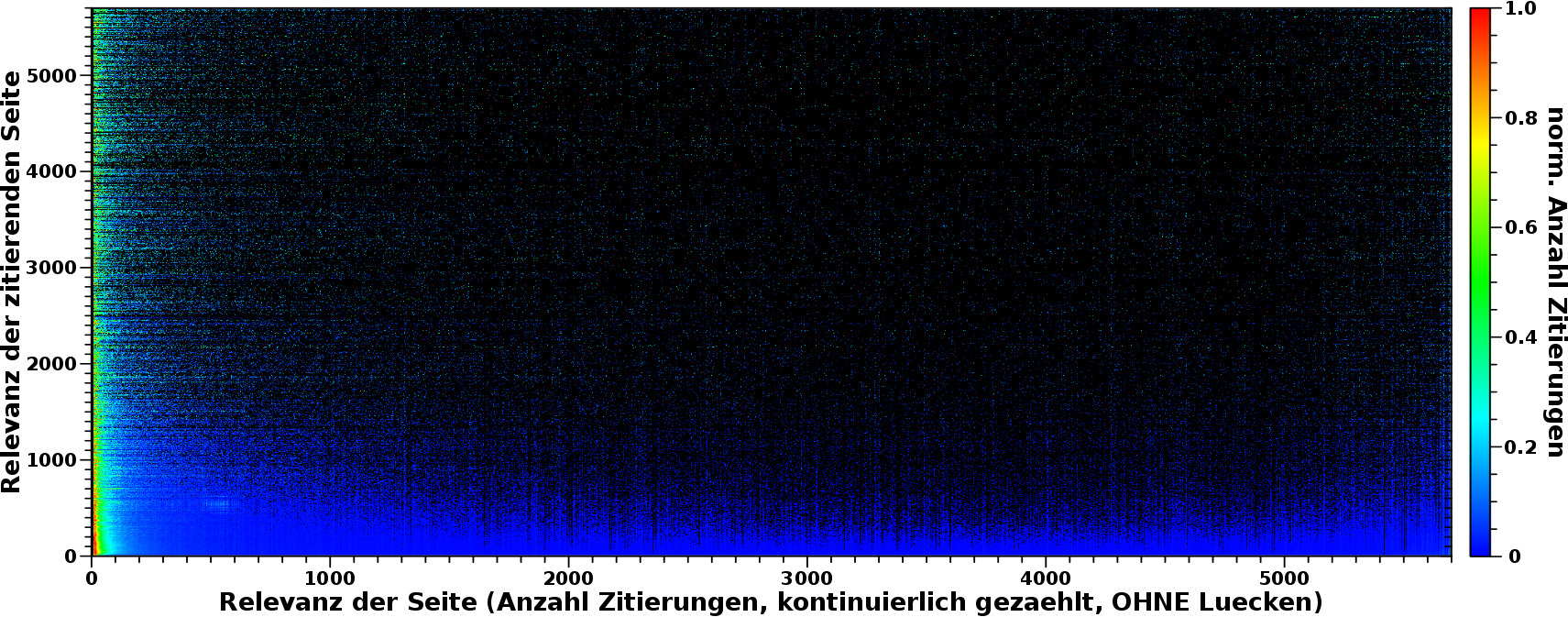
Und so sieht das dann aus:
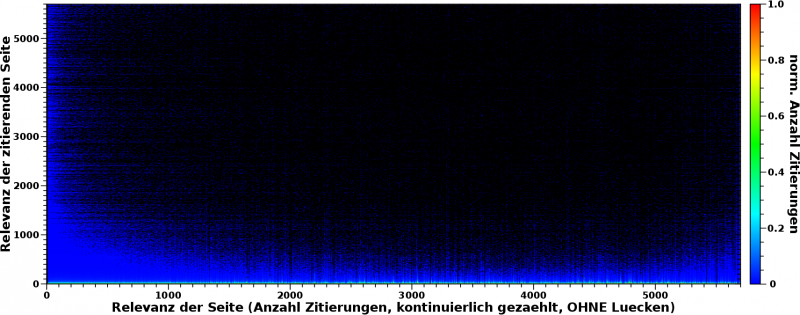
Haeh? What? Das ist doch das Gleiche! … Nun ja, nicht, wenn man ganz genau auf den unteren Rand schaut (ACHTUNG: die Ordinate geht nur noch bis 200 „Ereignisse“):
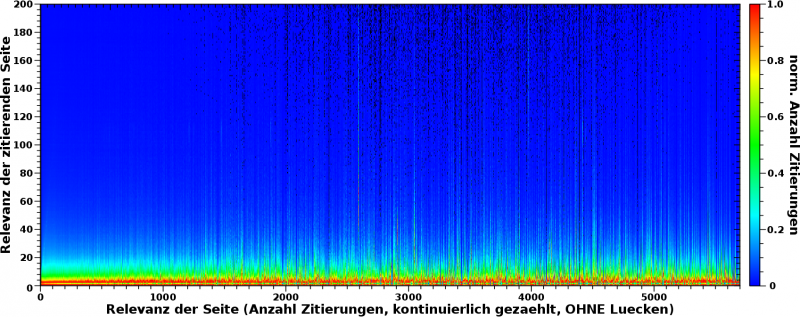
AHA! Das sieht doch schon ganz anders aus. Durch die Normierung wird (wie vorgesehen) der erdrueckende Anteil der Ereignisse bei kleinen Relevanzwerten irrelevant (tihihi). Das Resultat ist nun das rot gruene Band am unteren Rand. Dieses haelt die obige (erste) Aussage aufrecht: fuer ALLE Seiten, vøllig unabhaengig davon wie grosz (oder klein) die absolute Anzahl der Zitierungen ist, gilt, dass diese hauptsaechlich von „irrelevanten“ Seiten zitiert werden.
Das ist zwar das Selbe wie oben schon erkannt, aber es ist gut, dass diese Kontrolle nicht zu einem anderen Ergebis gefuehrt hat.
Aufmerksamkeit møchte ich richten auf die Tatsache, dass ein mal zitierte Seiten (Relevanzwert = 1, auf der Abszisse) interessanterweise weniger haeufig andere Seiten zitieren als null mal bzw. drei mal zitierte Seiten. Dies