Beim letzten Mal versuchte ich eine Erklaerung zu finden fuer einen der drei (hauptsaechlichen) Prozesse, welche die Verteilung der Laenge der Wikipediaartikel beschreiben. Ich dachte es liegt an der englischen Sprache an sich, dem war aber nicht so. Damit habe ich nur noch eine Idee: Personennamen.
Ich kann gar nicht sagen, wie ich darauf kam. Poppte einfach so in meinem Geist auf. Ist allerdings auch nicht zu weit hergeholt. Ein Name sind zwei Woerter und prinzipiell kønnte das Maximum der Verteilung der Laenge von Personennamen zu mehr Buchstaben verschoben sein.
Nun brauchte ich also nur noch rausfinden, was Wikipediaseiten zu Personen sind … und da ging’s dann auch schon los. Wie soll ich sowas aus nur dem Titel ausmachen? Klar, ich kønnte ein paar Heuristiken herausfinden, aber das waere laengst nicht adaequat.
Aber dann dachte ich das Folgende.
1.: Eine Person bekommt einen Eintrag auf Wikipedia, wenn diese einigermaszen interessant ist (mit einer _sehr_ weit gefassten Definition des Wortes „interessant“).
2.: Ob eine Person von Interesse ist, ist zwar abhaengig vom Erfolg (dito, bzgl. der Grenzen der Definition dieses Wortes) der Person und Erfolg ist definitiv abhaengig von der Persønlichkeit (und ich wuerde auch die Gene nicht unbedingt ausschlieszen), aber Beides ist vøllig unabhaengig vom Namen. Klar, es gibt Kuenstlernamen, aber das ist darob der Menge aller (mehr oder weniger) interessanten Personen nicht ausschlaggebend.
3.: Die Wikipedia konzentriert sich vor allem auf „den Westen“.
Mit diesen drei (ich denke doch durchaus plausiblen) Annahmen dachte ich mir dann weiter, dass ich ja dann nur ’ne Liste aller (westlichen) Personennamen braeuchte und dass die Verteilung der Laenge der Namen repraesentativ fuer die Laengen der Titel der Wikipediapersonenseiten sein sollte.
Das Dumme ist nun, dass es solche Listen ganz sicher gibt, dass die aber zu Recht (!) nicht øffentlich zugaenglich sind. Aufgrund von Annahme #3 kann ich aber auf zwei andere schøne Quellen zurueckgreifen:
– Listen von Babynamen und wie haeufig diese vergeben wurden … zurueck bis 1880 o.O
– Eine Liste von Familiennamen und wie haefig diese existieren.
Damit hatte ich zwar immer noch nicht das was ich wollte, ABER weil die Haeufigkeiten mit angegeben sind, konnte mir damit einen Namensgenerator bauen. Die Haeufigkeiten sind so wichtig, weil ich Namen ja gerade NICHT rein zufaellig erstellen will, sondern mit einer Wahrscheinlichkeit wie diese in der Bevølkerung auch tatsaechlich vorkommen, damit ich Annahme #2 nicht verletze. Einen John Smith, gibt es nunmal viel haeufiger, als den bereits erwaehnten Donald Fraser.
Bzgl. der generierten Namen sind mehrere Sachen zu bemerken.
I.: Der Namensgenerator erstellt keine Doppelnamen, auch keine die nur mit einem Buchstaben abgekuerzt sind. Mal schauen wieviel das ausmacht.
II.: Aufgrund des historischen, generationenuebergreifenden und laengst nicht ueberwundenen Sexismus gibt es vermutlich viel mehr (mehr oder weniger) beruehmte Maenner die eine Wikipediaseite haben. Das wird (hoffentlich) in 100 Jahren anders aussehen. Wieauchimmer, das sollte nix ausmachen, denn ich gehe erstmal davon aus, dass Maennernamen in ihrer Gesamtheit nicht laenger (oder kuerzer) sind als Frauennamen. Zumindest bei den Fantasienamen stellte sich diese Aussage im Nachhinein als richtig heraus.
III.: Vornamen sind Moden unterlegen … aber Moden sind zyklisch. Wenn man das ueber mehrere Jahrzehnte betrachtet, dann sollte sich da nicht viel aendern. … Das nahm ich zunaechst an, wusste aber auch, dass dies ein schwacher Punkt ist. Deswegen schaute ich mir die Aenderung der 13 meistvergebenen Vornamen in den letzten 140 Jahren mal genauer an und muss sagen, dass diese Annahme so nicht ganz richtig ist. Moden scheinen traditionelle Namen zwar nicht zu verdraengen, aber gesellschaftliche Entwicklung schon.
