Ich hatte zwei Ideen bzgl. der drei Gaussverteilungen welche die Verteilung der Laenge der Wikipediatitel beschreiben. Heute geht es um eine er beiden Ideen: die Verteilung der Laenge der Wørter der englischen Sprache.
Dafuer brauchte ich aber den englischen Duden, das Merriam-Webster Dictionary. Dieses Buch ist gemeinfrei und bei Project Gutenberg erhaeltlich. Allerdings sind da auch die Definitionen der Wørter mit dabei; die brauche ich aber nicht. Ja, die mit zu betrachten waere sogar schaedlich, denn bestimmte Wørter kommen viel øfter in Texten vor als andere Wørter. Das wuerde die Verteilung kaputt machen, da die Laenge dieser Wørter viel zu oft gezaehlt werden wuerde. In anderen Zusammenhaengen ist das bestimmt von Interesse. Bspw. wenn man die durchschnittliche Anzahl der Buchstaben in einem Buch abschaetzen will. Oder wenn man wissen will, welche Wørter besonders oft gebraucht werden. Aber nicht bei der Problemstellung die hier betrachtet wird.
Zum Glueck hat sich jemand anders bereits die Muehe gemacht und die Wørter von den Definitonen getrennt. Diese Datei nahm ich mir her und schaute mir mal die Verteilung der Laenge der Wørter der englischen Sprache im Vergleich zur Laenge der Wikipediatitel an:
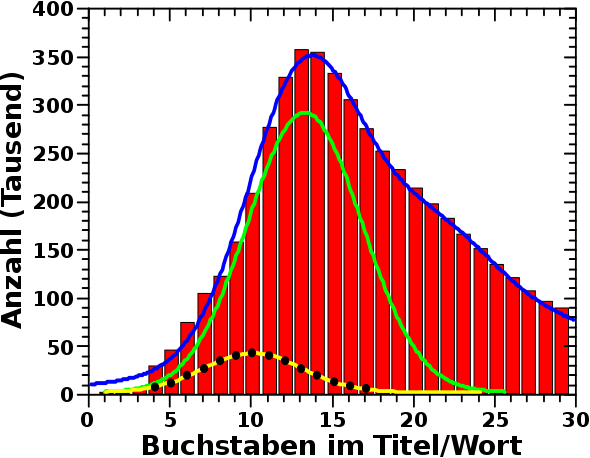
Bekannt vom letzten Mal sind die roten Balken (Verteilung der Laenge der Wikipediatitel, diesmal nur bis 30 Buchstaben), die gelbe Kurve (dies ist die erste, der drei oben erwaehnten, Gausskurven) und die blaue Kurve (die Summe besagter drei Gausskurven). Neu sind die schwarzen Punkte, welche die Verteilung der Laenge der Wørter im Merriam-Webster Dictionary darstellen und die gelbe Kurve.
Bevor ich zum Offensichtlichen komme ist zu sagen, dass die Verteilung der Laenge der Wørter der englischen Sprache tatsaechlich mit einer Normalverteilung zu beschreiben ist. Das dem so ist war meine Vermutung, denn ansonsten haette ich die Betrachtungen hier gar nicht ausfuehren muessen. Aber nach der Ueberraschung mit der „unnormalen“ Verteilung der Laenge der Wikipediatitel war ich mir gar nicht so sicher ob diese Vermutung ueberhaupt stimmt.
Das Offensichtliche ist nun, dass die englische Sprache viel zu wenige Wørter enthaelt um die roten Balken auch nur unter der gruenen Kurve zu fuellen. In dem oben verlinkten Wørterbuch befinden sich etwas mehr als 300-tausend Wørter. Weniger als in jedem einzelnen der vier laengsten Balken sind. Neuere Editionen umfassen ca. 470-tausend Wørter. Aber selbst wenn wir das auf 600.000 erweitern, wuerde das nicht ausreichen.
Nicht ganz so offensichtlich, aber beim zweiten Blick sieht man’s … naja … das war ehrlich gesagt das Erste, was mir aufgefallen ist … was wollte ich jetzt eigentlich sagen … ach ja: das Maximum der Verteilung der Laenge der Wørter in Merriam Webster liegt bei 10 Buchstaben. Das Maximum der gruenen Kurve liegt aber bei 13 Buchstaben. Das ist jetzt zwar kein himmelweiter Unterschied, aber dennoch deutlich. So deutlich, dass ich das nicht in irgendeinen „Fehler“ wuerde schieben wollen.