drueckt sich in dem duennen gruenen Streifen parallel zur Abszisse aus, der eingequetscht ist zwischen den roten Streifen bei Relevanzwerten (der zitierenden Seiten, also auf der Ordinate) von null bzw. zwei.
Man sieht das auch bereits in den nicht normierten Daten im obigen Bild. Dort sieht man dann auch einen Grund: der Wert bei der Koordinate (1, 1) hebt sich deutlich hervor im Vergleich zu den Werten bei (1, 0) bzw. (1, 2).
Dies wiederum deutet darauf hin, dass meine Erklaerung des „im Kreis zitieren“ vom letzten Mal …
[s]ozusagen wenn Hintertupfingen Vordertupfingen zitiert, weil’s das Nachbardorf ist (und umgekehrt), aber beide von keiner anderen Seite zitiert werden
… schon in die richtige Richtung geht fuer viele dieser Seiten. Denn wenn die ihr eines Zitat fuer die „Nachbardorfseite“ verbrauchen und umgekehrt, dann fehlt das „Signal“ natuerlich an anderer Stelle.
Dies wiederum waere dann aber auch ein Hinweis auf (mehr oder weniger) tataechliche Nichtrelevanz, da diese Seiten dann ja in keinem Diskurs teilnehmen, sondern nur eine Nabelschau sind. Ich persønlich wuerde die aber trotzdem drin behalten.
