So langsam aber sicher komme ich tatsaechlich zum Ende. Aber zunaechst geht’s nochmal ganz an den Anfang zurueck.
Dieses umfangreiche Projekt begann, weil ich ueber „Six degrees of Wikipedia“ stolperte und mich dann fragte wie viele Schritte (spaeter Linklevel genannt) man im Durchschnitt (!) braucht um von einer beliebigen Wikipediaseite zu einer anderen zu kommen. Dann liesz ich mich fast drei Jahre lang von fetizgen Sachen ablenken lassen und beantwortet die Frage die alles in Gang setzte erst am Ende.
Kurze Erinnerung: die Frage oben ist nur die eine Richtung in die man das beantworten muss. Die andere Richtung ist die Frage nach wievielen Linkleveln eine gegebene Seite im Durchschnitt (!) von einer beliebigen anderen Seite besucht (oder gesehen) wurde.
Ersteres kann man mittels der neuen Links (per Linklevel) beantworten, denn die sagen ganz direkt aus, wieviele noch nicht besuchte Seiten eine gegebene Ursprungsseite pro Linklevel sieht.
Fuer Letzteres kann man die Linkfrequenz heran ziehen, denn fuer eine gegebene Seite zaehlt diese pro andere Seite, ob die andere Seite die gegebene Seite auf einem spezifischen Linklevel gesehen hat.
Den Durchschnitt habe ich so definiert, dass der linklevelabhaenige, kumulative, prozentuale Anteil der jeweiligen Signale 50 % erreichen muss.
In den verlinkten Beitraegen gehe ich darauf ein, wie man besagten kumulativen, prozentualen Anteil berechnet und was es dabei zu beachten gibt. Zur Erinnerung: bei der Linkfrequenz kommt es zu Mehrfachzaehlungen, weswegen dieser Anteil ueber 100 % liegen kann. Das soll dazu aber reichen.
Desweiteren untersuchte ich das alles fuer unterschiedliche Gruppen. Die Mitglieder dieser Gruppen wurden danach bestimmt, wieviele Links eine Seite hat, oder wie oft andere Seiten zu einer Seite Links haben (diese also zitieren). Das teilte ich