Lange Rede kurzer Sinn, die Laenge der Wørter der englischen Sprache an sich ist NICHT verantwortlich fuer den Verlauf der Verteilung der Laenge der Wikipediatitel. Das spielt sicherlich eine Rolle, aber die ist nicht ausschlaggebend im Groszen und Ganzen.
Bei anderen Wikipedias mag das anders sein. Ich habe aus Interesse mal die Wørter der dtsch. Sprache untersucht. Ganz den Vorurteilen entsprechend scheint die dtsch. Sprache eher laengeren Wørtern zugeneigt zu sein. Bei kurzen Wørtern gibt es keinen signifikanten Unterschied zwischen dtsch. und englisch im Verlauf der Verteilungen. Aber rechts vom Maximum (also zu laengeren Wørtern hin) hat die dtsch. Sprache (rote Punkte im unteren Bild) definitiv einen Ueberschuss verglichen mit Englisch (schwarze Punkte im unteren Bild).
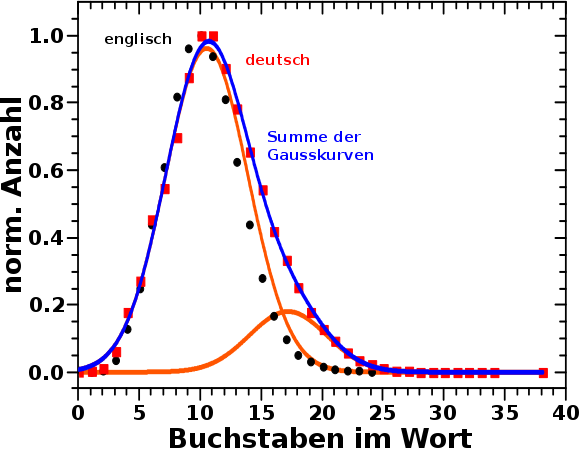
Ich denke, dass dies daran liegt, dass es im dtsch. viel mehr Kompositwørter gibt. OK, ich gebe zu, dass dieser Gedanke naheliegend war. Unterstuetzt wird diese Vermutung, dass sich die dtsch. Verteilung NICHT durch nur eine Gaussverteilung beschreiben laeszt, aber perfekt durch zwei. Das sind die beiden orangen Kurven im Bild. Aber ACHTUNG: die høhere orange Kurve beschreibt NICHT die Verteilung der Laengen der Wørter im Englischen, sondern ist die erste Gausskurve zur Beschreibung der Verteilung der Laenge der Wørter in der dtsch. Sprache.
Das Maximum dieser ersten Gausskurve liegt dann bei wie beim englischen bei ca. 10 Wørtern und die Form aehnelt sehr dem Verlauf der englischen Verteilung. Diese Kurve scheint also die Verteilung normaler „Einzelwørter“ zu sein. Die Amplitude der zweiten Gausskurve ist viel kleiner und Selbige sehr breit, mit einem Maximum bei 17 Buchstaben. Und 10 Buchstaben plus 7 Buchstaben … das fuehlt sich an, als ob das durchaus so’n durchschnittliches zusammengesetztes Wort charakterisiert.
Ach so, ich habe die Funktionswerte normiert, damit ich die Verteilungen besser vergleichen konnte. Aber das steht ja auch an der Ordinate.
Nochmal ach so: die Verteilung der Laenge der Wørter der dtsch. Sprache ist nur ’ne (zugegeben gar nicht so schlechte) Abschaetzung, denn ich habe nur eine Quelle mit einem relativ limitierten Wortschatz (ca. 88-tausend) benutzt. Eben das, was ich mal schnell im Internet, ohne lange Suche, gefunden hatte.
Wieauchimmer … schade eigentlich, dass die Laenge der Wørter der englischen Sprache NICHT die Laenge der Titel der Wikipedia erklaeren. Denn damit habe ich nur noch eine Idee, Namen von Personen, zur Erklaerung der Form der Verteilung … dazu mehr beim naechsten Mal.
Leave a Reply