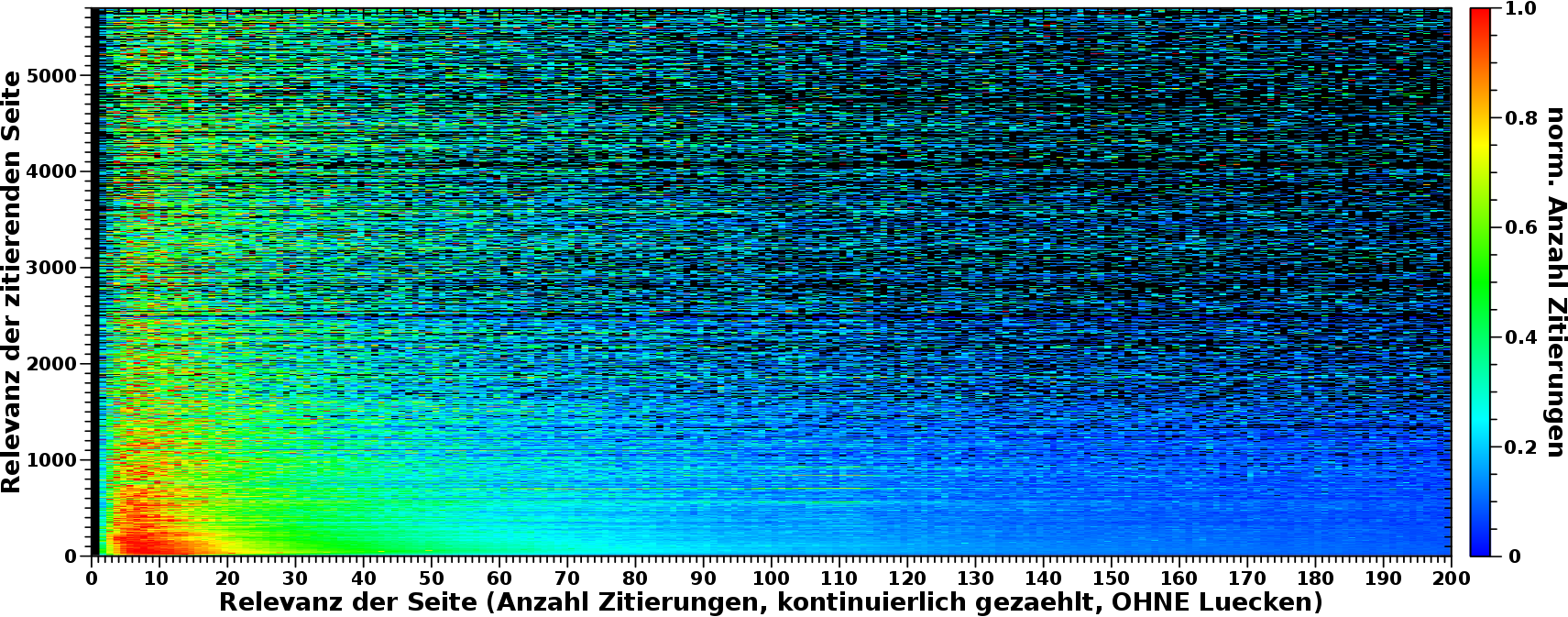
Genug dazu … wie sieht das nun mit der zweiten Aussage aus? Ueber was schreiben die (nicht nur relevanten) Seiten eigentlich? Dafuer muss man natuerlich alle Zeilen normieren und das sieht dann so aus:
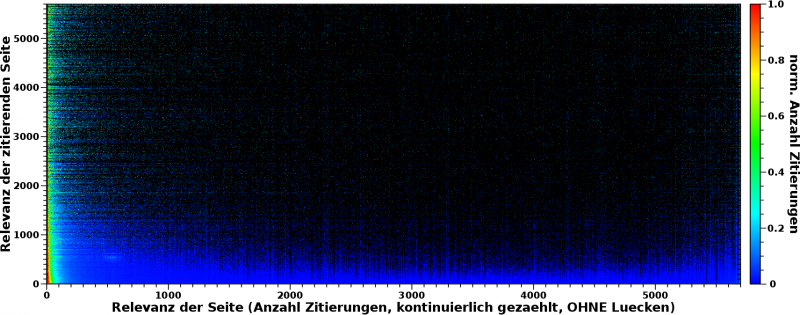
Aha! Ein bunter Streifen, der sich an die Ordinate schmiegt. Wenn man rein zoomt, dann sieht das so aus:
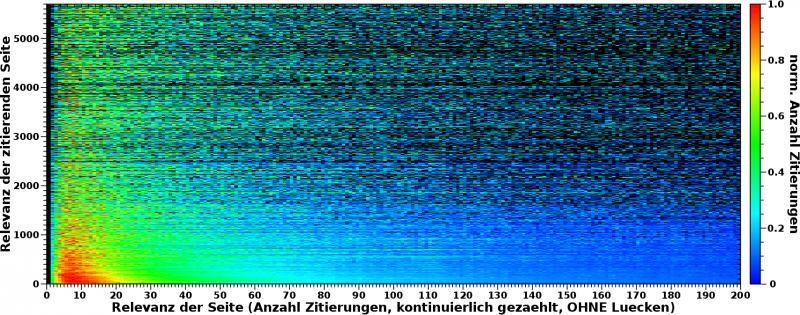
Im Allgemeinen bleibt also auch die zweite Aussage bestehen: ALLE Seiten zitieren hauptsaechlich „irrelevante“ Seiten. Das ist die Bedeutung des gruen-roten Bereichs am linken Rand. Aber das muss etwas genauer betrachtet werden.