dann grob in Untergruppen mit wenigen, mittleren und vielen Links bzw, Zitaten ein … in kurz U(ntergruppe) W(enige) L(inks), UML & UVL bzw. U(ntergruppe) W(enige) Z(itate), UMZ & UVZ.
Zunaechst handle ich die „Vorwaertsrichtung“ (also alles was aus den neuen Links rausspringt) ab.
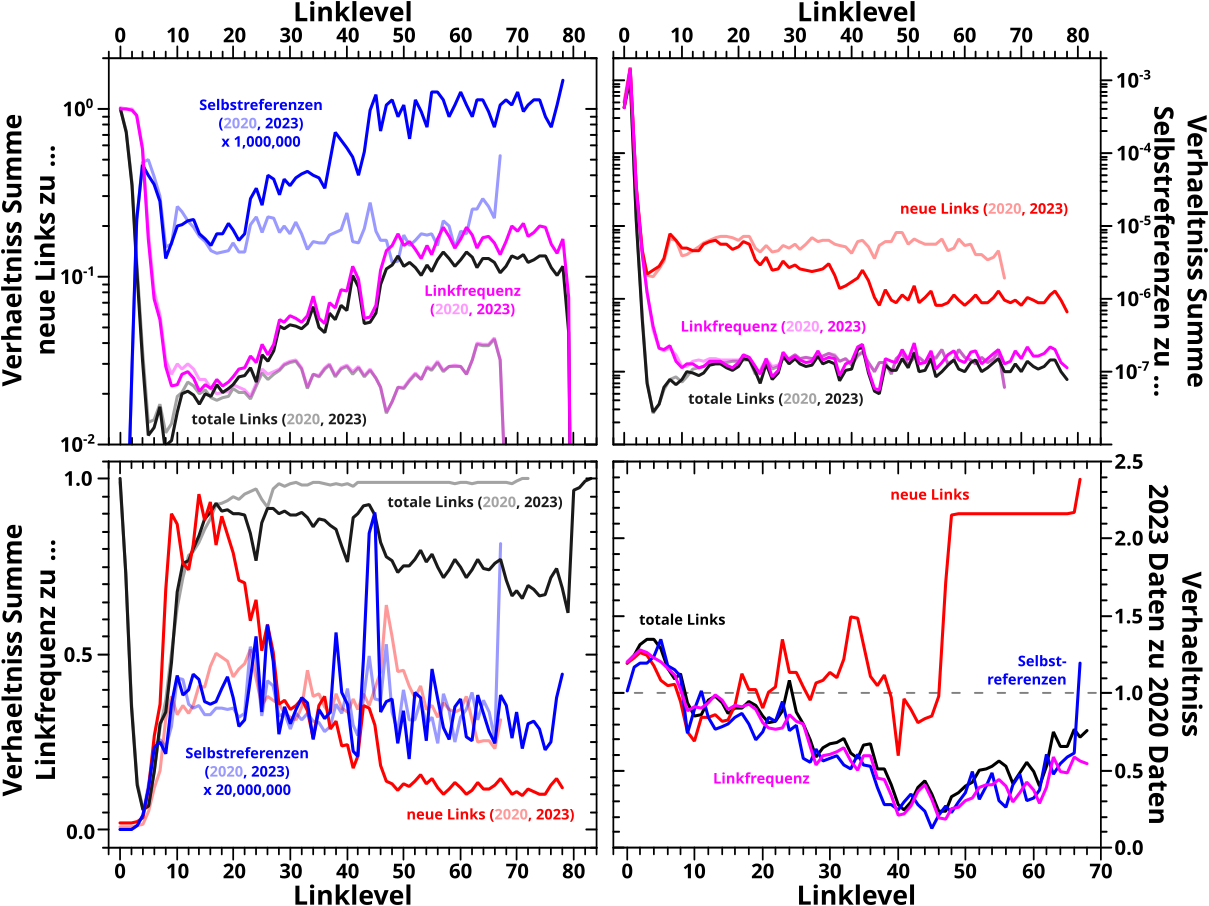
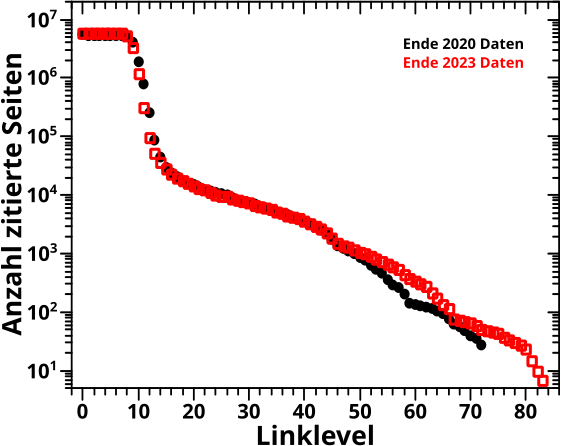
Die Grundlage des Ganzen sind die Summenkurven (ueber die jeweiligen Seiten). Damals hatte ich das nur fuer alle Seiten gezeigt, aber natuerlich interessiert mich bei der Reproduktion auch, inwieweit sich die Untergruppen, bzw. deren Dynamik geaendert haben. Hier also besagte Summenkurven fuer alle Gruppen:
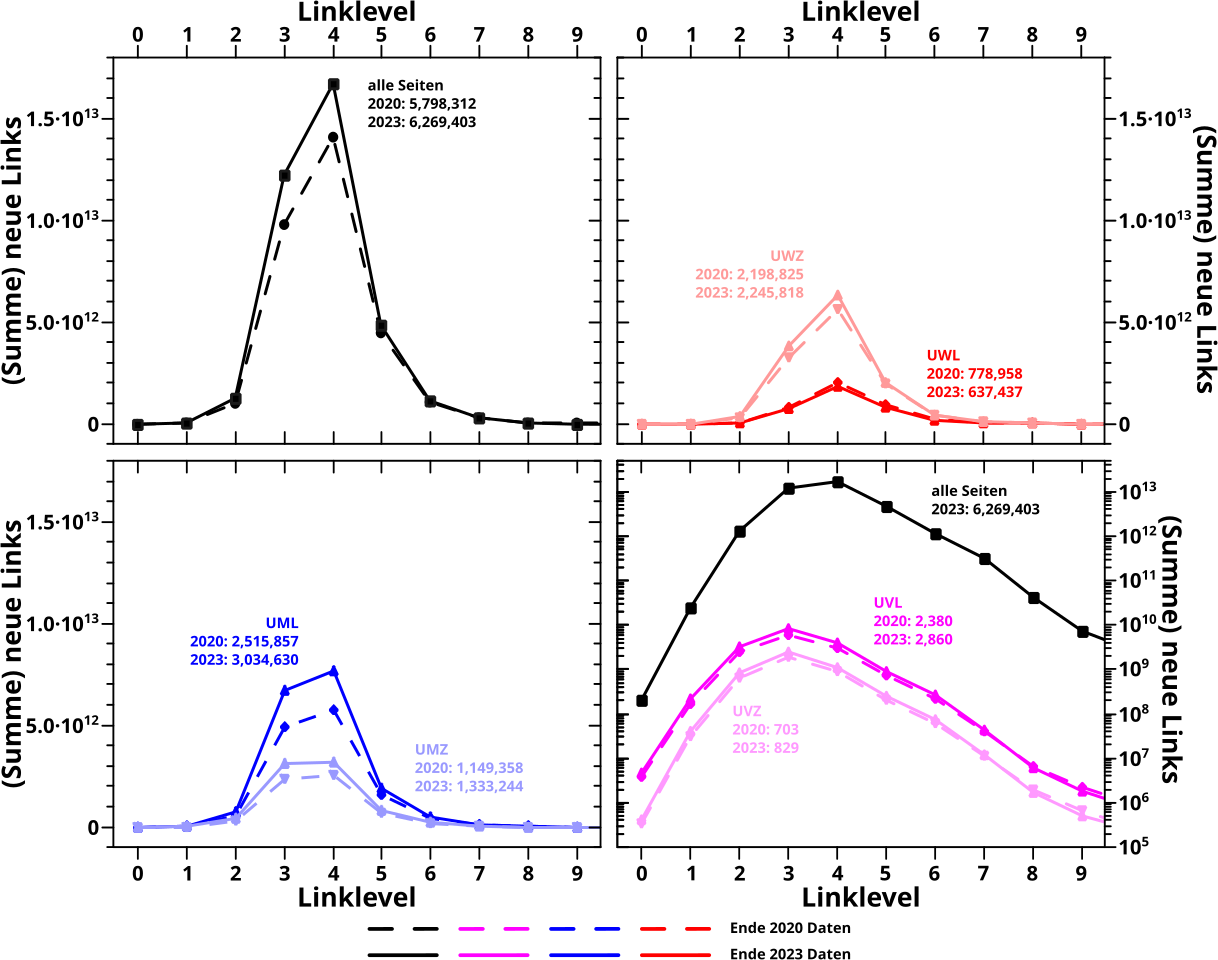
Weil’s so viel Kleinkram ist auf den man aufpassen muss und alles irgendwie gleich aussieht, zunaechst ein paar Worte zur „Notation“ in den heutigen Diagrammen (sofern man das bei einer Grafik sagen kann).