Da mache ich aber mal am besten einen eigenen Beitrag draus. Fuer die Argumentation hier ist das aber dennoch nicht relevant, denn die Verteilung der Laenge der Namen wird durch die Moden nicht signifikant beeinflusst. Wie gesagt, die Daten dazu liefere ich in einem kommenden Beitrag.
IV.: Zu Familiennamen habe ich leider keine Jahresdaten … ABER, ich gehe davon aus, dass die meisten Familiennamen deutlich stabiler sind als Vornamen, da diese von Gesetz (Heirat und Kinder muessen den Zunamen der zumindest eines Elternteils haben) und Gesellschaft (Erwartung den Namen des Mannes anzunehmen) massiv „geførdert“ werden. Deswegen sollten etwaige Aenderungen diesbezueglich nicht von Bedeutung sein. Zumindest nicht im relevanten Zeitraum, denn ich nehme an, dass die meisten Personenseiten von relativ modernen Menschen (die letzten ca. 150 Jahre) sind.
Ein Vorbehalt ist allerdings zu erwaehnen: Einwanderung. Da ich die Namenslisten der USA benutze, sollten nicht typisch westliche Namen durchaus vorkommen. Aufgrund der demographischen Entwicklung in den USA sollte deren Vorkommen sogar zunehmen die letzten paar Jahrzehnte. Durch historischen, generationenuebergreifenden und laengst nicht ueberwundenen Rassismus werden Personen mit nicht typisch westlichen Namen allerdings systematisch vom reich und beruehmt werden im sog. „Westen“ abgehalten. Und reiche und beruehmte Leute in anderen Laendern werden systematisch von den Leuten die die Wikipedia schreiben ignoriert, weil das besagte Schreiber (aus naheliegenden, nicht (!) unbedingt rassistischen Gruenden) nicht interessiert. Auch hier kann ich wieder nur sagen: das wird (hoffentlich) in 100 Jahren anders aussehen.
Ich bin nun aber nur an der Laenge der Namen interessiert und nehme an, dass es zu jedem „Hernandez“ auch einen „Li“ gibt, so wie es zu jedem „Williams“ einen „Lee“ gibt. Apropos „kein Interesse drueber zu schreiben“ und „(historischer) Rassismus (im Westen)“ … schaut ihr, meine lieben Leserinnen und Leser euch mal die Laenge der jeweiligen verlinkten Namenslisten an und denkt euch den Rest selber.
Nun habe ich jeweils 1 Million Frauen- und Maennernamen generiert und gehe mit den obigen Annahmen davon aus, dass die Verteilung der Laenge dieser Fantasienamen durchaus repraesentativ ist fuer die Laenge der Titel der Wikipediapersonenseiten … und tatsaechlich …
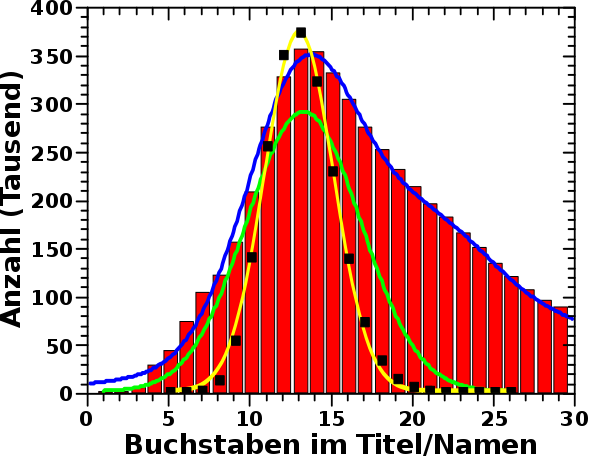
… zum Einen kann man die Verteilung der Laenge der Namen (schwarze Vierecke) wieder mit einer Gaussverteilung (gelbe Kurve) hinreichend gut beschreiben. Das bestaetigt mal wieder, dass ich gut damit fahre, meistens erstmal ’ne Normalverteilung mir unbekannter Vorgaenge anzunehmen. Zum Anderen stimmt das Maximum dieser Gaussverteilung weitestgehend ueberein mit dem Maximum des staerksten (die Laenge der Wikipediatitel bestimmenden) „Prozesses“ (gruene Kurve).
HURRA!
Einige Dinge fallen an diesen Daten auf. Aber es soll genug sein fuer heute. Weitere Betrachtungen zu dieser Problematik beim naechsten Mal.
Leave a Reply