Zum Ersten ist das, anders als beim obigen Fall, kein eindeutiges „rotes Band“ (parallel zur Ordinate in diesem Fall). Das „duennt aus“ je grøszer die Relevanzwerte der zitierenden Seite wird. Dies wiederum bedeutet, dass das „Signal“ bei høheren Relevanzwerten (auf der Abszisse) grøszer werden muss zu høheren Relevanzwerten auf der Ordinate. Nun sieht man das im Gesamtbild aber wieder nicht, weil das Gesamtsignal bei kleinen Relevanzwerten von vielen Seiten stammt, waehrend es bei groszen Relevanzwerten von wenigen, oft nur einer Seite „generiert“ wird. Die angesprochene Beobachtung geht also im „Rauschen“ unter.
Aber tatsaechlich, schaut man sich mal die Ecke bei den 1000 grøszten Relevanzwerten an …

… dann scheint sich da Information zu verstecken! In den zeilenweise normierten Daten geht das „Rauschen“ oft in den blauen und gar gruenen Bereich (manchmal gar in den roten). Hier ist also noch „was zu holen“.
Aber darum soll es beim naechsten Mal gehen: wie man das Mehr an Information aus den Daten kitzeln kann :)
Zum Zweiten liegt das Maximum des „roten Bereichs“ nicht bei Relevanzwerten von 1 oder 2 sondern eher bei Relevanzwerten von 5, 6 und 7. Dies ist zum Glueck einfach zu erklaeren.
Seiten mit den kleinsten Relevanzwerten werden zwar total gesehen am haeufigsten zitiert (die Anzahl der Seiten die nur ein mal zitiert werden ist grøszer als fuer alle anderen Relevanzwerte), aber wenn eine Seite mit Relevanzwert 1 ihr eines Zitat erhalten hat, dann ist diese Seite „verbraucht“. Die naechste Zitierung muss also zu einer anderen Seite mit Relevanzwert 1 gehen. Bis wir durch sind mit denen. Dadurch „verschmiert“ sich das Gesamtsignal fuer alle Seiten mit Relevanzwert ueber den kompletten Wertebereich.
Hingegen wenn eine Seite mit Relevanzwert 6 eine Zitierung bekommt, dann kann die noch fuenf weitere Male zitiert werden. JA, die Anzahl der Seiten mit Relevanzwert 6 ist geringer, aber das Produkt aus erhaltenen Zitaten und Anzahl der Seiten ist grøszer. Bei Relevanzwerten ueber sieben ist’s dann aber wieder so, dass die Anzahl der Seiten so stark abnimmt, dass besagtes Produkt wieder kleiner wird.
Das sieht man uebrigens auch im Bild mit dem „reingezoomten“ Bild mit den total Zahlen und deswegen erscheint das Maximum des „roten Bereichs“ der (zeilenweise) normierten Daten eher dort.
Dieses Wechselspiel aus totalen und normierten Zahlen bzw. vielen Seiten und vielen Zitierungen (bzw. dem Produkt aus beiden) muss alles im Kopf behalten werden waehrend der Interpretation dieser Diagramme. Ich gebe zu, dass dies nicht immer einfach ist. Ich sasz oft laenger da, ohne dass mir die Erklaerungen „ins Gesicht gesprungen“ ist. Vielmehr musste ich alle Gegebenheiten auseinanderklamuesern, mir genau ueberlegen was die Normierung (oder die Achsen, oder der Farbwert) eigentlich bedeutet, und total aufpassen, dass mir da nix durcheinander kommt um das Signal zu interpretieren und die Zusammenhaenge zu erkennen.
Und das ist einer der Gruende, warum ich das so toll finde. Einfach, kann ja jeder :)