An den Kurven ist vermerkt zu welcher Gruppe sie gehøren und ich habe die (jahresabhaengige) Anzahl der Seiten auch mit ran geschrieben. Normalerweise nutze ich schwachfarbige Kurven um aus den alten Daten gewonnene Information zu kennzeichnen. Heute ist das NICHT so, denn damals kennzeichneten vollfarbige Kurven die nach Anzahl der Links sortierten Untergruppen und schwachfarbige Kurven gehørten zu den nach der Anzahl der Zitate (anderer Seiten) sortierten Untergruppen. Das behalte ich hier bei. Die unterschiedlichen Datensaetze sind hier und heute ausnahmsweise durch die „Strichform“ unterscheidbar; gestrichelte Kurven entsprechen den 2020 Daten und durchgezogene Kurven den 2023 Daten.
Man beachte, dass die Abzissen dreier Diagramme linear und gleich skaliert sind. Man kann die Werte also direkt vergleichen. Die nicht mal 3000 Seiten der UVL bzw. UVZ wuerden dann aber nur ’ne flache Kurve sein, weswegen ich dafuer auf eine logarithmische Skala gewechselt bin. Zum besseren Vergleich habe ich die Kurve fuer alle Seiten auch noch mit rein gelegt.
Was man sieht ist … naja … es gibt sichtbare Unterschiede, aber alles liegt im erwarteten Rahmen. Die Kurvenformen der verschiedenen Jahre sind alle SEHR aehnlich und zum Teil sind sogar die absoluten Werten nicht weit voneinander weg … oder anders: Reproduktion erfolgreich. Fuer alle Seiten wussten wir das schon vorher (siehe obiger Link), und nun wissen wir das auch fuer die Untergruppen.
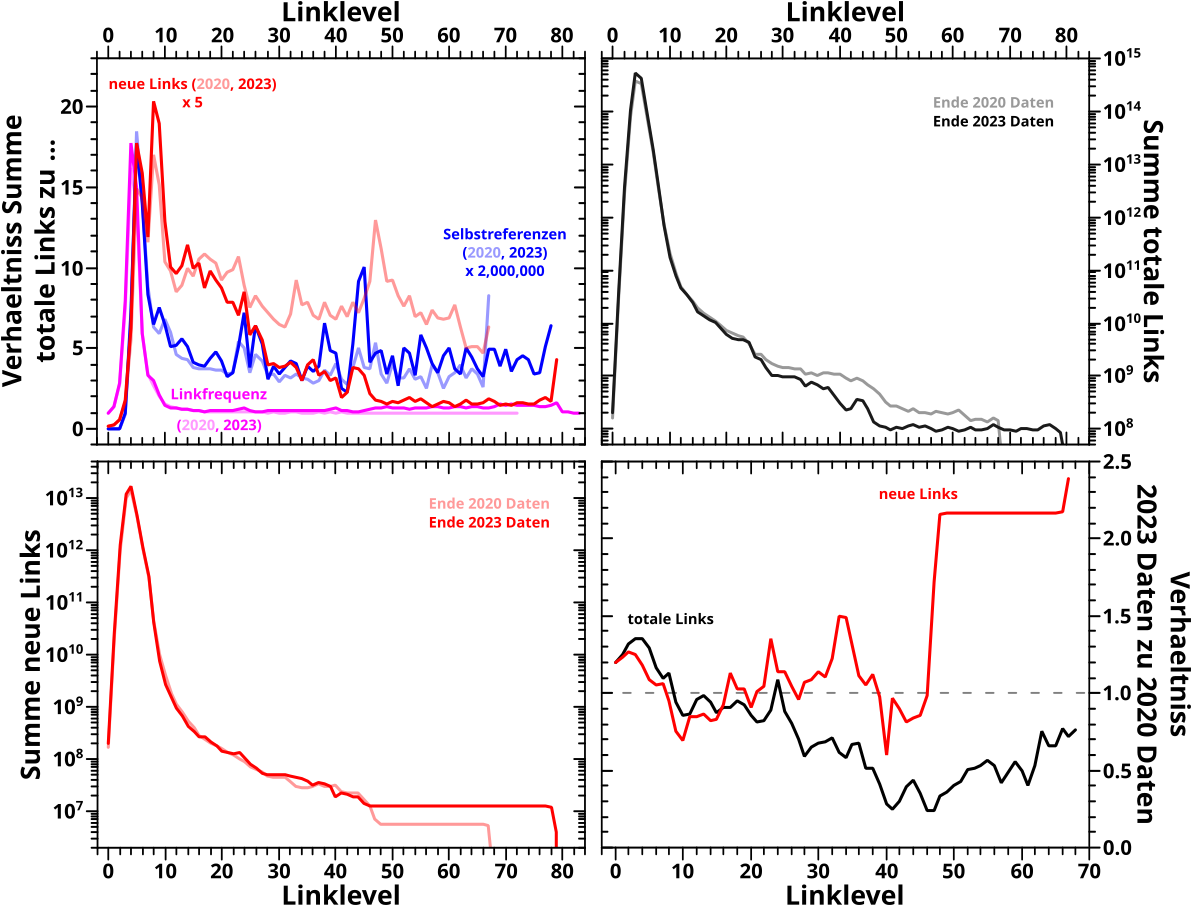
Wenn man dann die jeweiligen Berechnungen durchfuehrt, erhalt man diese kumulativen, prozentualen Anteile:
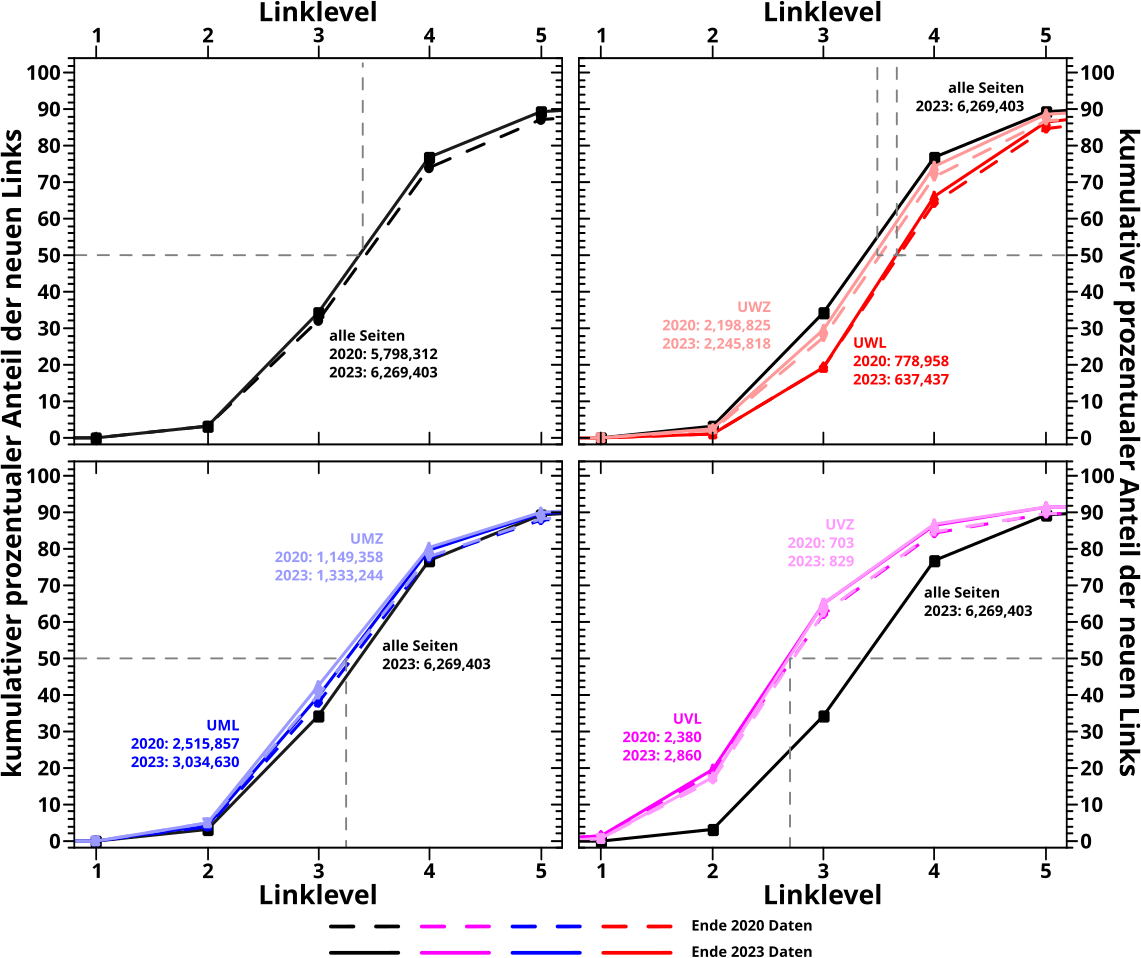
Ich habe wieder graue, unterbrochene Linien reingelegt, damit leichter zu sehen ist, wann die 50 % erreicht sind. Wie immer so oft gilt, dass die Striche zwischen den Datenpunkten nur zur Orientierung sind. Ansonsten gilt auch hier: Reproduktion gelungen.
Aber Achtung! Im Vergleich mit den damaligen Diagrammen im ganz oben verlinkten Beitrag gibt es einen Unterschied. Die Kurven hier erreichen NICHT 100 % … ist ja erstmal komisch, aber leicht zu erklaeren.
Damals dividierte ich das (doppelte) Summensignal nicht durch die Anzahl der Seiten die zu den jeweiligen Summen beitragen (auch wenn der Beitrag null ist!), sondern durch das Integral unter der Kurve. Prinzipiell ist das das Gleiche … es ist im vorliegenden Fall aber nicht das Selbe. Der Grund sind die Archipele. Die meisten Seiten kommen dort nicht hin und somit fehlen fuer jede Seite ungefaehr fuenf Prozent aller (neuen) Links. Deswegen erreichen die obigen Kurven die 100 % nicht.
Aber eben weil die Archipelseiten nicht gesehen werden, tragen die auch nicht zum Integral des Summensignal bei. Das kompensiert die fehlenden Werte und macht besagtes Integral zu einem kleineren Teiler als man eigtl. benøtigt. Und so erreichte ich urspruenglich fuer die neuen Links 100 Prozent.
Kurioserweise hatte ich es bei der Linkfrequenz auch damals schon richtig gemacht und sogar richtig argumentiert … hab das nur nicht auf die neuen Links uebertragen.
Apropos Linkfrequenz, hier sind die jeweiligen Summensignale:
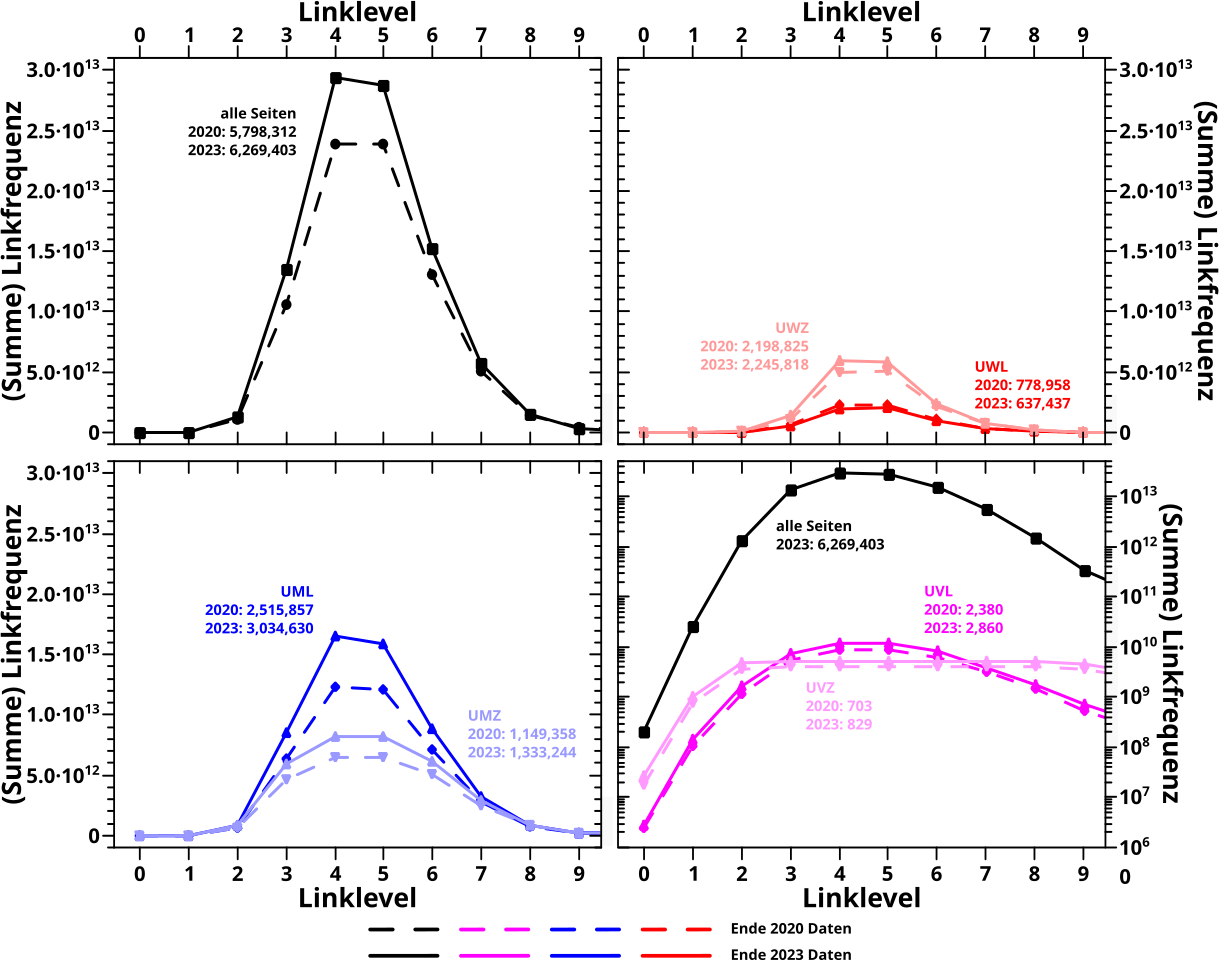
Im Wesentlichen gilt das Gleiche wie oben … oder anders: alles innerhalb der zu erwartenden Limitierungen reproduziert.
Kurios sind die UVZ Kurven (die ich mir damals nicht angeschaut hatte); ein ganz schøn flaches und sich weit streckendes Maximum. Das sieht auch bei linearer Abzisse (fast) so aus, wenn man da rein zoomt sieht man aber, dass es nicht komplett flach ist. Die Erklaerung dafuer ist ganz einfach und liegt in der Dynamik des gesamten Wikipedianetzwerks und der Besonderheit dieser Gruppe. Das sind die Seiten mit den vielen Zitaten von anderen Seiten. Oder anders: die werden so oft zitiert, dass alle diese Seiten ab LL2 im Wesentlichen von ALLEN anderen Seiten IMMER gesehen werden … zumindest bis ca. LL9.
Weiter zu den kumulativen, prozentualen Anteilen (am Linkfrequenzsignal):
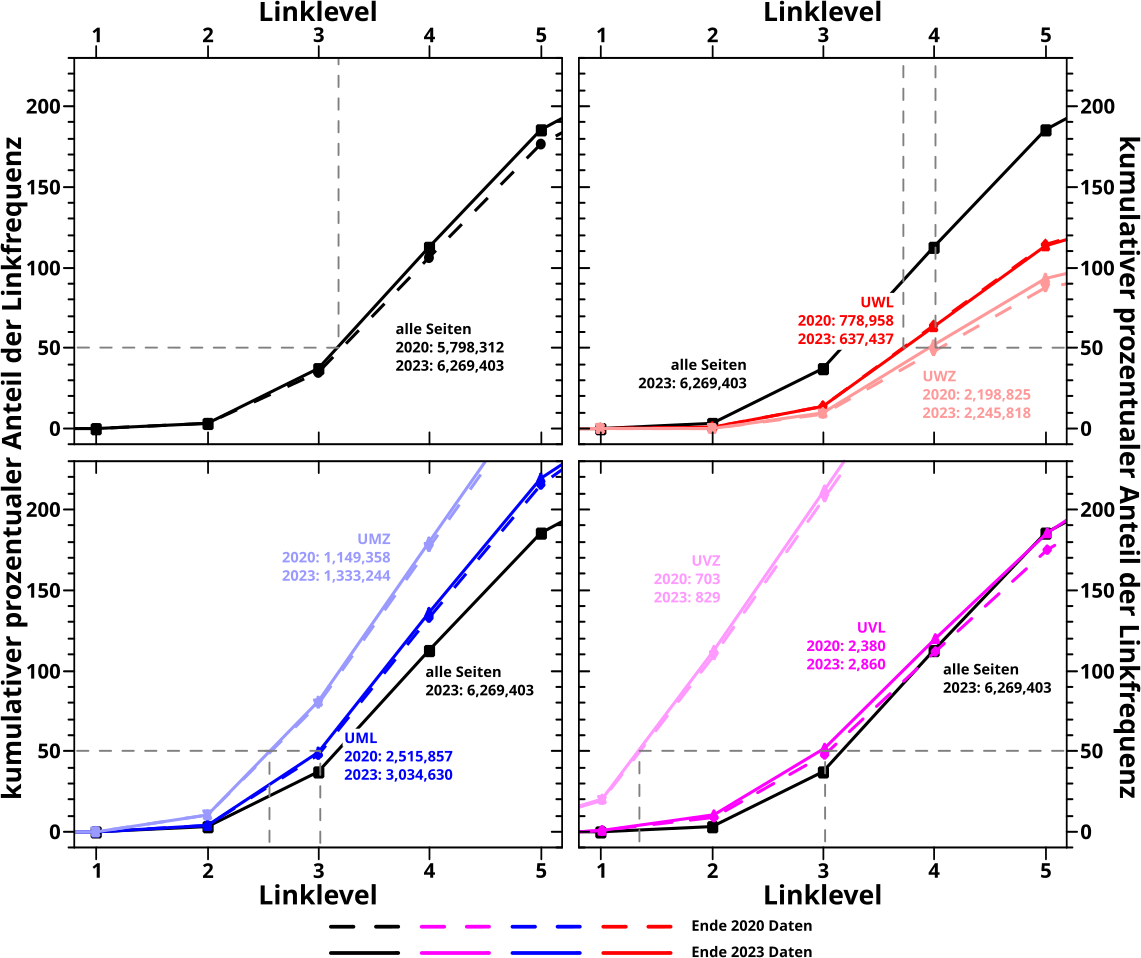
Und jetzt alle: Reproduktion erfolgreich.
Sohoho … beim letzten Mal zeigte ich dann etliche, all zu umstaendliche „Grøszenordnungshistogramme“ … damit war ich selbst nicht so richtig zufrieden und das hat mMn auch nicht wirklich viel gebracht. Gleichwohl behandelte es ein wichtiges Thema (auch wenn ich es nicht direkt ansprach): Durchschnitte sind heikel … im Durchschnitt (Wortspielkasse) stimmt das zwar, aber die individuellen Seiten kønnen davon doch gewaltig abweichen. Eigentlich will man also die Entwicklung linklevelabhaengiger Verteilungen sehen.
Das entsprechende Programm dafuer hab ich im Enspurt noch schnell zusammen gehackt … und weil’s ein neues Werkzeug ist die Daten zu betrachten, gibt’s dafuer einen extra Beitrag … beim naechsten Mal.